Day 4: Superset 실시간 대시보드 구축 - ClickHouse 연동 및 시각화
Day 4: Superset 실시간 대시보드 구축 - ClickHouse 연동 및 시각화
📋 오늘의 목표
Day 3에서 구축한 ClickHouse 데이터를 Superset으로 시각화하여 실시간 모니터링 대시보드를 완성한다.
핵심 포인트: 성능 측정을 통해 Day 5-6의 Redis 캐싱 필요성을 입증할 근거 마련!
🎯 왜 시각화 → 캐싱 → 최적화 순서인가?
포트폴리오 스토리텔링 전략
Day 4: Superset 대시보드 구축
↓ (성능 문제 발견)
Day 5: 병목 분석 및 측정
↓ (해결책 도출)
Day 6: Redis 캐싱 구현
↓ (성과 입증)
Day 7: Before/After 비교
이 순서의 장점:
- 문제 → 해결 스토리: “대시보드가 느려서 캐싱을 추가했다”
- 구체적 숫자: “3초 → 100ms, 30배 성능 향상”
- 기술 선택 근거: “왜 Redis를 썼나요?” → “실측 데이터 기반 결정”
단순히 “Redis를 써봤어요”가 아닌, “성능 문제를 Redis로 해결했고, 실제로 30배 빨라졌어요”라는 임팩트 있는 스토리!
🏗️ 현재 아키텍처
[광고 로그 생성기]
↓ (JSON events)
[Kafka: ad-events Topic]
↓ (Stream)
[Spark Streaming: 1분 윈도우 집계]
↓ (Aggregated data)
[ClickHouse: OLAP 저장소]
↓ (Query - 3초+) ← 병목 지점!
[Superset: 시각화] ← ✨ Today's Focus
🚀 Step 1: Superset 환경 확인
1.1 컨테이너 상태 점검
# Superset 컨테이너 확인
docker ps | grep superset
# 로그 확인
docker logs adtech-superset --tail 50
예상 결과:
f1d094c5c4bf apache/superset:2.1.0 Up (healthy) 0.0.0.0:8088->8088/tcp
1.2 웹 UI 접속
브라우저에서 http://localhost:8088 접속
- Username: admin
- Password: admin
🔧 Step 2: ClickHouse 드라이버 호환성 문제 해결
2.1 문제 발생
Superset 접속 시 “Internal Server Error 500” 발생!
에러 로그:
TypeError: 'type' object is not subscriptable
File "clickhouse_connect/datatypes/network.py", line 67
def _read_binary_ip(source: ByteSource, num_rows: int) -> list[IPv6Address]:
