콘텐츠 메타데이터 자동 생성 도구 만들기 backend작업
의식의 흐름

위의 공고를 보고 자기소개서를 쓰려는데 특별히 해당하는 프로젝트가 없었다. 그래서 그냥 기존 LLM프로젝트 넣으려다 한번 만들어보는 것도 재밋을 거 같아 만들어보기로 함.
콘텐츠 메타데이터 자동 생성 도구
-
개요: 블로그, 뉴스 등의 콘텐츠에서 키워드, 요약, 카테고리 등을 자동 추출하는 도구
-
구현 내용:
- LLM을 활용한 텍스트 요약 및 핵심 키워드 추출
- 콘텐츠 카테고리 자동 분류 및 태깅
- 배치 처리와 API 엔드포인트 구현
-
기술 스택: Python, Flask/FastAPI, Hugging Face Transformers, SQLite
-
장점: 네이버의 UGC 메타데이터 처리와 연관성이 높으며, 검색 인덱싱에 도움이 됨
최근 자연어 처리 기술의 발전을 기반으로, 저는 콘텐츠에서 핵심 정보를 자동으로 추출하는 도구를 기획·개발했습니다. 블로그, 뉴스 기사 등 다양한 콘텐츠를 대상으로 LLM 기반의 키워드 추출, 요약, 자동 분류 및 태깅 기능을 구현하고, 이를 배치 처리 및 API 형태로 활용 가능하도록 구성했습니다. 검색 품질 개선이나 UGC 메타데이터 정제와 같은 네이버의 서비스 구조와도 높은 관련성이 있다고 생각했습니다.
그러던 중, 단순한 기술 실험을 넘어 사회적 맥락에 맞춘 실험도 흥미롭겠다는 생각이 들었습니다. 마침 대통령선거 기간이었기에, 언론·커뮤니티 데이터를 기반으로 사회 여론을 실시간 분석하는 프로젝트로 확장해보기로 했습니다. 각종 기사와 댓글을 분석하여 긍·부정 감성 분석, 주제별 분류, 그리고 시계열 기반의 여론 변화 시각화를 구현해보려 했습니다.
근데 문제가 많았다.
문제점1
-
저작권 및 크롤링 제한 문제
사실 대부분의 도메인은 /robot.txt을 뒤에 붙여서 일반 유저에게 크롤링을 허용하는지 확인이 가능하다. 사실 난 공부용 프로젝트고, 비상업적 이기에 크게 문제가 되지는 않을 거라 생각하지만 그래도 뭔가 찜찜한 기분으로 프로젝트를 하고 싶지 않았다.
한번 내가 크롤링하려고 시도했던 사례들을 보면
에펨코리아
User-agent: ia_archiver Disallow: / User-agent: PetalBot Disallow: / ... User-agent: Claude-Web Disallow: / ... User-agent: * Disallow: /*listStyle= Disallow: /*act=IS& Disallow: /*act=IS$ Disallow: /*act=dispBoardCategory Disallow: /*act=procFileDownload Disallow: /*search_keyword= Disallow: /*search_target= Disallow: /*module_srl= Disallow: /*act=dispMemberBookmark Disallow: /*_filter= Disallow: /*m=0& Disallow: /*m=0$ Disallow: /*m=1& Disallow: /*m=1$ Disallow: /*m=6& Disallow: /*m=6$ Disallow: /_loader-
AI 특정 크롤러는 전체 사이트 크롤링 금지.
-
일반 크롤러는 일부 URL 패턴(검색, 다운로드, 특정 액션 등)만 크롤링 금지, 나머지는 허용
디시인사이드
User-agent: * Disallow: /- 일반 크롤러 전체 사이트 크롤링 금지
이외에도 대부분 커뮤니티 사이트는 크롤링이 금지된다. 당연한 얘기지만 운영자 입장에서도 데이터를 굳이 줘서 좋을게 없다. 옛날에 에펨코리아에 문의해서 연도별 게시판 활성화 유저 수를 프로젝트에 쓰고 싶어서 문의했는데 바로 거절당한 기억도 있다.
