지하철, 금리 데이터 다루기
지하철 데이터 다루기
지하철은 위도, 경도 데이터 밖에 없다. 그래서 반경 내 갯수로 상관관계를 그려봤다. 오래 걸려서 1/100 샘플링으로 진행함. 모델링때만 원본데이터로 해야지.
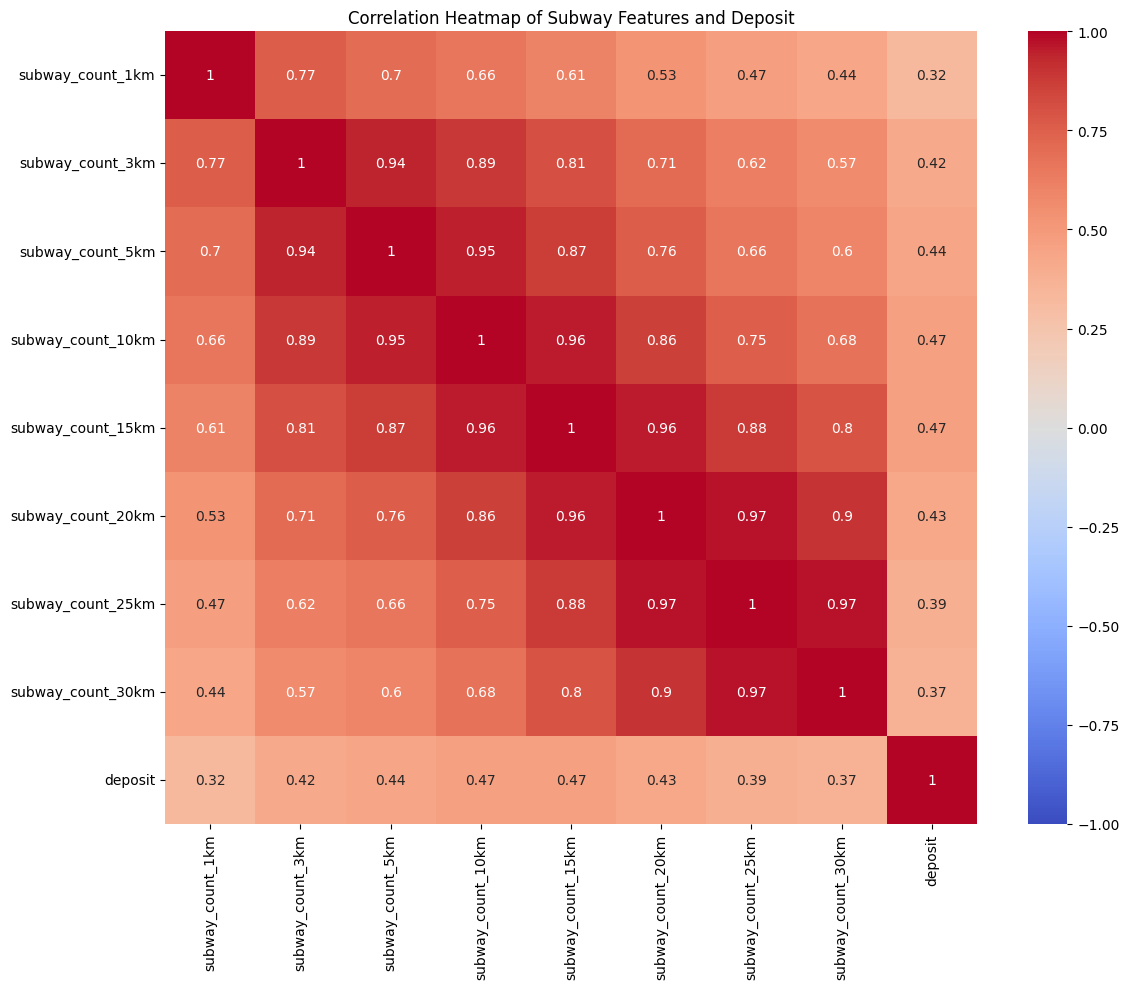
deposit과의 상관관계:
deposit 1.000000
subway_count_10km 0.458587
subway_count_15km 0.454826
subway_count_5km 0.432555
subway_count_20km 0.414162
subway_count_3km 0.414035
위의 상위 5개를 사용하는게 나을듯.