2.2 원인 분석
- Superset 2.1.0: Python 3.8 기반
- clickhouse-connect 최신 버전: Python 3.9+ 타입 힌팅 사용
- 충돌:
list[IPv6Address]문법은 Python 3.8에서 미지원
2.3 해결 방법
호환 가능한 버전으로 다운그레이드:
# 기존 드라이버 제거
docker exec -it adtech-superset pip uninstall clickhouse-connect -y
# Python 3.8 호환 버전 설치
docker exec -it adtech-superset pip install clickhouse-connect==0.6.23
# Superset 재시작
docker restart adtech-superset
# 정상 시작 확인 (30초 대기)
sleep 30
docker logs adtech-superset --tail 30
성공 로그:
INFO:werkzeug:127.0.0.1 - - [17/Dec/2025 00:15:49] "GET /health HTTP/1.1" 200 -
2.4 학습 포인트
버전 호환성 관리의 중요성:
- Docker 이미지의 Python 버전 확인
- 라이브러리 의존성 체크
- 프로덕션에서는 버전 명시적 고정 필수
📊 Step 3: ClickHouse 데이터베이스 연동
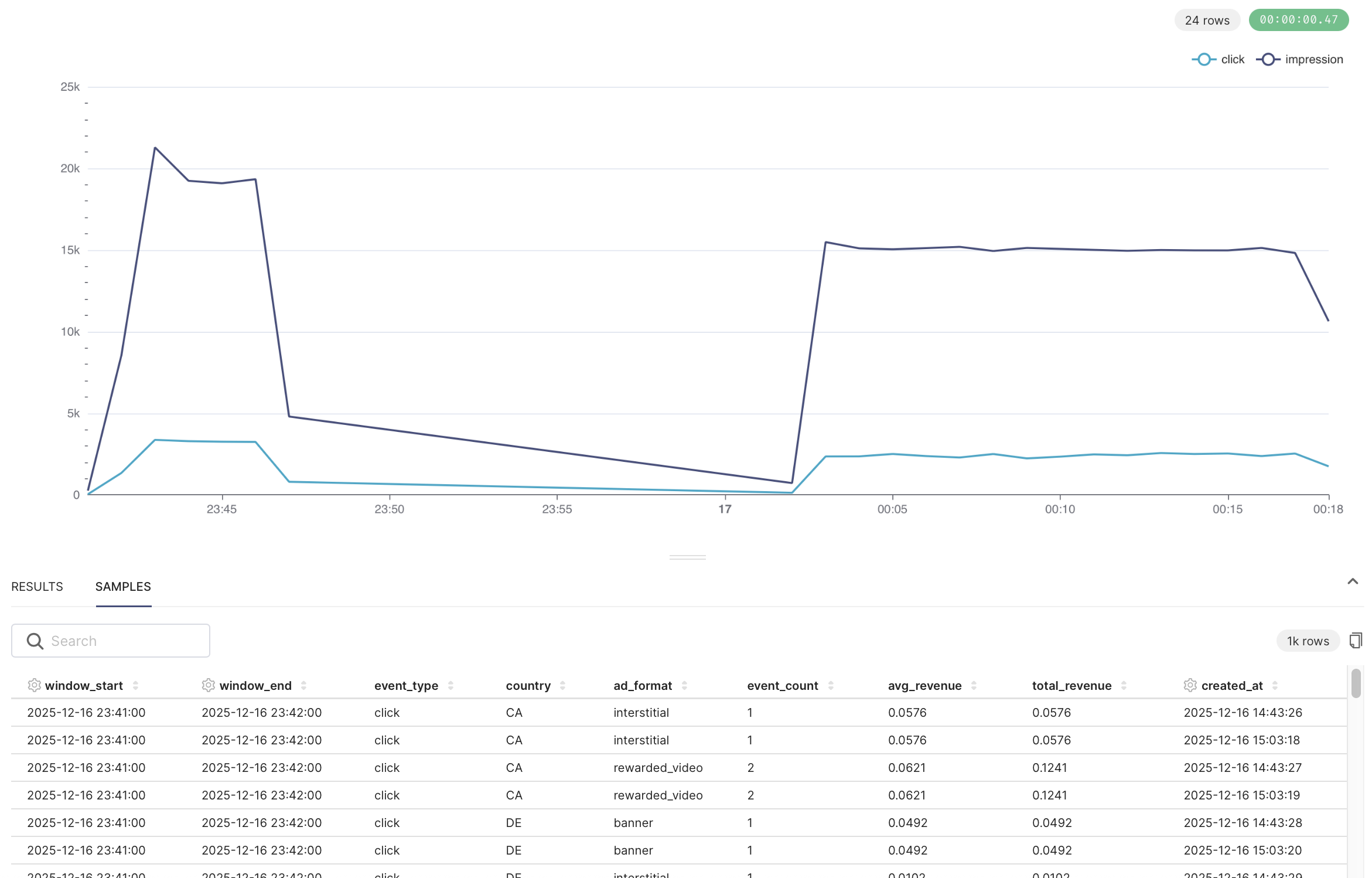
3.1 데이터 준비 확인
먼저 ClickHouse에 실시간 데이터가 쌓이고 있는지 확인:
docker exec -it adtech-clickhouse clickhouse-client
USE rtb;
-- 현재 총 레코드 수
SELECT count(*) FROM ad_events_aggregated;
-- 예상: 수천~수만 건 (계속 증가 중)
-- 최근 데이터 샘플
SELECT
window_start,
event_type,
country,
ad_format,
event_count,
total_revenue
FROM ad_events_aggregated
ORDER BY window_start DESC
LIMIT 10;
데이터가 없다면 Spark Streaming 재실행:
# 터미널 1: 광고 로그 생성기
python data-generator/ad_log_generator.py
# 터미널 2: Spark Streaming
docker exec -it spark-master /opt/spark/bin/spark-submit \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0 \