언론사(MBN)
User-agent: Googlebot Allow: / User-agent: Googlebot-News Allow: / User-agent: Googlebot-Image Allow: / User-agent: Google Search Console Allow: / User-agent: Googlebot/2.1 Allow: / User-agent: Googlebot-Smartphone Allow: / User-agent: Mediapartners-Google Allow: / User-agent: popIn_Agent Allow: / User-agent: Bingbot Allow: / User-agent: MSNBot Allow: / User-agent: MSNBot-Media Allow: / User-agent: BingPreview Allow: / User-agent: Facebot Allow: / User-agent: Yeti Allow: / User-agent: facebookexternalhit/1.1 Allow: / User-agent: facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) Allow: / User-agent: Twitterbot Allow: / User-agent: Applebot Allow: /AI 특정 크롤러는 전체 사이트 크롤링 금지.
한겨례
User-agent: * Disallow: /arti/PRINT/ Disallow: /fortunes/result Disallow: /arti/PREVIEW/ Disallow: /api/ Disallow: /test/- 모든 크롤러(봇)는 아래 경로의 크롤링이 금지됩니다.
/arti/PRINT/: 기사 인쇄용 페이지/fortunes/result: 운세 결과 페이지/arti/PREVIEW/: 기사 미리보기 페이지/api/: API 엔드포인트/test/: 테스트용 경로
- 즉, 위 경로를 제외한 나머지 경로는 크롤링이 허용됩니다.
이건 의외였다. 언론사들도 커뮤니티와 마찬가지로 일반유저를 포함한 크롤링을 막아놓을 줄 알았는데 AI bot만 막아놓고 일반 크롤러들은 허용해두었다.
일부 언론사는 AI 크롤러만 차단한 반면, 디시인사이드 등 커뮤니티는 모든 접근을 제한하고 있다. 실제로 로봇 배제 표준(
robots.txt)을 검토하며, 합법적인 범위 내에서 어떤 데이터를 사용할 수 있을지 하나하나 확인해야 했고 단순히 기술을 구현하는 것을 넘어 데이터 윤리와 합법성을 함께 고려해야 한다는 점이 마음에 걸렸다. -
문제점2
프로젝트가 정치적이다. 정확히 말하자면
의도는 정치적이지 않으나, 결과는 정치적일 수 있다.
사실 통계라는것은 끼워맞추기가 가능하다. 유리한 건 넣고 불리한 건 빼면서 특정 후보에게 유리한 결과를 시각화가 가능하다.
특히 매일 바뀌는 지지율, 사람들의 데이터로 시각화한 것을 다른 사람들에게 공유하는 행위는 추구한 목적은 순수한 기술 실험이었지만, 결과적으로 특정 후보의 지지율을 시각화하거나 언론 반응을 정량화하는 작업은 정치적 해석을 유도할 수 있는 결과물이 될 수 있다는 것도 꺼려졌다.
결국
위의 프로젝트는 접어두고 좀 재미없을 수 있어도 간결히 구현가능한 프로젝트로 선회했다.
정치 기사 메타데이터 자동 생성 시스템 구축기
프로젝트 개요
정치 기사의 메타데이터를 자동으로 생성하는 FastAPI 기반 웹 서비스를 개발했습니다. 이 시스템은 AI를 활용해 기사의 요약, 카테고리 분류, 키워드 추출, 개체명 인식, 태그 생성을 자동화합니다.
개발 동기
기존 뉴스 플랫폼에서는 다음과 같은 문제점들이 있었습니다:
- 수동 태깅의 한계: 기사마다 수동으로 태그를 달기엔 시간과 인력이 부족
- 검색 효율성 저하: 적절한 메타데이터 부족으로 인한 검색 품질 문제
- 콘텐츠 분류의 일관성 부족: 사람마다 다른 기준으로 분류하는 문제
- 대용량 처리의 어려움: 실시간으로 쏟아지는 뉴스 처리의 한계
이런 문제들을 해결하기 위해 AI 기반 자동 메타데이터 생성 시스템을 구축하게 되었습니다.
