정형/시계열데이터와 피쳐엔지니어링, 이미지 & 텍스트 데이터 전처리와 분석
범주형 데이터
범주형 데이터의 정의와 종류
범주형 데이터: 명확한 그룹으로 구분되는 데이터
a) 명목형 데이터: 순서가 상관없이 항목으로 구분 (예: 성별, 국가, 과일 종류)
b) 순서형 데이터: 값 사이에 순서가 존재 (예: 리커트 척도, 영화 별점)
범주형 데이터의 특징
- 집단 간 분석에 용이함
- 범주별 통계 지표 확인 가능
- 범주 간 관계 분석에 유용 (예: 추천 알고리즘)
명목형 데이터 처리
기계학습 모델을 위한 전처리 방법
-
Label Encoding
각 카테고리에 숫자 할당 (예: [한국, 일본, 중국, 미국] => [0, 1, 2, 3])
주의점: 없는 레이블에 대한 처리 필요 2개 이상의 카테고리에서 순서 암시 가능성 -
One-Hot Encoding 각 카테고리를 별도의 이진 컬럼으로 변환 장점: 순서 정보 제거 단점: 범주가 많을 경우 데이터 크기 증가
-
Binary Encoding 레이블링 후 이진수로 변환 범주 수가 많을 때 효과적
-
Embedding/Hashing 자연어 처리 기법 활용 랜덤 해시 값 사용
순서형 데이터
명목형 데이터에 순서 정보가 추가된 형태
순환형 데이터 (Cyclical Data)
순서는 있지만 값이 순환되는 경우 (예: 월, 요일, 각도) 삼각함수를 이용한 표현 가능
수치형 데이터
수치형 데이터의 종류
이산형 데이터: 정수 형태 (예: 인구 수, 제품 수)
연속형 데이터: 실수 형태 (예: 키, 몸무게, 온도)
구간형과 비례형
구간형 데이터: 구간의 값이 중요 (예: 온도, 시간)
비율형 데이터: 원점과의 거리가 중요 (예: 인구수, 횟수, 밀도)
데이터 해석의 중요성
대표값만으로는 데이터의 전체 특성을 파악하기 어려움
시각화의 필요성 강조
왜도(skewness)와 첨도(kurtosis) 고려
데이터 분포의 대칭성을 위한 방법
Negative Skewness 처리: 제곱 변환, 지수 함수
Positive Skewness 처리: 로그 변환, 제곱근 변환
Box-Cox Transformation: 다양한 변환을 포괄하는 방법
결측치 (Missing Values)
결측치: 데이터셋에 누락된 값 (Null, NA)
“데이터가 없다”는 정보 자체도 의미가 있을 수 있음
대부분의 모델에서는 공백으로 둘 수 없음
결측치 처리 방법
제외: 해당 행이나 열의 데이터를 제거 예측: 다른 방법으로 값을 채움 주의점: 데이터 편향 강화 가능성
결측치와 EDA (탐색적 데이터 분석)
결측치가 과반수인 경우: 결측치 유무만 사용 또는 해당 열 제외
결측치가 유의미하게 많은 경우 (>5%): 결측치 정보의 의미 파악
결측치 개수가 매우 적은 경우: 해당 행 제외 고려 또는 대표값으로 채우기
결측치 해결 방법
규칙 기반: 도메인 지식이나 논리적 추론 사용
집단 대표값: 특정 집단의 평균, 중앙값, 최빈값 등 사용
모델 기반: 회귀 모델 등을 통해 예측
import missingno as msno
msno_plot = msno.matrix(titanic)

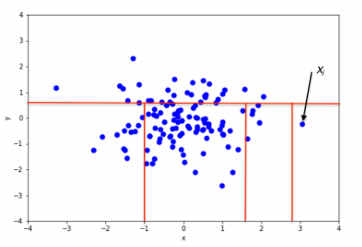
이상치 (Outliers)
관측된 데이터 범위에서 과하게 벗어난 값
이상치 탐지 방법
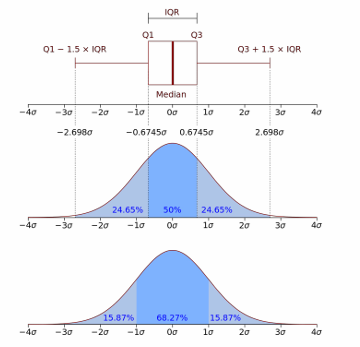
IQR (Interquartile Range)
IQR = 3분위수 - 1분위수
이상치 기준: 1분위수 - 1.5IQR 미만 또는 3분위수 + 1.5IQR 초과
표준편차
이상치 기준: 평균 ± (2 또는 3) * 표준편차
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
밀도 기반 클러스터링 방법
주변 포인트의 개수, 경계, 노이즈 등을 설정하여 자동으로 집단 설정
클러스터에서 동떨어진 포인트를 이상치로 간주
Isolation Forest
결정 트리 기반의 이상치 탐지 방법
루트 노드와의 거리를 통해 이상치 탐지
피처 엔지니어링
더 나은 특성을 통해 좋은 모델을 만들고 해석을 용이하게 하는 과정
주요 방법
특성 추출 (Feature Extraction): 특성 간 결합을 통해 새로운 특성 생성
특성 선택 (Feature Selection): 중요 특성 선택
특성 추출 및 생성 방법
사칙 연산을 통한 값 연산
범주와 범주, 범주와 수치 간의 연결
도메인 지식을 활용한 다양한 결합
클러스터링
유사한 성격을 가진 데이터를 그룹으로 분류하는 것
EDA, 새로운 피처 생성, 최종 그룹 구분 및 의사 결정에 활용
주요 클러스터링 방법
K-Means: K개의 그룹으로 데이터 분리
Hierarchical Clustering: 데이터를 점진적으로 분류
DBSCAN: 밀도 기반 클러스터링
GMM (Gaussian Mixture Model): 가우시안 분포 혼합 모델링