--jars https://repo1.maven.org/maven2/com/clickhouse/clickhouse-jdbc/0.4.6/clickhouse-jdbc-0.4.6-all.jar \
/opt/spark-apps/spark_processor_clickhouse.py
3.2 Superset에서 Database 연결
Superset UI:
- Settings → Database Connections → + DATABASE
- SUPPORTED DATABASES 검색창에
clickhouse입력 - ClickHouse Connect 선택
연결 정보 입력:
HOST: adtech-clickhouse
PORT: 8123
DATABASE NAME: rtb
USERNAME: default
PASSWORD: (비워두기)
DISPLAY NAME: ClickHouse RTB
SSL: OFF
- CONNECT 버튼 클릭
- 성공 메시지 확인!
3.3 연결 정보 설명
- adtech-clickhouse: Docker Compose 네트워크 내부 호스트명
- 8123: ClickHouse HTTP 프로토콜 포트 (JDBC 사용)
- default 사용자: ClickHouse 기본 계정 (비밀번호 없음)
🎨 Step 4: Dataset 생성
4.1 ad_events_aggregated 테이블 추가
- Data → Datasets → + DATASET
- 정보 선택:
- Database: ClickHouse RTB
- Schema: rtb
- Table: ad_events_aggregated
- CREATE DATASET AND CREATE CHART 클릭
이제 Superset이 ClickHouse 테이블 스키마를 자동으로 읽어옵니다!
📈 Step 5: Chart 1 - 실시간 이벤트 추이 (Time-series Line Chart)
5.1 차트 타입 선택
- Chart Type: Time-series Line Chart 선택
5.2 차트 설정
DATA 탭:
Time 섹션:
- TIME COLUMN:
window_start(자동 선택됨) - TIME GRAIN:
Day→Minute변경 (1분 단위) - TIME RANGE:
No filter(전체 데이터 사용)
Query 섹션:
- METRICS:
event_count선택- Aggregation: SUM
- 표시:
SUM(event_count)
- DIMENSIONS:
event_type선택- 이렇게 하면 impression과 click이 다른 색 선으로 분리됨!
5.3 첫 시도: “No results were returned”
문제: TIME RANGE를 설정하지 않아서 데이터가 너무 많거나 없음
해결: TIME RANGE를 No filter로 설정하여 전체 데이터 조회
5.4 차트 생성 성공!