🏗️ 시스템 아키텍처
전체 구조
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Frontend │ │ FastAPI │ │ MySQL │
│ (Future) │◄──►│ Backend │◄──►│ Database │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
┌─────────────────┐
│ AI ML Models │
│ (Hugging Face) │
└─────────────────┘
🛠️ 기술 스택
Backend Framework
- FastAPI
Database
- MySQL 8.0
AI/ML Stack
- Transformers 4.36.0: Hugging Face 모델 라이브러리
- PyTorch 2.1.0: 딥러닝 프레임워크
- KoNLPy: 한국어 자연어 처리 (최종적으로는 간단한 규칙 기반으로 대체)
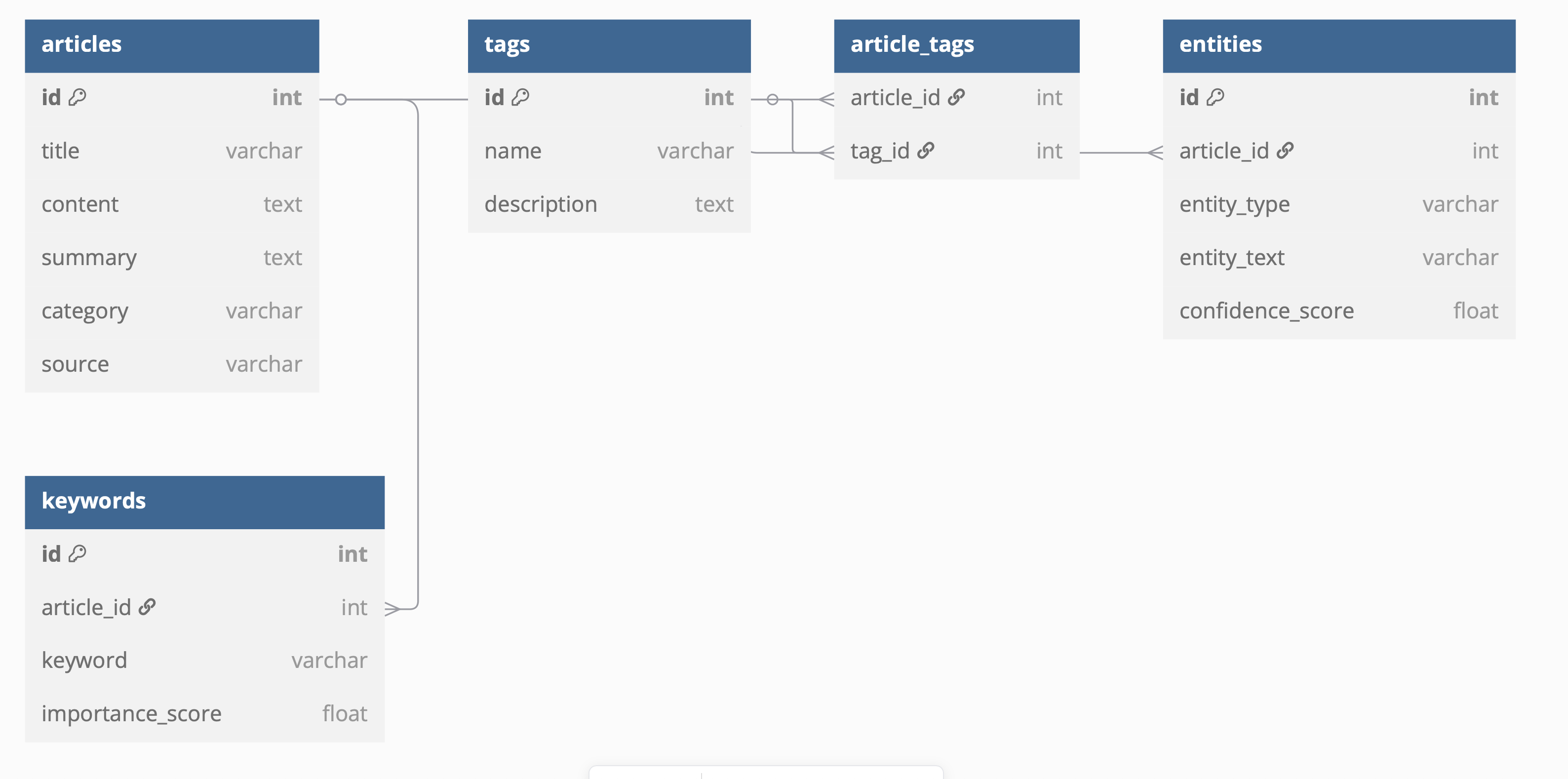
🗃️ 데이터베이스 설계
ERD 구조
AI 메타데이터 생성 파이프라인
1. 텍스트 전처리
def _preprocess_text(self, text: str) -> str:
# HTML 태그 제거
text = re.sub(r'<[^>]+>', '', text)
# 특수문자 정리
text = re.sub(r'[^\w\s가-힣]', ' ', text)
# 연속 공백 제거
text = re.sub(r'\s+', ' ', text).strip()
return text
2. 카테고리 자동 분류
political_categories = {
"정책": ["정책", "공약", "법안", "제도", "개혁", "복지", "경제"],
"인사": ["인사", "임명", "해임", "사퇴", "후보", "지명"],
"선거": ["선거", "투표", "후보", "공천", "캠페인", "여론조사"],
"논란": ["논란", "비판", "갈등", "반발", "문제", "스캔들"]
}
3. 개체명 인식 (NER)
- 인물명: 정규표현식 기반 한국어 인명 패턴 매칭
- 기관명: 정당, 정부기관 등 정치 관련 조직
- 지역명: 시/도 단위 지역 및 주요 정치 시설
4. 키워드 추출
- 형태소 분석 대신 단어 단위 분리 및 빈도 분석
- 불용어 제거 및 중요도 점수 계산
- 정치 도메인 특화 키워드 우선 순위
API 엔드포인트 설계
기사 관리 API
POST /api/v1/articles/ # 기사 등록 및 메타데이터 생성
GET /api/v1/articles/ # 기사 목록 조회
GET /api/v1/articles/{id} # 특정 기사 조회
POST /api/v1/articles/analyze # 분석만 수행 (저장 안함)
필터링 및 검색 API
GET /api/v1/articles/?category=정책 # 카테고리별 조회
GET /api/v1/articles/?tag=대통령선거 # 태그별 조회
GET /api/v1/articles/?keyword=경제 # 키워드별 조회
메타데이터 API
GET /api/v1/categories/ # 카테고리 목록
GET /api/v1/tags/ # 태그 목록
GET /api/v1/keywords/top # 인기 키워드
GET /api/v1/stats/ # 전체 통계
📡 API 사용 예시
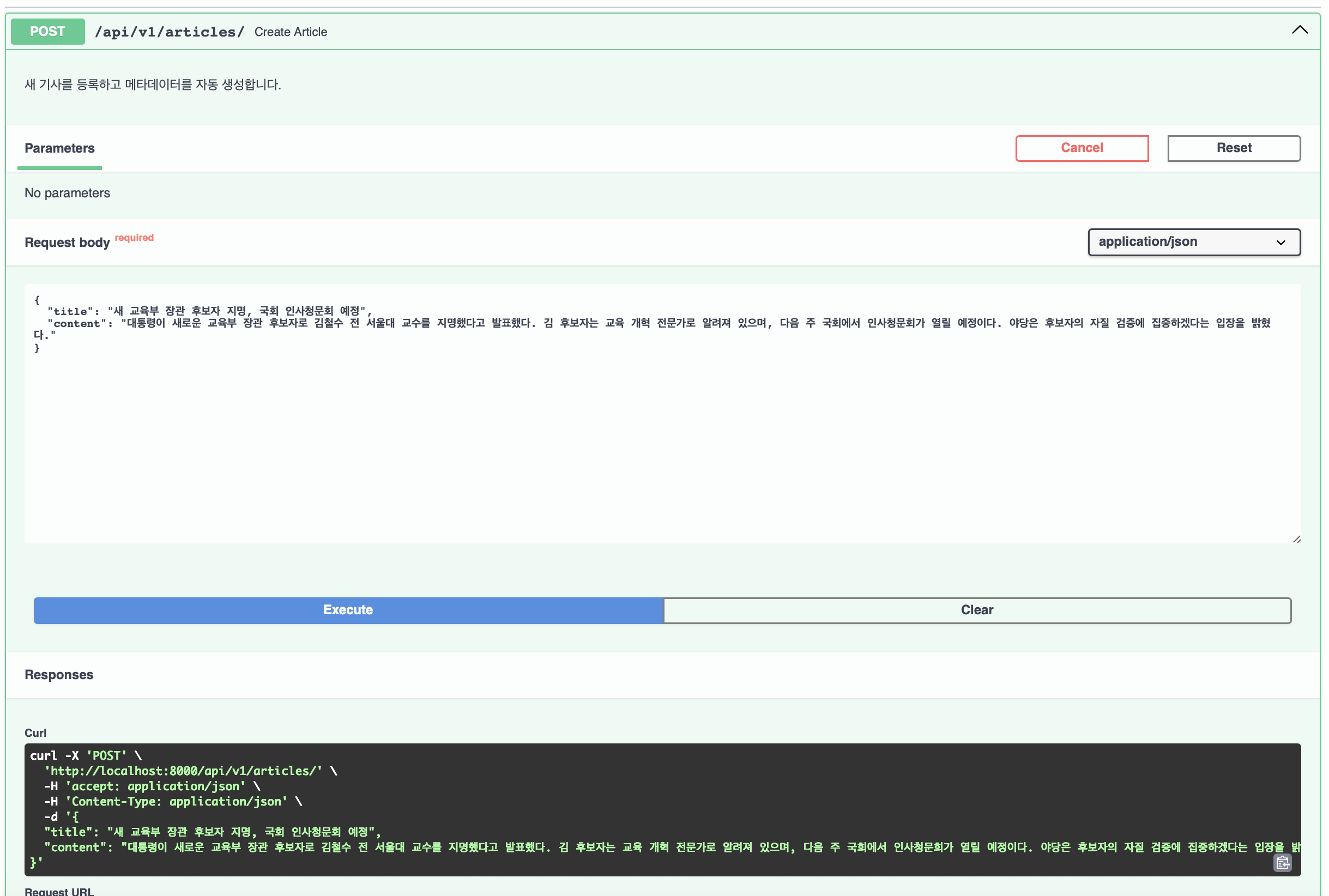
