프로젝트 데이터 전처리
실습이나 과제에서 다양한 예제들을 연습해보았으니 걔네들을 따라서 실제 프로젝트에 적용해봅시다.
Library Import, Data Load (생략)
df.csv (11552 rows × 255 columns)
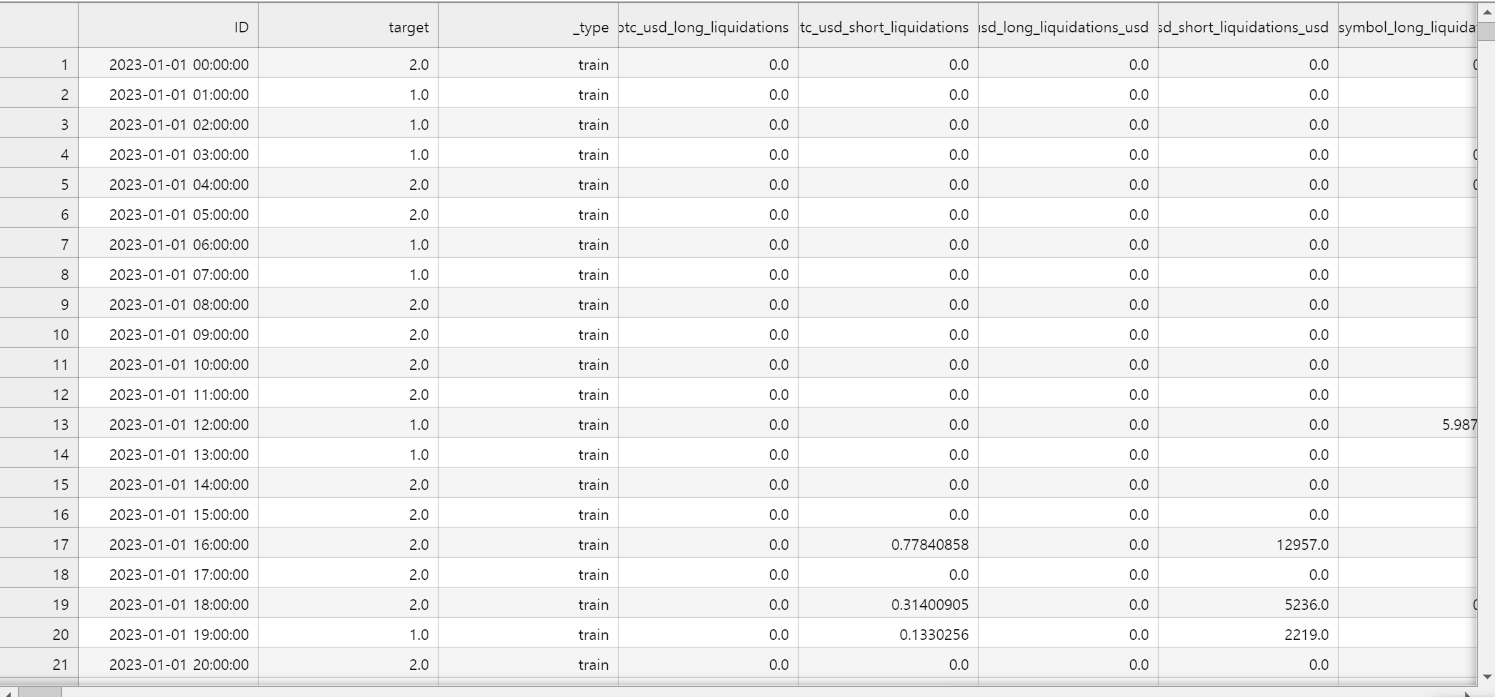
데이터 전처리
결측치 처리
뭐부터 할까 하다가 데이터 결측치부터 확인해보기로 했음
eda_df = df.loc[df["_type"] == "train"]
# 각 열에서 누락된 값의 수를 계산
missing_values = eda_df.isnull().sum()
# 누락된 값의 백분율 계산
missing_percentage = (missing_values / len(eda_df)) * 100
# 누락된 값 비율을 기준으로 열 정렬
sorted_missing_percentage = missing_percentage.sort_values(ascending=False)
sorted_missing_percentage
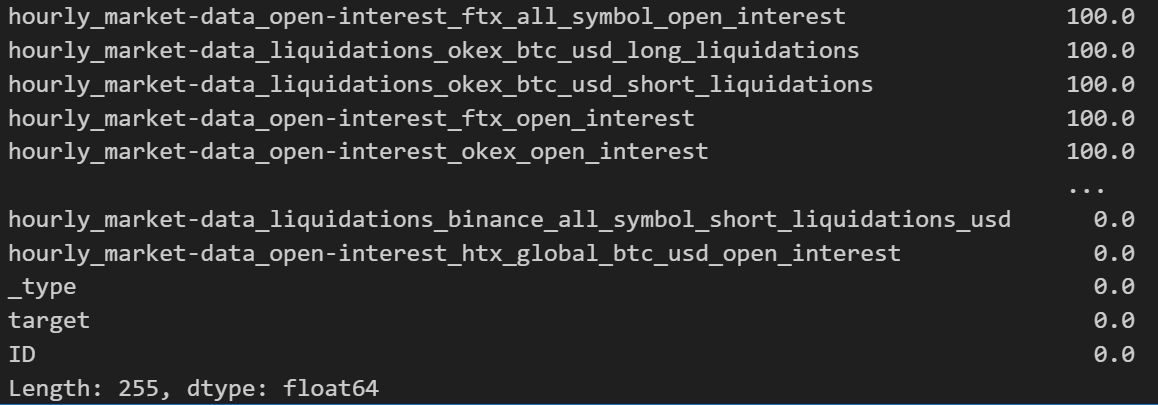
확인해보니 결측치가 100%인 데이터들이 많이 보였음.
직접 까서 확인해보니 type이 train,test까지 되어있는게 2023-01-01부터 2024-04-26 07:00:00까지 되어있는데 100%누락되있는 컬럼들은 보통 이 기간보다 이전의 데이터들만 존재해서 데이터프레임화 하면서 null값으로 보이는 거였음
그래서 우선 보이는 100%인 컬럼들은 제거하기로 함. 그리고 다시 확인한다음 결측치를 중간값으로 채우던 임의의 값으로 채우던 하기로 함.
# null 값이 100%가 아닌 컬럼만 선택
columns_to_keep = sorted_missing_percentage[sorted_missing_percentage < 100].index
# eda_df_cleaned = train만 되어있고 null 100% 제거된 df
# 원래 DataFrame의 컬럼 순서를 유지하면서 선택된 컬럼만 포함
eda_df_cleaned = eda_df[eda_df.columns.intersection(columns_to_keep)]