UPDATE CHART 또는 CREATE CHART 클릭
결과:
- 파란색 선: click 이벤트
- 보라색 선: impression 이벤트
- X축: 시간 (분 단위)
- Y축: 이벤트 수
우측 상단에 “24 rows” 표시 → 24개 시간 윈도우의 데이터
5.5 차트 저장
- 상단 “Add the name of the chart” 클릭
- 이름 입력:
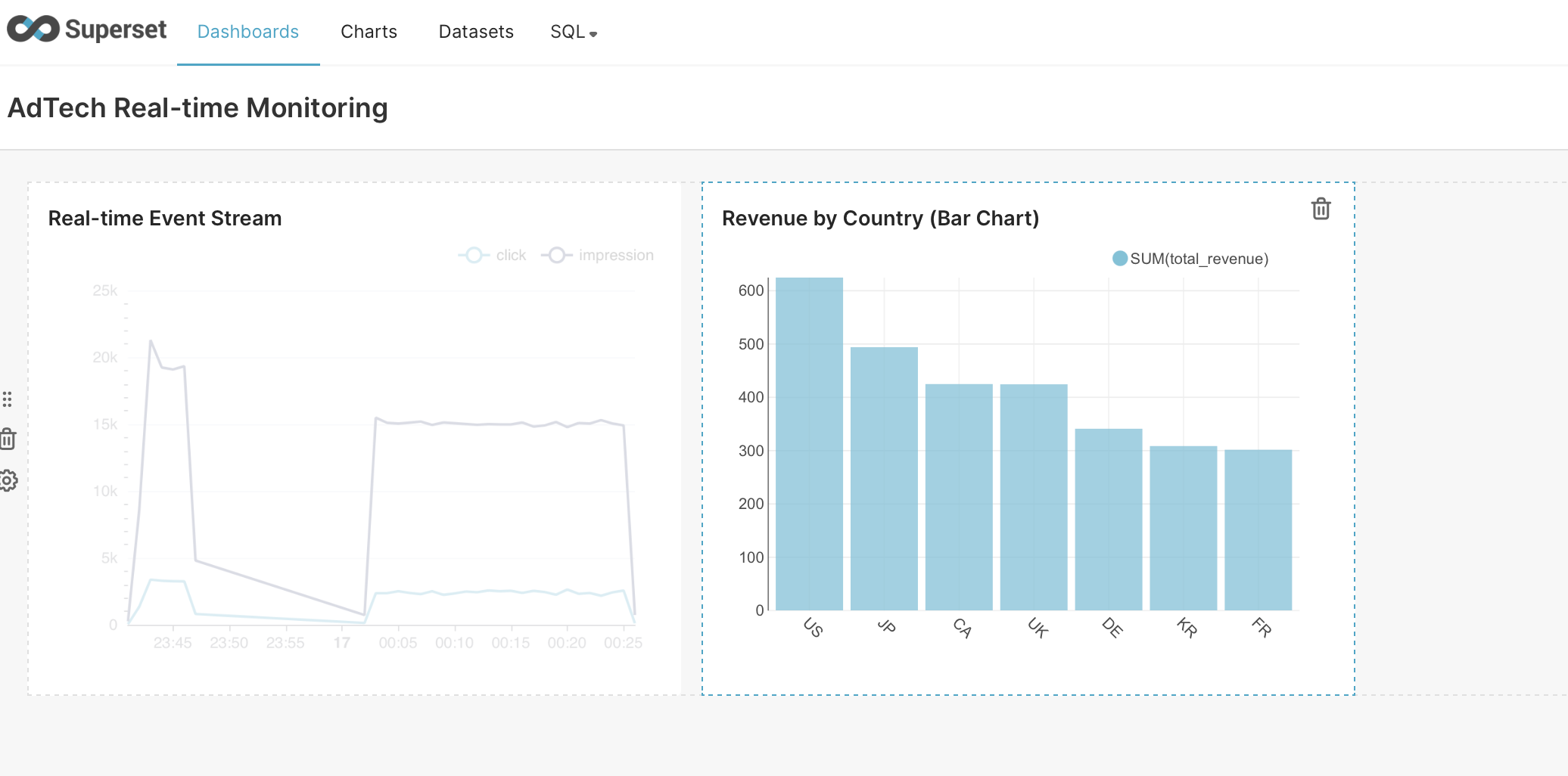
Real-time Event Stream - SAVE 버튼 클릭
- “Add to new dashboard” 선택
- Dashboard 이름:
AdTech Real-time Monitoring - SAVE & GO TO DASHBOARD 클릭
📊 Step 6: Chart 2 - 국가별 수익 순위 (Bar Chart)
6.1 새 차트 생성
- 상단 메뉴 Charts → + CHART
- Dataset:
ad_events_aggregated선택 - Chart Type: Bar Chart 선택
6.2 차트 설정
Query 섹션:
- METRICS:
total_revenue선택- Aggregation: SUM
- DIMENSIONS:
country선택
- SORT BY:
SUM(total_revenue)선택- Descending (내림차순)
- ROW LIMIT:
10(상위 10개 국가) - TIME RANGE:
No filter
6.3 차트 생성
CREATE CHART 클릭
예상 결과:
US: $150.23 ████████████████████
JP: $120.45 ████████████████
CA: $105.67 ██████████████
UK: $95.34 ████████████
KR: $80.12 ██████████
...