{
"message": "기사가 성공적으로 등록되었습니다.",
"article_id": 2,
"processing_time": "1.24초",
"metadata": {
"summary": "대통령이 새로운 교육부 장관 후보자로 김철수 전 서울대 교수를 지명했다고 발표했다. 김 후보자는 교육 개혁 전문가로 알려져 있으며, 다음 주 국회에서 인사청문회가 열릴 예정이다.",
"category": "인사",
"keywords_count": 10,
"entities_count": 4,
"tags_count": 7
}
}
[
{
"title": "한동훈 비대위원장, 당 개혁 방안 발표",
"content": "국민의힘 한동훈 비상대책위원장이 오늘 당 개혁 방안을 발표했다. 주요 내용으로는 청년층 영입 확대, 정책 연구소 신설, 그리고 지역조직 강화 방안이 포함되었다. 한 위원장은 당의 쇄신을 통해 국민의 신뢰를 회복하겠다고 강조했다.",
"source": "당정뉴스",
"id": 1,
"summary": "국민의힘 한동훈 비상대책위원장이 오늘 당 개혁 방안을 발표했다. 주요 내용으로는 청년층 영입 확대, 정책 연구소 신설, 그리고 지역조직 강화 방안이 포함되었다.",
"category": "정책",
"created_at": "2025-05-22T05:18:49",
"updated_at": "2025-05-22T05:18:49",
"tags": [
{
"name": "#방안",
"description": null,
"id": 1,
"created_at": "2025-05-22T05:18:49"
},
{
"name": "#정책",
"description": null,
"id": 2,
"created_at": "2025-05-22T05:18:49"
},
{
"name": "#위원장",
"description": null,
"id": 3,
"created_at": "2025-05-22T05:18:49"
},
{
"name": "#한동훈",
"description": null,
"id": 4,
"created_at": "2025-05-22T05:18:49"
},
{
"name": "#개혁",
"description": null,
"id": 5,
"created_at": "2025-05-22T05:18:49"
},
{
"name": "#발표",
"description": null,
"id": 6,
"created_at": "2025-05-22T05:18:49"
},
{
"name": "#국민의힘",
"description": null,
"id": 7,
"created_at": "2025-05-22T05:18:49"
}
],
"entities": [
{
"entity_type": "PERSON",
"entity_text": "한동훈",
"confidence_score": "0.850",
"id": 1,
"article_id": 1
},
{
"entity_type": "ORGANIZATION",
"entity_text": "국민의힘",
"confidence_score": "0.900",
"id": 2,
"article_id": 1
}
],
"keywords": [
{
"keyword": "방안",
"importance_score": "1.0",
"id": 1,
"article_id": 1
},
{
"keyword": "한동훈",