차원 축소
데이터의 특성(feature) 수를 줄이는 방법
데이터 복잡성 감소, 시각화, 모델 성능 향상에 도움
주요 차원 축소 방법
PCA (Principal Component Analysis)
t-SNE (t-distributed Stochastic Neighbor Embedding)
UMAP (Uniform Manifold Approximation and Projection)
LDA (Linear Discriminant Analysis)
Isomap
Autoencoder
차원 축소와 시각화
차원 축소 후 산점도를 통해 다양한 인사이트 추출 가능
예: 타이타닉 데이터에서 생존/성별/객실에 따른 분포 시각화
시계열 데이터
하나의 변수를 시간에 따라 여러 번 관측한 데이터
가격, 매출, 온도, 성장 등의 변화 예측과 반복되는 패턴에 대한 인사이트 도출
시계열 데이터의 주요 특징
추세(trend): 장기적인 증가 또는 감소
계절성(seasonality): 특정 요일/계절에 따른 영향
주기(cycle): 고정된 빈도는 아니지만 형태적으로 유사하게 나타나는 패턴
노이즈(noise): 측정 오류, 내부 변동성 등 다양한 요인으로 생기는 왜곡
시계열 데이터 분석 방법론
성분 분석: 추세, 계절성, 주기, 노이즈를 통해 시계열을 분석
시계열 데이터 = 규칙성 데이터 + 불규칙 데이터
가법 모델(additive model): 추세 + 계절성 + 주기 + 노이즈
승법 모델(multiplicative model): 추세 * 계절성 * 주기 + 노이즈
모델 선택: 시간에 따라 변동폭이 일정하면 가법 모델, 커지면 승법 모델 사용
정상성과 비정상성
정상성: 시간에 따라 통계적 특성(평균, 분산, 공분산)이 변하지 않음
비정상성: 시간에 따라 통계적 특성이 변함
대부분의 시계열 데이터는 비정상성을 가짐 (예: 물가, 가격, 사용자 수 등)
이미지 데이터
Domain: 의료, 교통, 사물, 풍경, 사람(얼굴, 신체), 패션, 만화 등
Task: Classification, Detection, Segmentation, Generation, Feature Extraction 등
Quality: 적절한 이미지 데이터셋
이미지 데이터 EDA 순서
Target 중심: 분포 위주의 초기 비교 (정형 데이터 해석)
Input 중심: 이미지 데이터의 개별 비교 (도메인 지식)
Process 중심: (전처리-모델-결과 해석) 반복
이미지 데이터 전처리
데이터 퀄리티 향상 데이터 양 증대 쉬운 검증 (시각화를 통한 인지 개선)
이미지 데이터 전처리 방법
색상 공간 변환
노이즈 삽입
사이즈 조정 (Resizing): Crop & Interpolation
아핀 변환 (Affine Transformation): 회전, 왜곡, 평행 이동 등
특성 추출 (Feature Extraction): SIFT, SURF, ORB, FAST 등
이미지 데이터 라이브러리
- OpenCV: 효율적인 처리, 복잡한 사용
- PIL (Python Image Library => Pillow): 쉬운 이미지 전처리 기능 제공
- scikit-image: SciPy 기반 이미지 처리
- albumentations: 이미지 전처리용 라이브러리, 데이터 증강에 활용
- torchvision: torch 기반 이미지 전처리
- SciPy: 대부분의 기능적 요소 탑재
텍스트 데이터
텍스트 데이터의 어려움
- 언어 구조에 따른 의미 변화
- 문법 규칙의 다양성
- 불필요한 표현 존재
- 오타, 띄어쓰기 등의 오차
- 방언, 신조어 포함 가능성
- 개인정보 포함 가능성
- 문맥에 따른 의미 변화
- 시기적, 사회적 의미 변화
텍스트 데이터 활용 분야
- 정보 추출
- 트렌드 분석 (이슈 트래킹)
- 검색 및 질의
- 텍스트 군집 및 분류 (스팸 탐지)
- 텍스트 생성 (자동 완성 및 문서 생성)
- 멀티모달 활용 (음성-텍스트, 이미지-텍스트)
텍스트 데이터 전처리
전처리 종류
짧은 단어/표현 전처리: 정규표현식, 토큰화, 소문자 변환, 불용어 제거, 철자 교정
문단 전처리: 문장 토큰화, 띄어쓰기 교정, 문장 구조 분석, 문맥적 의미 분석
정규표현식 (Regular Expression)
문자열의 특정 패턴을 표현하는 방법 검색, 유효성 검사 등에 사용
토큰화 절차
- 선택적 전처리 (cleansing)
- 문단/문장 토큰화
- 단어 토큰화
- 서브워드 토큰화
- 불용어 제거 (stopword)
- 어간 추출 & 표제어 추출 (stemming & lemmatization)
텍스트 시각화
워드 클라우드 (Word Cloud)
단어의 빈도나 중요도를 시각적으로 표현

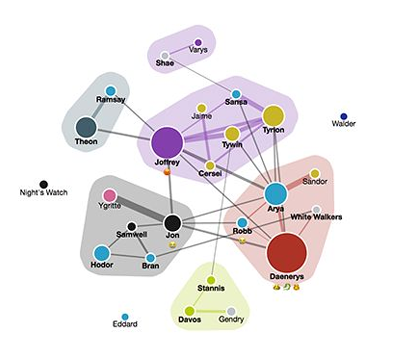
네트워크 시각화
단어 간의 관계를 네트워크 형태로 표현
Highlight 기반 시각화
중요한 부분을 강조하여 표시