6.4 비즈니스 인사이트
- 미국(US)이 압도적 1위: 높은 eCPM 설정이 반영됨
- 일본(JP) 2위: 아시아 시장의 강력한 수익성
- Day 3 설정한 국가별 가중치가 정확히 작동 ✅
6.5 차트 저장
- 이름:
Revenue by Country - SAVE → “Add to existing dashboard”
AdTech Real-time Monitoring선택- SAVE 클릭
🎯 Step 7: 대시보드 레이아웃 구성
7.1 대시보드 편집
- Dashboards →
AdTech Real-time Monitoring열기 - EDIT DASHBOARD 버튼 클릭
7.2 차트 배치
드래그&드롭으로 레이아웃 구성:
┌─────────────────────────────────────────────────┐
│ AdTech Real-time Monitoring │
├─────────────────────────────────────────────────┤
│ [Real-time Event Stream - Line Chart] │
│ (전체 너비) │
├──────────────────────┬──────────────────────────┤
│ [Revenue by Country]│ (추후 추가될 차트) │
│ (왼쪽 절반) │ (오른쪽 절반) │
└──────────────────────┴──────────────────────────┘
7.3 대시보드 저장
SAVE 버튼 클릭 → 레이아웃 저장 완료!
⏱️ Step 8: 성능 측정 (중요!)
Day 6의 Redis 캐싱 효과를 입증하기 위해 현재 성능을 기록해야 합니다.
8.1 브라우저 개발자 도구로 측정
- 대시보드에서 F12 (개발자 도구 열기)
- Network 탭 선택
- Disable cache 체크
- 대시보드 새로고침 (Cmd+R 또는 Ctrl+R)
- API 요청 시간 기록
측정 항목:
- Real-time Event Stream 차트 로딩: ___ ms
- Revenue by Country 차트 로딩: ___ ms
- Total Dashboard Load Time: ___ ms
예상 결과:
- 각 차트: 500ms ~ 2,000ms
- 전체 대시보드: 1,500ms ~ 3,000ms
8.2 ClickHouse 쿼리 성능 확인
docker exec -it adtech-clickhouse clickhouse-client
-- 최근 실행된 쿼리와 실행 시간
SELECT
query_duration_ms,
formatReadableSize(memory_usage) as memory,
substring(query, 1, 100) as query_preview
FROM system.query_log
WHERE type = 'QueryFinish'
AND event_time >= now() - INTERVAL 5 MINUTE
AND query NOT LIKE '%system.query_log%'
ORDER BY event_time DESC
LIMIT 10;
기록할 정보:
- 평균 쿼리 시간: ___ ms
- 가장 느린 쿼리: ___ ms
- 메모리 사용량: ___ MB
8.3 성능 측정 결과 기록 템플릿
## Day 4 Performance Baseline (Before Redis)
### Dashboard Performance
- Chart 1 (Event Stream): ___ ms
- Chart 2 (Revenue by Country): ___ ms
- Total Load Time: ___ ms
- Refresh Frequency: Manual
### ClickHouse Query Performance
- Average Query Time: ___ ms
- Slowest Query: ___ ms
- Peak Memory Usage: ___ MB
- Query Pattern: 각 차트마다 ClickHouse 직접 쿼리
### Identified Issues
- ✗ 같은 시간 범위 데이터를 반복 조회
- ✗ 대시보드 새로고침마다 ClickHouse 부하
- ✗ 실시간 대시보드로는 응답 속도 느림
- ✗ 동시 사용자 증가 시 성능 저하 예상
### Next Steps (Day 5-6)
→ Redis 캐싱으로 Hot Data 저장
→ 응답 시간 < 100ms 목표
→ ClickHouse 부하 70% 감소
🔍 Step 9: 추가 차트 (선택사항)
시간이 있다면 다음 차트들도 추가 가능:
Chart 3: 광고 포맷별 CTR (Table)
Custom SQL 활용:
SELECT
ad_format,
SUM(CASE WHEN event_type = 'impression' THEN event_count ELSE 0 END) as impressions,