"importance_score": "0.9",
"id": 2,
"article_id": 1
},
{
"keyword": "위원장",
"importance_score": "0.8",
"id": 3,
"article_id": 1
},
{
"keyword": "개혁",
"importance_score": "0.7",
"id": 4,
"article_id": 1
},
{
"keyword": "발표",
"importance_score": "0.6",
"id": 5,
"article_id": 1
},
{
"keyword": "국민",
"importance_score": "0.5",
"id": 6,
"article_id": 1
},
{
"keyword": "비대",
"importance_score": "0.4",
"id": 7,
"article_id": 1
},
{
"keyword": "비상",
"importance_score": "0.3",
"id": 8,
"article_id": 1
},
{
"keyword": "대책",
"importance_score": "0.2",
"id": 9,
"article_id": 1
},
{
"keyword": "위원",
"importance_score": "0.1",
"id": 10,
"article_id": 1
}
]
},
{
"title": "새 교육부 장관 후보자 지명, 국회 인사청문회 예정",
"content": "대통령이 새로운 교육부 장관 후보자로 김철수 전 서울대 교수를 지명했다고 발표했다. 김 후보자는 교육 개혁 전문가로 알려져 있으며, 다음 주 국회에서 인사청문회가 열릴 예정이다. 야당은 후보자의 자질 검증에 집중하겠다는 입장을 밝혔다.",
"source": null,
"id": 2,
"summary": "대통령이 새로운 교육부 장관 후보자로 김철수 전 서울대 교수를 지명했다고 발표했다. 김 후보자는 교육 개혁 전문가로 알려져 있으며, 다음 주 국회에서 인사청문회가 열릴 예정이다.",
"category": "인사",
"created_at": "2025-05-22T05:25:04",
"updated_at": "2025-05-22T05:25:05",
"tags": [
{
"name": "#후보자",
"description": null,
"id": 8,
"created_at": "2025-05-22T05:25:05"
},
{
"name": "대통령선거2024",
"description": null,
"id": 9,
"created_at": "2025-05-22T05:25:05"
},
{
"name": "#교육부",
"description": null,
"id": 10,
"created_at": "2025-05-22T05:25:05"
},
{
"name": "#국회",
"description": null,
"id": 11,
"created_at": "2025-05-22T05:25:05"
},
{
"name": "#인사",
"description": null,
"id": 12,
"created_at": "2025-05-22T05:25:05"
},
{
"name": "#장관",
"description": null,
"id": 13,
"created_at": "2025-05-22T05:25:05"
},
{
"name": "#지명",
"description": null,
"id": 14,
"created_at": "2025-05-22T05:25:05"