근데 생각해보니까 어차피 지하철은 집 앞에 하나만 있어도 그거 타고 다른데 갈 수 있어서
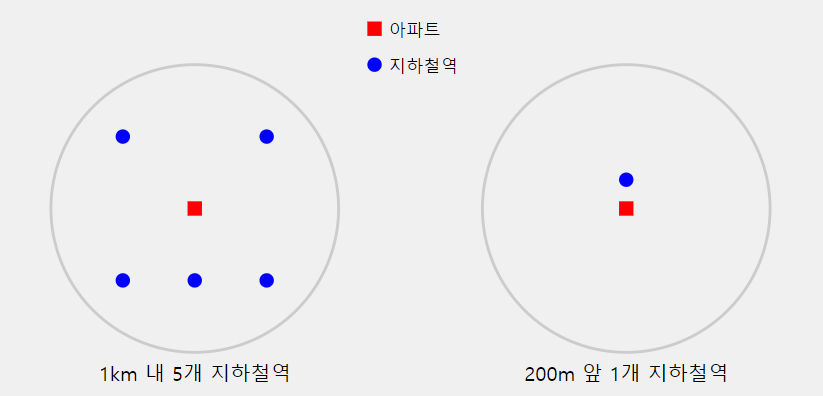
- 1km내외에 5개의 지하철이 있음
- 200m앞에 지하철역이 하나 있지만 1km내에 다른 지하철역은 없음
후자가 더 낫지 않으려나?
그래서 약간 feature를 다르게 줘서 다시 돌려봤다.
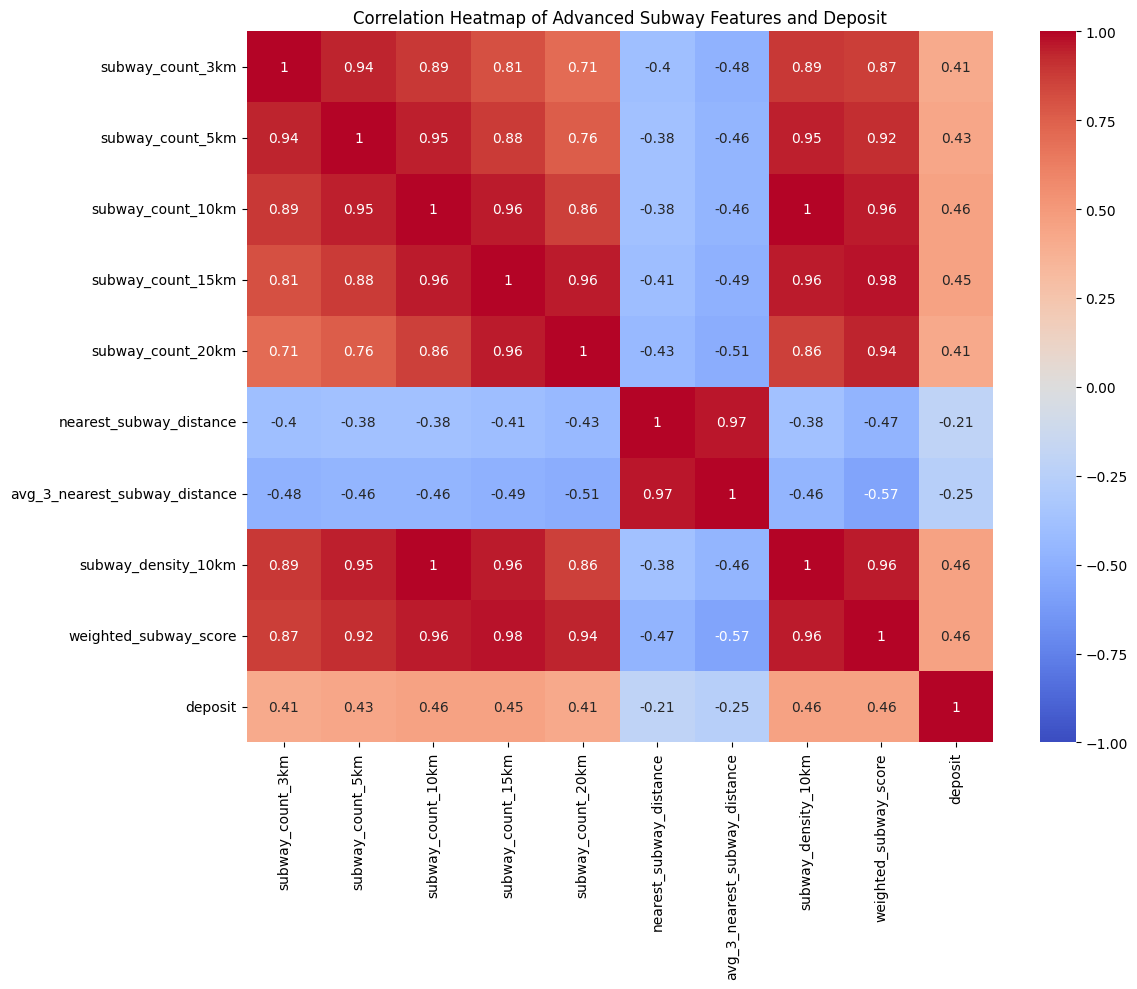
deposit과의 상관관계:
deposit 1.000000
weighted_subway_score 0.460537
subway_density_10km 0.458587
subway_count_10km 0.458587
subway_count_15km 0.454826
subway_count_5km 0.432555
subway_count_20km 0.414162
subway_count_3km 0.414035
nearest_subway_distance -0.210605
avg_3_nearest_subway_distance -0.250976
weighted_subway_score: 이 특성은 모든 지하철역의 영향을 고려하되, 거리에 따라 가중치를 다르게 주는 방식으로 계산됩니다.
계산 방법:
- 각 아파트에서 모든 지하철역까지의 거리를 계산합니다.
- 각 거리에 대해 1 / (1 + 거리)의 가중치를 적용합니다.
- 모든 가중치의 합을 구합니다.
특징:
- 가까운 지하철역에 더 높은 가중치를 줍니다.
- 먼 지하철역도 약간의 영향을 미칩니다.
- 전체적인 지하철 네트워크의 접근성을 하나의 숫자로 표현합니다.
예를 들어, 아파트 근처에 여러 개의 지하철역이 있으면 점수가 높아지고, 지하철역이 멀리 있거나 적으면 점수가 낮아집니다.
b. subway_density_10km: 이 특성은 10km 반경 내의 지하철역 밀도를 나타냅니다.
계산 방법:
- 10km 반경 내의 지하철역 수를 세어
subway_count_10km를 구합니다. - 이를 10km 반경의 원 면적 (π * 10^2)로 나눕니다.
가중치를 둔 피쳐들이 약간이나마 높게 나왔다. 그리고
nearest_subway_distanceavg_3_nearest_subway_distance
이 두개는 거리가 멀어질수록(커질수록) 전세가 싸져서 음의 상관관계를 보여서 양의 상관관계를 두가지로 나누어서 다시 보았다.
-
역수
inverse_avg_3_nearest_subway_distance 0.304184 inverse_nearest_subway_distance 0.184459
-
10km를 최대 거리로 설정하고 현재 거리를 뺀 값을 사용(가장 가까운 거리가 2km라면 이 값은 8이 댐)
proximity_avg_3_nearest_subway 0.266780 proximity_nearest_subway 0.222808
둘 다 값은 1개,3개의 지하철을 대변하는거라 그런가 낮았다.