# 결과 확인
print(f"Original shape: {eda_df.shape}")
print(f"New shape: {eda_df_cleaned.shape}")
Original shape: (8760, 255)
New shape: (8760, 215)
100% 결측치인 40개의 컬럼이 제거댐.
그 다음 확인해봄. 남은 거 뭐 남았나.
# 결측치가 있는 열만 선택 (결측치 비율이 0보다 큰 열)
columns_with_missing = sorted_missing_percentage[sorted_missing_percentage > 0]
# 결측치가 있는 열의 개수
num_columns_with_missing = len(columns_with_missing)
print(f"결측치가 있는 열의 개수: {num_columns_with_missing}")
# 결측치가 있는 열들과 그 결측치 비율 출력
print("\n결측치가 있는 열들과 결측치 비율:")
print(columns_with_missing)
# 결측치 비율 구간별 열 개수 확인
print("\n결측치 비율 구간별 열 개수:")
print("0-1% 미만:", sum((0 < sorted_missing_percentage) & (sorted_missing_percentage < 1)))
print("1-5% 미만:", sum((1 <= sorted_missing_percentage) & (sorted_missing_percentage < 5)))
print("5-10% 미만:", sum((5 <= sorted_missing_percentage) & (sorted_missing_percentage < 10)))
print("10% 이상:", sum(sorted_missing_percentage >= 10))

이렇게 나왔네. 이정도면 제거하긴 아깝고 채우는 방식으로 해야겠다.
군데 군데 비어있으면 ffill 쓸겸 한번 데이터 확인도 해볼겸 뜯어봐야지.