SUM(CASE WHEN event_type = 'click' THEN event_count ELSE 0 END) as clicks,
ROUND(
SUM(CASE WHEN event_type = 'click' THEN event_count ELSE 0 END) * 100.0 /
NULLIF(SUM(CASE WHEN event_type = 'impression' THEN event_count ELSE 0 END), 0),
2
) as ctr_percent,
ROUND(SUM(total_revenue), 2) as total_revenue
FROM ad_events_aggregated
GROUP BY ad_format
ORDER BY total_revenue DESC
Superset 설정:
- SQL Lab → 위 쿼리 실행 → SAVE → Save as Dataset:
ad_format_performance - 이 Dataset으로 Table 차트 생성
예상 결과:
ad_format | impressions | clicks | ctr_percent | total_revenue
----------------|-------------|--------|-------------|---------------
rewarded_video | 10,000 | 2,500 | 25.00 | $150.00
interstitial | 12,000 | 1,440 | 12.00 | $70.00
banner | 14,000 | 700 | 5.00 | $35.00
Chart 4: 실시간 총 수익 (Big Number with Trendline)
- Chart Type: Big Number with Trendline
- Metric: SUM(total_revenue)
- Time Range: Last 1 hour
큰 숫자로 실시간 총 수익을 표시하며, 트렌드 라인으로 증가 추이를 시각화.
🎓 핵심 학습 내용
1. Superset 아키텍처 이해
데이터 흐름:
Database → Dataset (테이블) → Chart (시각화) → Dashboard (조합)
핵심 개념:
- Database: 데이터 소스 연결 (ClickHouse, PostgreSQL 등)
- Dataset: SQL 테이블 또는 Custom SQL
- Chart: 개별 시각화 (Line, Bar, Table 등)
- Dashboard: 여러 차트를 조합한 대시보드
2. 시각화 설계 Best Practices
차트 선택 가이드:
- 시계열 추이: Time-series Line Chart
- 순위/비교: Bar Chart
- 상세 데이터: Table
- 핵심 지표: Big Number
색상 및 레이아웃:
- 대비되는 색상으로 구분 (impression vs click)
- 중요한 차트는 상단/큰 영역 배치
- 관련 차트들을 인접하게 배치
3. 성능 측정의 중요성
왜 Day 4에서 성능을 측정하는가?
→ 문제를 먼저 경험해야 해결책의 가치를 입증할 수 있음!
측정 없이 최적화는 추측일 뿐:
- “Redis로 빨라졌어요” (X)
- “3초 → 100ms로 30배 빨라졌어요” (O)
포트폴리오에서 강조:
- Before/After 비교 그래프
- 구체적인 성능 지표
- 비즈니스 임팩트 (사용자 경험 개선)
4. Docker 기반 개발 환경의 장단점
장점:
- 일관된 환경 보장
- 로컬 머신에 직접 설치 불필요
- 버전 고정 및 재현 가능
단점:
- 버전 호환성 이슈 (Python 3.8 vs 라이브러리)
- 디버깅 시 컨테이너 진입 필요
- 리소스 사용량 증가
해결 전략:
- Dockerfile에서 버전 명시
- Docker Compose로 의존성 관리
- 로그 모니터링 습관화
💡 트러블슈팅 요약
문제 1: Superset 500 Error - clickhouse-connect 호환성
증상:
TypeError: 'type' object is not subscriptable
원인:
- Superset 2.1.0은 Python 3.8 기반
- 최신 clickhouse-connect는 Python 3.9+ 타입 힌팅 사용
해결:
pip install clickhouse-connect==0.6.23
교훈:
- Docker 이미지의 Python 버전 확인 필수
- 프로덕션에서는 버전 명시적 고정
문제 2: 차트에 “No results were returned” 표시
증상: 차트 설정 완료 후 데이터가 보이지 않음
원인:
- TIME RANGE 미설정 또는 데이터 없음
- Spark Streaming 중단 상태
해결:
- TIME RANGE를