지하철 마무리
weighted_subway_score 0.460537
subway_density_10km 0.458587
subway_count_10km 0.458587
subway_count_15km 0.454826
subway_count_5km 0.432555
이 정도 쓰면 댈듯
금리 데이터 다루기
이 데이터는 월별데이터와 금리만 나와있기에 지금까지 다룬것처럼은 못 다룰 것 같다.
금리와 집값을 시계열로 해서 봤다.
계약의 평균가격
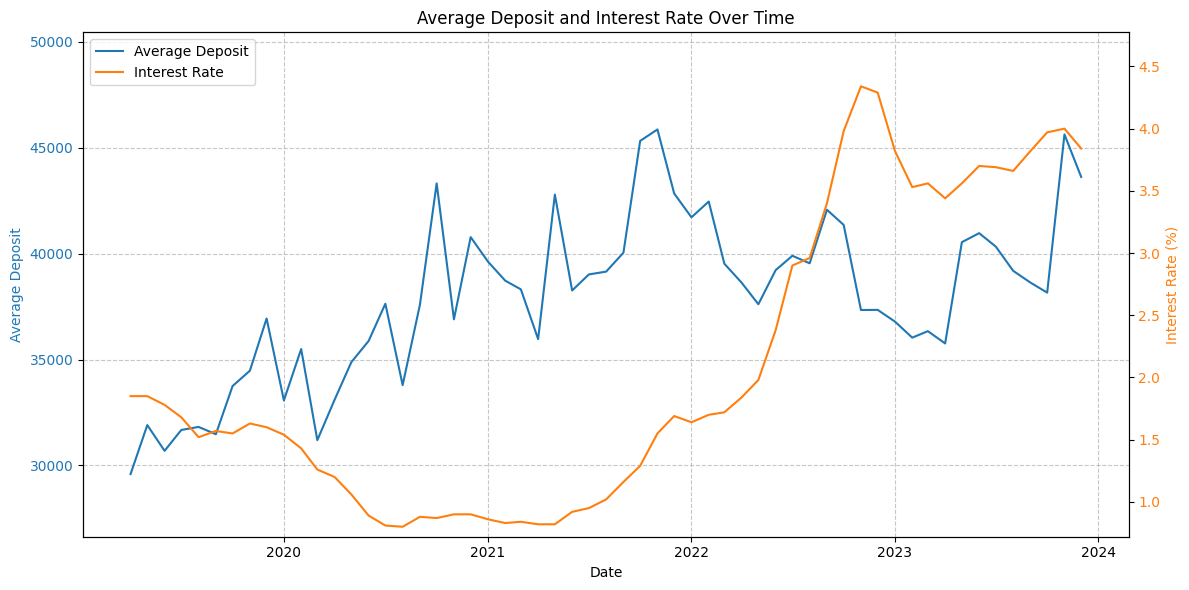
계약의 중앙값가격
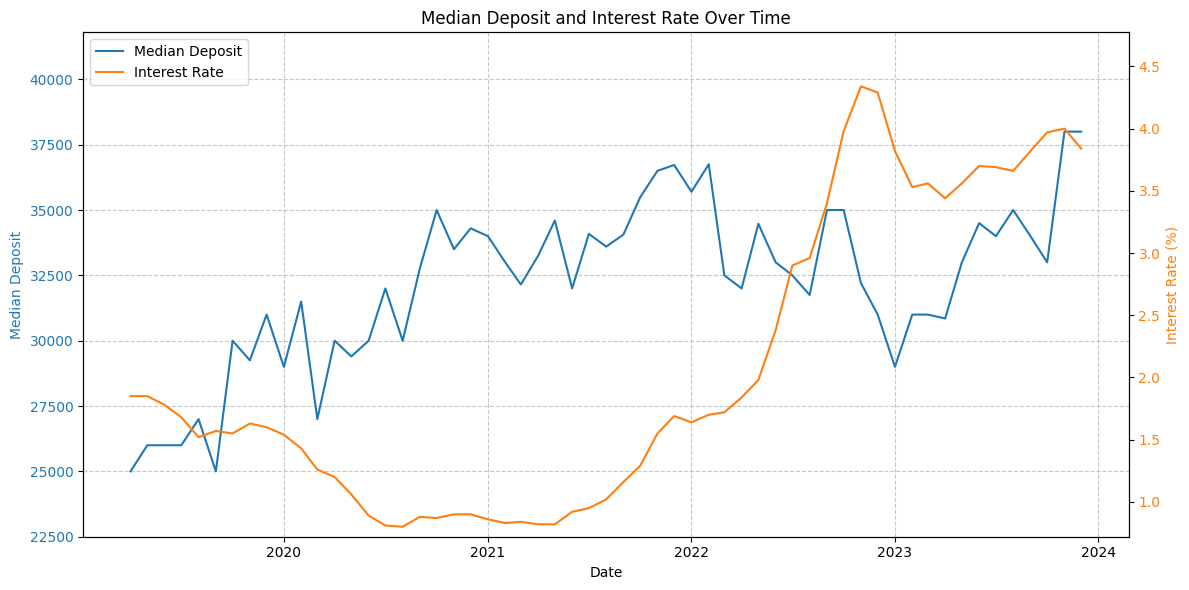
이거 하면서 느낀 건데 deposit의 이상치를 제거하고 가는게 낫지 않을까? 생각되었다.
그래서 우선 Deposit을 박스플롯, Scatter 플롯화하면
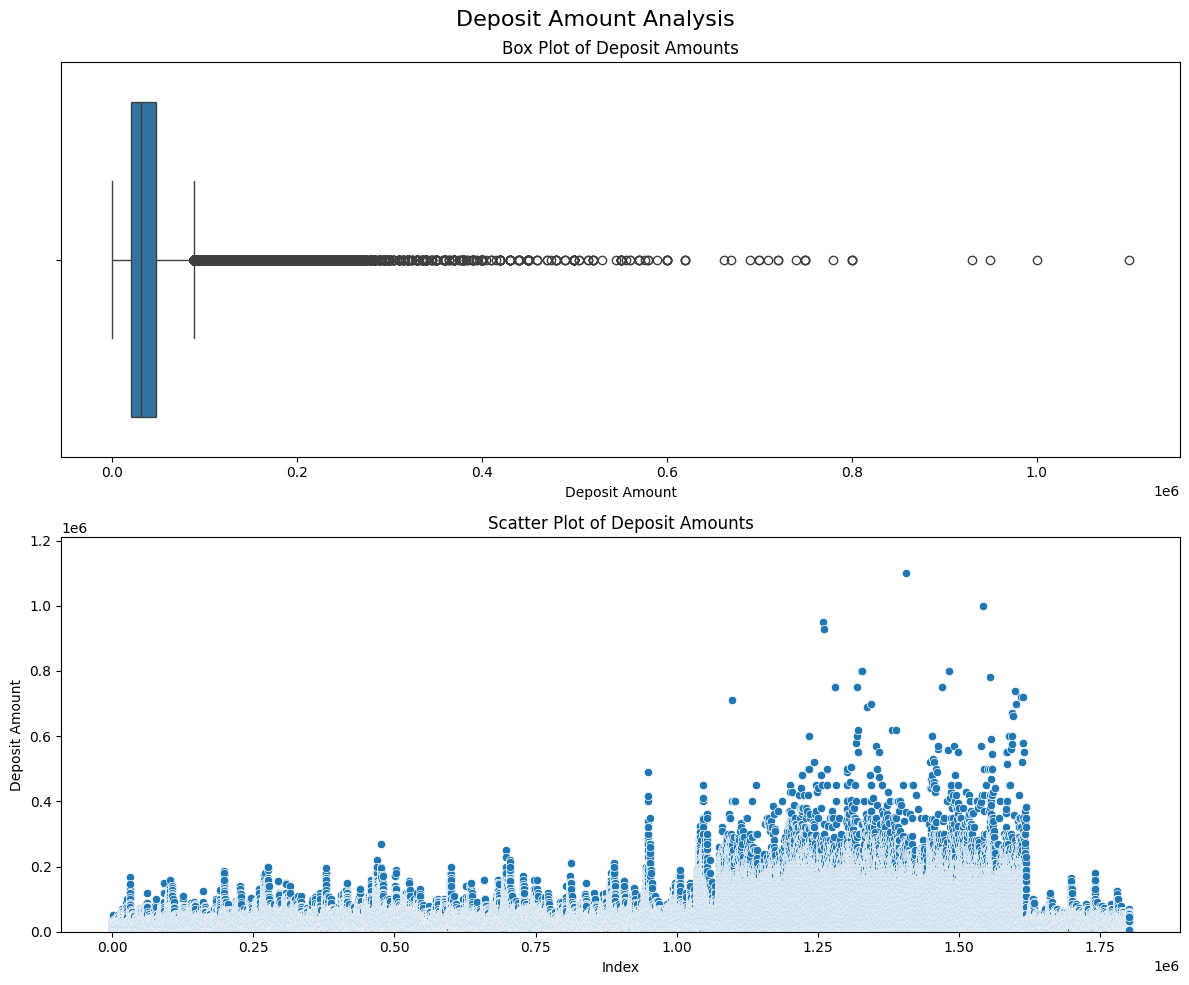