# null 값이 있는 행의 인덱스를 찾는 함수
def find_null_rows(df, column):
null_rows = df[df[column].isnull()].index
return null_rows
# 모든 열에 대해 null 값이 있는 행의 인덱스 찾기
null_rows_dict = {}
for column in eda_df_cleaned.columns:
null_rows = find_null_rows(eda_df_cleaned, column)
if len(null_rows) > 0:
null_rows_dict[column] = null_rows
# 결과 출력
for column, rows in null_rows_dict.items():
print(f"\n{column}:")
print(f"Null 값이 있는 행 인덱스: {rows}")
print(f"Null 값의 개수: {len(rows)}")
# 모든 null 값의 위치를 한 번에 확인
all_null_positions = eda_df_cleaned.isnull()
print("\n모든 null 값의 위치:")
print(all_null_positions.sum())
# 특정 기간의 null 값 확인
start_date = '2023-12-28'
end_date = '2023-12-31'
null_in_period = eda_df_cleaned.loc[start_date:end_date].isnull().sum()
print(f"\n{start_date}부터 {end_date}까지의 null 값 개수:")
print(null_in_period)

2023-01-12 20:00:00 row 데이터가 좀 많이 비어있는데 뭐지? 뭔 일 있었나?
바이낸스 켜서 2023-01-12일 확인해봣는데 별거없는데 뭐지..?
걍 ffill해버릴까? 아니면 걍 row 하나 지워버려도 되나? 우선 보류
또 확인해보니 귀찮게 청산쪽 데이터들이 구멍이 몇개 뚫려있다. 얘네를 어케 처리할까.. 우선 드는 생각은 다른 거래소 청산 평균 값으로 대체하는 거가 가장 나을 것 같음.
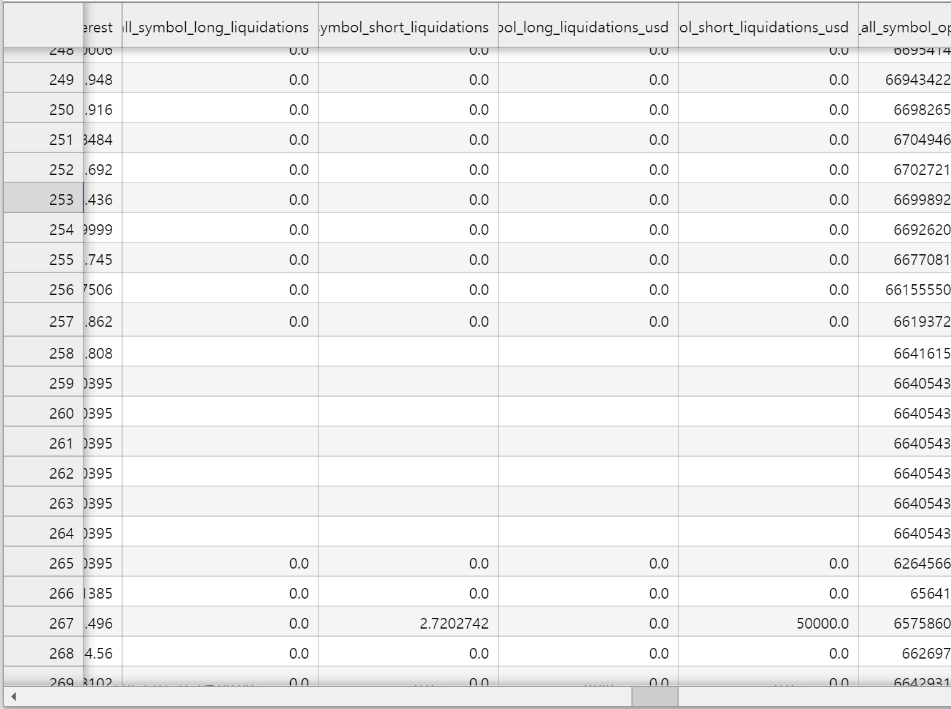
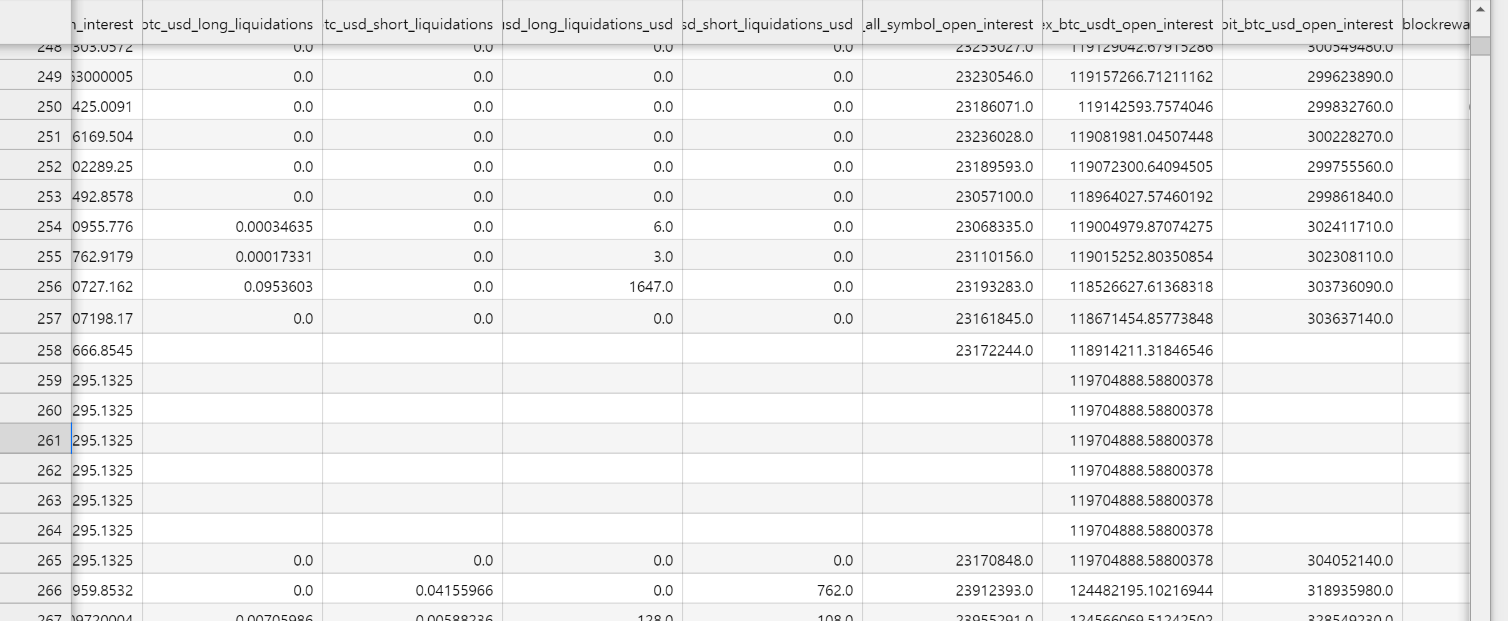
전체적으로 확인해보니 보통
- Network Data는 군데군데 뚫린 값이 많았고
- Market data(특히 Binance)는 3개이상 연속적인 결측치가 뜨는 값이 많았음
그래서 여러갈래로 생각 해보다가 걍 3개이상 연속적인 결측치를 기준으로
-
그보다 낮으면 ffill,
-
높으면 그 해당 값 위아래 10개의 평균으로 대체하는 방식
다른 거래소로 대체하기엔 거래소별 차이가 좀 있는 것 같애서
def fill_missing_values(df, columns_to_fill, consecutive_limit=3, window_size=10):
df_filled = df.copy()