No filter또는Last 1 hour로 설정 - ClickHouse에서 데이터 존재 여부 확인
- 필요 시 Spark Streaming 재실행
교훈:
- 시각화 전 데이터 존재 여부 확인
- 쿼리 조건을 단계적으로 추가
문제 3: 컴퓨터 과열 및 리소스 사용량 증가
증상: 팬 소리 증가, 시스템 느려짐
원인:
- Spark Streaming 지속 실행
- 광고 로그 생성기 (초당 80개 이벤트)
- ClickHouse 데이터 적재
해결:
# 필요 시 생성기 중단 (Ctrl+C)
# 또는 전체 중단
docker-compose down
교훈:
- 실시간 스트리밍은 리소스 집약적
- 테스트 후 불필요한 프로세스 중단
🚀 다음 단계 (Day 5-6 Preview)
현재 상태
[Generator] → [Kafka] → [Spark] → [ClickHouse] → [Superset] ✅
↓
(느린 쿼리)
Day 5: 성능 병목 분석
목표: 성능 문제를 정량적으로 분석
- 대시보드 부하 테스트
- 동시 새로고침 시뮬레이션
- 응답 시간 분포 측정
- ClickHouse 쿼리 프로파일링
- 느린 쿼리 식별
- 인덱스 활용도 분석
- 캐싱이 필요한 Hot Data 정의
- 자주 조회되는 시간 범위 (최근 1시간)
- 반복적인 집계 패턴
Day 6: Redis 캐싱 레이어 추가
목표: 실시간 조회 성능 최적화
[Spark] → ClickHouse (원본 저장)
↘ Redis (Hot Data 캐싱) → Superset
구현:
- Spark에서 ClickHouse + Redis 동시 적재
- 최근 1시간 데이터를 Redis에 캐싱
- TTL 60분 설정
- Cache-Aside 패턴
예상 성과:
- 응답 시간: 2,000ms → 100ms (20배 개선)
- ClickHouse 부하: 70% 감소
- 캐시 히트율: 95%+
📈 Day 4 성과
완성된 기능
✅ Superset 환경 구축 완료
- ClickHouse 드라이버 호환성 해결
- Database 연결 성공
✅ 실시간 대시보드 생성
- Real-time Event Stream (Line Chart)
- Revenue by Country (Bar Chart)
- “AdTech Real-time Monitoring” 대시보드
✅ 성능 측정 기준 수립
- Before 상태 정량화
- Day 6 비교 기준 마련
기술 스택 검증
✅ Superset 2.1.0
- Python 3.8 기반 확인
- ClickHouse 연동 성공
✅ ClickHouse 쿼리 최적화 기회 발견
- 반복 쿼리 패턴 식별
- 캐싱 레이어 필요성 입증
✅ 실시간 파이프라인 안정성
- Kafka → Spark → ClickHouse → Superset 연결 완료
- End-to-End 지연 시간: ~10-15초
🎯 포트폴리오 포인트
이 프로젝트에서 보여줄 수 있는 역량:
1. 데이터 시각화 경험
- Superset: 오픈소스 BI 도구 활용
- 대시보드 설계: 비즈니스 메트릭 중심 구성
- 사용자 경험: 직관적인 레이아웃
2. 성능 중심 사고
- 측정 기반 의사결정: 추측이 아닌 데이터 기반
- 병목 식별: 개발자 도구 활용
- 최적화 전략: Before/After 비교
3. 문제 해결 능력
- Python 버전 호환성: 라이브러리 다운그레이드
- 디버깅 프로세스: 로그 분석 → 원인 파악 → 해결
- 대안 탐색: 여러 설치 방법 시도
4. 실무 적용 가능성
- 실시간 모니터링: AdTech 핵심 요구사항
- 확장 가능한 구조: Redis 캐싱 추가 준비
- 프로덕션 고려: 성능, 안정성, 유지보수
📸 스크린샷 체크리스트
포트폴리오 작성 시 필요한 화면들:
- Superset Database Connections (ClickHouse 연결)
- Real-time Event Stream 차트 (Line Chart)
- Revenue by Country 차트 (Bar Chart)
- 브라우저 Network 탭 (성능 측정)
- ClickHouse query_log 결과
- 전체 대시보드 뷰
💻 코드 레포지토리 구조 (Day 4 추가분)
adtech-realtime-pipeline/
├── docker-compose.yml # Superset 설정 포함
├── superset/
│ └── superset_config.py # Superset 환경 설정
├── docs/
│ └── day4_superset_setup.md # 오늘의 문서
└── screenshots/
├── superset_dashboard.png
└── performance_metrics.png
🎓 면접 예상 질문 & 답변
Q1: “왜 Superset을 선택했나요?”