def remove_outliers_iqr(df, column):
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return df[(df[column] >= lower_bound) & (df[column] <= upper_bound)]
# 이상치 제거
df_clean = remove_outliers_iqr(df, 'deposit')
print(f"원본 데이터 크기: {len(df)}")
print(f"정제된 데이터 크기: {len(df_clean)}")
- 원본 데이터 크기: 1717611
- 정제된 데이터 크기: 1645615
생각해보면 이상치제거하는김에 할만한 열 다하는게 맞지 않나?
아 자꾸 생각안하고 해서 일 두번씩하는 기분이다.
deposit, area_m2, floor 3개의 열만 이상치 제거하였다.
df_clean2 = remove_outliers_iqr(df_clean, 'area_m2')
df_clean3 = df_clean2[(df_clean2['floor'] >= 0) & (df_clean2['floor'] < 100)]
- 원본 데이터 크기: 1556835
- 정제된 데이터 크기: 1556786
다시 하나하나 돌아보면.. 중복제거, 이상치제거 했고
Train 데이터 다루기
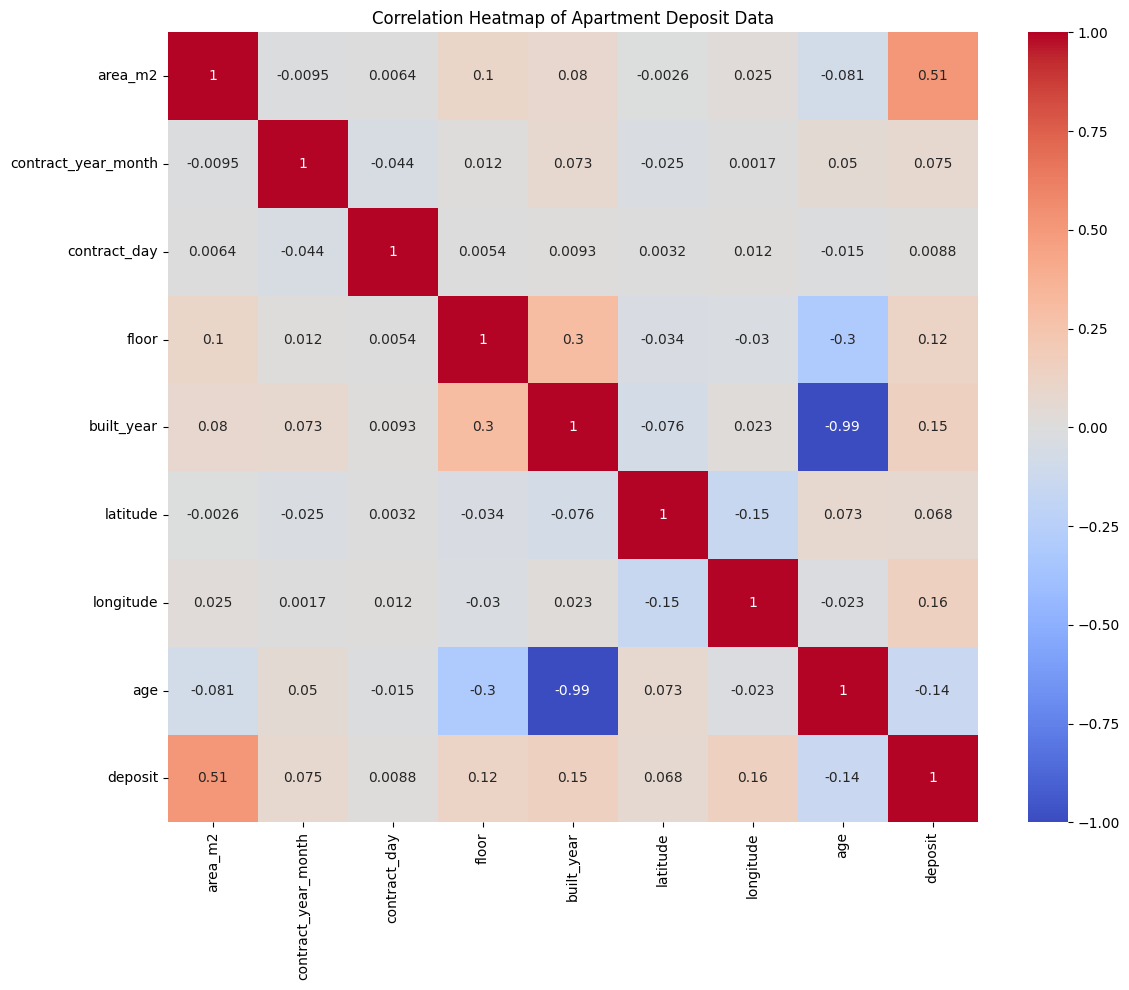
Correlation with deposit:
deposit 1.000000
area_m2 0.514380
longitude 0.155119
area_m2를 제외하면 거의 없다시피하다.
그래서
- area_floor_interaction: area_m2 * floor
- built_year_area_interaction: built_year * area_m2
두 개 추가했는데 이건 직접 곱한거라 더 나중에 걸리려나? 한번 나중에 중요도고르면서 생각해봐야지.
Correlation with deposit:
deposit 1.000000
built_year_area_interaction 0.515937
area_m2 0.514380
area_floor_interaction 0.308536
피쳐 엔지니어링 했고
할게
정규화? 클러스터링? 필요한가?
정규화/표준화가 필요한 특성:
- area_m2: 면적의 범위가 다양할 수 있으므로 정규화하면 좋습니다.
- age: 건물 나이의 범위가 넓을 수 있으므로 정규화하면 좋습니다.
- 저번에 다룬 공원, 학교데이터들의 반경 개수나 가까운 거리같은 데이터
정규화해서 한거 안한거 체크해서 누가 괜찮은가 함 봐보고
지리적 클러스터링:
- latitude와 longitude를 사용하여 지역을 클러스터링하고, 각 클러스터의 평균 deposit을 새로운 특성으로 사용할 수 있습니다.
얘도 좀 재밌을 거 같은데 한번 해보고