for column in columns_to_fill:
# 결측치의 연속 길이 계산
null_series = df_filled[column].isnull()
consecutive_nulls = null_series.groupby((null_series != null_series.shift()).cumsum()).cumcount() + 1
# 3개 미만의 연속적인 결측치는 ffill로 처리
mask_short = (consecutive_nulls < consecutive_limit) & null_series
df_filled.loc[mask_short, column] = df_filled[column].ffill()
# 3개 이상의 연속적인 결측치는 위아래 10개 값의 평균으로 대체
mask_long = (consecutive_nulls >= consecutive_limit) & null_series
for idx in df_filled.index[mask_long]:
start_idx = max(0, df_filled.index.get_loc(idx) - window_size)
end_idx = min(len(df_filled), df_filled.index.get_loc(idx) + window_size + 1)
window = df_filled.iloc[start_idx:end_idx][column]
df_filled.loc[idx, column] = window.mean() # 또는 window.median() 사용
return df_filled
# 모든 열에 대해 처리 적용
columns_to_fill = eda_df_cleaned.columns.tolist()
# 결측치 처리 실행
eda_df_filled = fill_missing_values(eda_df_cleaned, columns_to_fill)
# 결과 확인
print("원본 데이터의 결측치 개수:")
print(eda_df_cleaned.isnull().sum())
print("\n처리 후 데이터의 결측치 개수:")
print(eda_df_filled.isnull().sum())
# 처리 전후 비교
print("\n처리 전후 결측치 개수 차이:")
print(eda_df_cleaned.isnull().sum() - eda_df_filled.isnull().sum())
# 샘플 데이터 확인 (예: 처음 5행)
print("\n처리 전 샘플 데이터:")
print(eda_df_cleaned.head())
print("\n처리 후 샘플 데이터:")
print(eda_df_filled.head())
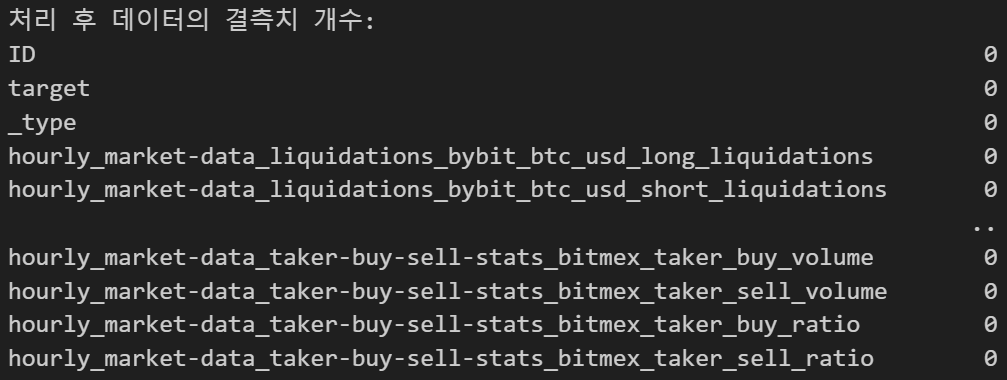
8760 rows × 215 columns 이렇게 모든 데이터의 결측치 처리가 완료되었음.
정규화
이제 마지막으로 정규화하려고 함. 우선 215개의 컬럼중 정규화가 필요한 컬럼부터 골라야 했음. 모든 컬럼을 정규화할 순 없으니까.