}
],
"entities": [
{
"entity_type": "PERSON",
"entity_text": "교육부",
"confidence_score": "0.850",
"id": 3,
"article_id": 2
},
{
"entity_type": "PERSON",
"entity_text": "예정",
"confidence_score": "0.850",
"id": 4,
"article_id": 2
},
{
"entity_type": "LOCATION",
"entity_text": "서울",
"confidence_score": "0.800",
"id": 5,
"article_id": 2
},
{
"entity_type": "LOCATION",
"entity_text": "국회",
"confidence_score": "0.800",
"id": 6,
"article_id": 2
}
],
"keywords": [
{
"keyword": "후보자",
"importance_score": "1.0",
"id": 11,
"article_id": 2
},
{
"keyword": "교육부",
"importance_score": "0.9",
"id": 12,
"article_id": 2
},
{
"keyword": "장관",
"importance_score": "0.8",
"id": 13,
"article_id": 2
},
{
"keyword": "지명",
"importance_score": "0.7",
"id": 14,
"article_id": 2
},
{
"keyword": "국회",
"importance_score": "0.6",
"id": 15,
"article_id": 2
},
{
"keyword": "인사청문회",
"importance_score": "0.5",
"id": 16,
"article_id": 2
},
{
"keyword": "예정",
"importance_score": "0.4",
"id": 17,
"article_id": 2
},
{
"keyword": "대통령",
"importance_score": "0.3",
"id": 18,
"article_id": 2
},
{
"keyword": "김철수",
"importance_score": "0.2",
"id": 19,
"article_id": 2
},
{
"keyword": "서울대",
"importance_score": "0.1",
"id": 20,
"article_id": 2
}
]
}
]
에러 핸들링 및 폴백
KoNLPy가 잘 안대서 우선 규칙기반으로 때워놧다. 향후 수정.
try:
# AI 모델 사용 시도
result = self.ai_model.process(text)
except Exception:
# 폴백: 규칙 기반 처리
result = self.fallback_process(text)
배포 및 운영
개발 환경 실행
# 의존성 설치
pip install -r requirements.txt
# 환경변수 설정
export MYSQL_PASSWORD="your_password"
# 서버 실행
uvicorn app.main:app --reload --host 0.0.0.0 --port 8000
향후 개선 계획
- 규칙 기반이 아닌 KoNLPy등 hugging face 모델 사용하게 하기
- 최신 기사들 갖다 붙여서 잘되나 테스트
- 프론트엔드 구현