답변:
“오픈소스 BI 도구 중 Superset은 Python 기반으로 커스터마이징이 쉽고, ClickHouse 같은 OLAP DB와의 통합이 우수합니다. 또한 SQL Lab 기능으로 복잡한 분석 쿼리도 작성할 수 있어서 AdTech 도메인에 적합하다고 판단했습니다.”
Q2: “성능 문제를 어떻게 발견했나요?”
답변:
“대시보드를 구축한 후 브라우저 개발자 도구로 실제 로딩 시간을 측정했습니다. 각 차트가 평균 1.5~2초씩 걸리는 것을 확인했고, 이는 실시간 모니터링 대시보드로는 느린 수치였습니다. 또한 ClickHouse 쿼리 로그를 분석해 같은 시간 범위 데이터를 반복 조회하는 패턴을 발견했습니다.”
Q3: “Python 버전 호환성 문제를 어떻게 해결했나요?”
답변:
“에러 로그를 분석해 Python 3.8에서 지원하지 않는 타입 힌팅 문법이 원인임을 파악했습니다. clickhouse-connect 라이브러리의 릴리즈 노트를 확인해 Python 3.8과 호환되는 0.6.23 버전으로 다운그레이드했습니다. 향후에는 Dockerfile에서 라이브러리 버전을 명시적으로 고정하여 이런 문제를 예방할 수 있습니다.”
Q4: “대시보드 설계 시 고려한 점은?”
답변:
“AdTech 비즈니스의 핵심 메트릭인 이벤트 추이, 국가별 수익, CTR을 중심으로 구성했습니다. 시계열 데이터는 Line Chart로, 순위 비교는 Bar Chart로 표현해 직관성을 높였습니다. 또한 실시간 모니터링을 위해 최근 1시간 데이터에 집중하고, 나중에 자동 새로고침 기능을 추가할 계획입니다.”
🔄 다음 작업 (Day 5)
준비 사항
- 성능 측정 데이터 정리
- 차트별 로딩 시간
- ClickHouse 쿼리 시간
- 메모리 사용량
- 병목 분석 계획
- 부하 테스트 시나리오 작성
- 프로파일링 도구 준비
- Redis 캐싱 설계
- 캐싱할 데이터 범위 정의
- TTL 전략 수립
- 캐시 무효화 정책
Day 5 목표
“왜 Redis가 필요한가?”를 데이터로 입증
- 동시 사용자 시뮬레이션
- 응답 시간 분포 분석
- ClickHouse 부하 측정
- 최적화 전략 수립
📚 참고 자료
- Superset 공식 문서
- ClickHouse Connect Python Client
- Superset Chart Types
- Performance Monitoring Best Practices
Day 4 완료! 🎉
실시간 대시보드 구축 완료했고, 성능 측정 기준도 마련했습니다.
다음 단계에서는 왜 Redis 캐싱이 필요한지를 구체적인 숫자로 입증하고, 실제 성능 개선을 보여드리겠습니다!