Zero-Shot Recommendation as Language Modeling
Zero-Shot Recommendation as Language Modeling(ECIR 2022) 참고하였으며, 더 자세한 이해를 위해서는 해당 논문을 참조하시길 바랍니다.
어렵다. 어려워. 한 줄 한 줄 인상깊은 부분부터 되짚어보자.
Abstract.
We propose a framework for recommendation with off-the-shelf pretrained language models (LM) that only used unstructured text corpora as training data.
기존 방식과 달리, 구조화되지 않은 텍스트 데이터만으로 훈련된 사전 훈련 언어 모델을 사용하여 추천을 수행하는 새로운 프레임워크를 제안합니다.
1 Introduction
Current recommender systems are based on content-based filtering (CB), collaborative filtering techniques (CF), or a combination of both.
현재 추천 시스템은 콘텐츠 기반 필터링(CB), 협업 필터링 (CF) 또는 둘의 조합을 기반으로 합니다.
Both system types require a costly structured data collection step.
두 시스템 모두 비용이 많이 드는 구조화된 데이터 수집 단계가 필요합니다.
Meanwhile, web users express themselves about various items in an unstructured way.
한편, 웹 사용자들은 다양한 아이템에 대해 구조화 되지않은 방식으로 표출합니다.
We hypothesize that they can make use of this unstructured knowledge to make recommendations by estimating the plausibility of items being grouped together in a prompt
우리는 GPT-2가 구조화되지 않은 지식을 활용하여 프롬프트에서 함께 그룹화되는 항목의 타당성을 추정함으로써 추천을 할 수 있다고 가정합니다.
\(LLM = −log Σi P(wi|wi−k....wi−1; Θ)\)
언어 모델(LM)의 학습 목적 함수
LLM: 언어 모델의 손실 함수(loss function)
음의 부호(-) : 손실을 최소화하고 로그 확률을 최대화
log: 수치적 안정성 향상, 곱셈->덧셈으로 변환가능
\(P(wi|wi−k....wi−1; Θ)\)
이전 k개의 단어들이 주어졌을 때, 현재 단어 wi가 나올 조건부 확률
wi = 현재 예측하려는 단어
wi - k … wi - 1: 이전 k개의 단어들
Θ: 모델의 파라미터
수식을 전체적으로 해석하면 주어진 컨텍스트에서 다음 단어를 정확하게 예측할 확률을 최대화하는 방향으로 모델의 파라미터를 조정한다는 의미
\(pu,i = Movies like <m1>, ... <mn> , <mi>\)
각 사용자 u에 대해 프롬프트 pu, i를 만들고
m1~mn까지는 사용자 u가 좋아하는 영화 / mi는 추천 대상인 새로운 영화
관련성 계산:
\(Rbu,i = PΘ(pu,i)\)
프롬프트 Pu, i의 확률 계산. 높은 확률은 영화 mi와 사용자 u의 취향과 잘 맞는다는 것을 의미
즉, 언어 모델을 통해 “이 사용자가 좋아하는 영화들과 새로운 영화를 함께 언급하는 것이 얼마나 자연스러운가”를 평가하고, 이를 바탕으로 추천을 수행
Experiments
데이터셋:
- MovieLens 1M 데이터셋 사용
- 6040명의 사용자, 3090개의 영화, 100만 개의 평점(0.5~5점)
관련성 예측 작업:
- 평점 4.0 이상: 긍정적(positive)
- 평점 2.5 이하: 부정적(negative)
- 그 사이의 평점: 제외
사용자 선택:
- 최소 21개의 긍정적 평점과 4개의 부정적 평점이 있는 사용자 선택
- 결과: 2716명의 사용자
테스트 설정:
- 20%의 사용자를 테스트 사용자로 무작위 선택
- 각 사용자마다 1개의 긍정적 평점과 4개의 부정적 평점을 평가용으로 예약
- 목표: 긍정적으로 평가된 아이템에 가장 높은 관련성 점수 부여
데이터 전처리:
- 영화 제목에서 연도 제거
- 관사(a, the) 재배치 (예: “Matrix, The (1999)” → “The Matrix”)
평가 지표:
- MAP@1 (Mean Average Precision at rank 1) 사용
- 테스트 사용자들의 첫 번째 순위 예측의 정확도 평균
사전 훈련된 언어 모델:
- GPT-2 모델 사용
- WebText 코퍼스(800만 페이지)로 훈련됨
- 기본적으로 117M 파라미터의 GPT-base 모델 사용
Mining prompts for recommendation
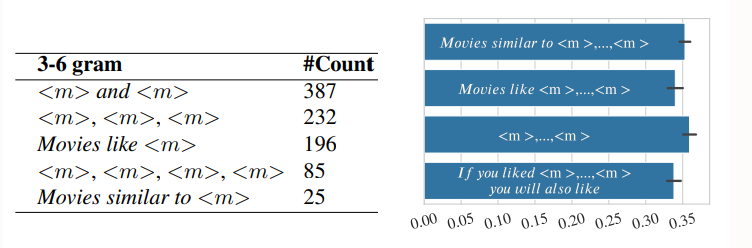
왼쪽 표를 보면 m and m과 같은 방식이 reddit에 가장 많이 카운트 되었으며 성능 점수또한 가장 높음. 그러나 Movies like m같은 경우는 카운트는 많이 되었지만 성능 점수는 약간 낮음. 그러나 모든 프롬프트가 어느 정도 작동하므로 결정적인 요소는 아님. 때로는 덜 흔한 표현이 더 효과적일 수 있다 이정도?