# 수치형 컬럼만 선택
numeric_columns = eda_df_filled.select_dtypes(include=[np.number]).columns
# 각 컬럼의 통계 정보 계산
stats = eda_df_filled[numeric_columns].describe()
# 스케일 차이 계산
scale_difference = stats.loc['max'] - stats.loc['min']
# 평균과 중앙값의 차이 계산
mean_median_difference = np.abs(stats.loc['mean'] - stats.loc['50%'])
# 변동 계수 (Coefficient of Variation) 계산
cv = stats.loc['std'] / stats.loc['mean']
# 결과를 DataFrame으로 정리
analysis = pd.DataFrame({
'Scale_Difference': scale_difference,
'Mean_Median_Difference': mean_median_difference,
'Coefficient_of_Variation': cv
})
# 정규화/표준화가 필요한 컬럼 선택
scale_threshold = np.percentile(scale_difference, 75) # 상위 25% 기준
mean_median_threshold = np.percentile(mean_median_difference, 75) # 상위 25% 기준
cv_threshold = np.percentile(cv, 75) # 상위 25% 기준
columns_to_normalize = analysis[
(analysis['Scale_Difference'] > scale_threshold) |
(analysis['Mean_Median_Difference'] > mean_median_threshold) |
(analysis['Coefficient_of_Variation'] > cv_threshold)
].index.tolist()
print("Columns recommended for normalization/standardization:")
print(columns_to_normalize)
print(len(columns_to_normalize))
105개의 컬럼이 선택됨. 여러 정규화 방식 중 뭘 할까 하다가
RobustScaler방식을 해보기로 했음. gpt가 비트코인 데이터는 이상치가 좀 있을 수 있는데 이상치에 가장 덜 민감하대서.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
eda_df_normalized = eda_df_filled.copy()
eda_df_normalized[columns_to_normalize] = scaler.fit_transform(eda_df_filled[columns_to_normalize])
전처리 완료
다음 시간엔 시각화 EDA를 하면서 데이터를 뜯어봐야겠다.