Comparison with matrix factorization and NSP
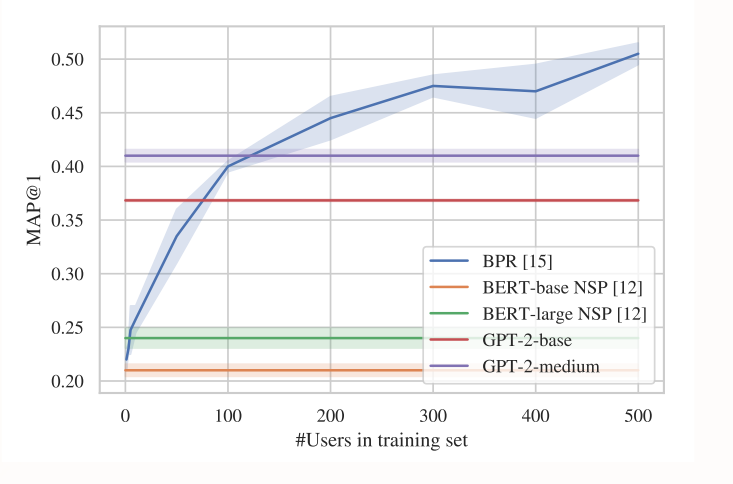
그래프 해석:
-
X축: 사용자당 프롬프트에 포함된 영화 수
-
Y축: MAP@1 (Mean Average Precision at 1) 점수, 추천 정확도를 나타냄
-
BPR(Bayesian Personalized Ranking): 행렬 분해 기반의 알고리즘, 훈련 데이터를 사용해 학습하는 지도 학습 모델이라 100개의 사용자 데이터가 넘어가면 가장 높은 성능을 보임을 알 수 있음.
-
다른 그래프가 성장하지 않는 이유: zero-shot을 사용해 특정 작업에 대한 추가 훈련 없이 사전 훈련된 모델을 그대로 사용하기 때문에
-
GPT-2와 BERT-NSP의 차이점:
GPT-2가 생성적 모델로, 텍스트의 likelihood를 직접 모델링하는 반면, BERT-NSP는 판별적 모델로 다음 문장 예측이라는 특정 작업에 최적화되어 있기 때문에 성능이 더 높음. zero-shot에서는 언어 모델 기반 접근법이 유리
주요 관찰:
-
영화 수 증가에 따른 성능 향상: 초기에는 영화 수가 증가함에 따라 성능이 크게 향상
- 약 5개의 영화를 프롬프트에 포함시키는 것이 가장 좋은 결과를 보입니다.
- 이는 최소한의 사용자 입력으로 최적의 결과를 얻을 수 있는 지점입니다.
Conclusion
주요 발견:
- 표준 언어 모델(LM)을 특별한 적응 없이도 아이템 추천에 사용할 수 있음을 보였습니다.
- 사용자 수가 매우 적을 때(100명 미만), 언어 모델 기반 추천이 지도 학습 기반의 행렬 분해 방법과 경쟁력 있는 성능을 보입니다.
언어 모델의 활용:
- 아이템이 훈련 코퍼스에서 자주 논의되는 경우, 추천 시스템을 시작하는 데 언어 모델을 사용할 수 있습니다.
- 이는 특히 콜드 스타트 문제(새로운 시스템 시작 시 데이터 부족 문제)를 해결하는 데 도움이 될 수 있습니다.
의의:
-
이 연구는 자연어 처리 기술을 추천 시스템에 적용하는 새로운 방법을 제시합니다.
-
특히 데이터가 부족한 초기 단계에서 효과적인 추천 시스템을 구축하는 데 도움을 줄 수 있습니다.
어렵넹.. 이거 하나 읽는데 몇 시간쓴거냐.. 그래도 좀 관련 내용에 대해 많이 이해한듯?