클러스터링
클러스터링 다루기
지난 시간에 정규화까지 마쳤다.
# 1. 클러스터링 전 위도와 경도 시각화
plt.figure(figsize=(12, 8))
plt.scatter(train['longitude'], train['latitude'], alpha=0.1)
plt.title('Distribution of Apartments before Clustering')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.savefig('before_clustering.png')
plt.close()
# 위도와 경도 데이터 추출
X = train[['latitude', 'longitude']].values
# K-means 클러스터링 수행
n_clusters = 50
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
train['cluster'] = kmeans.fit_predict(X)
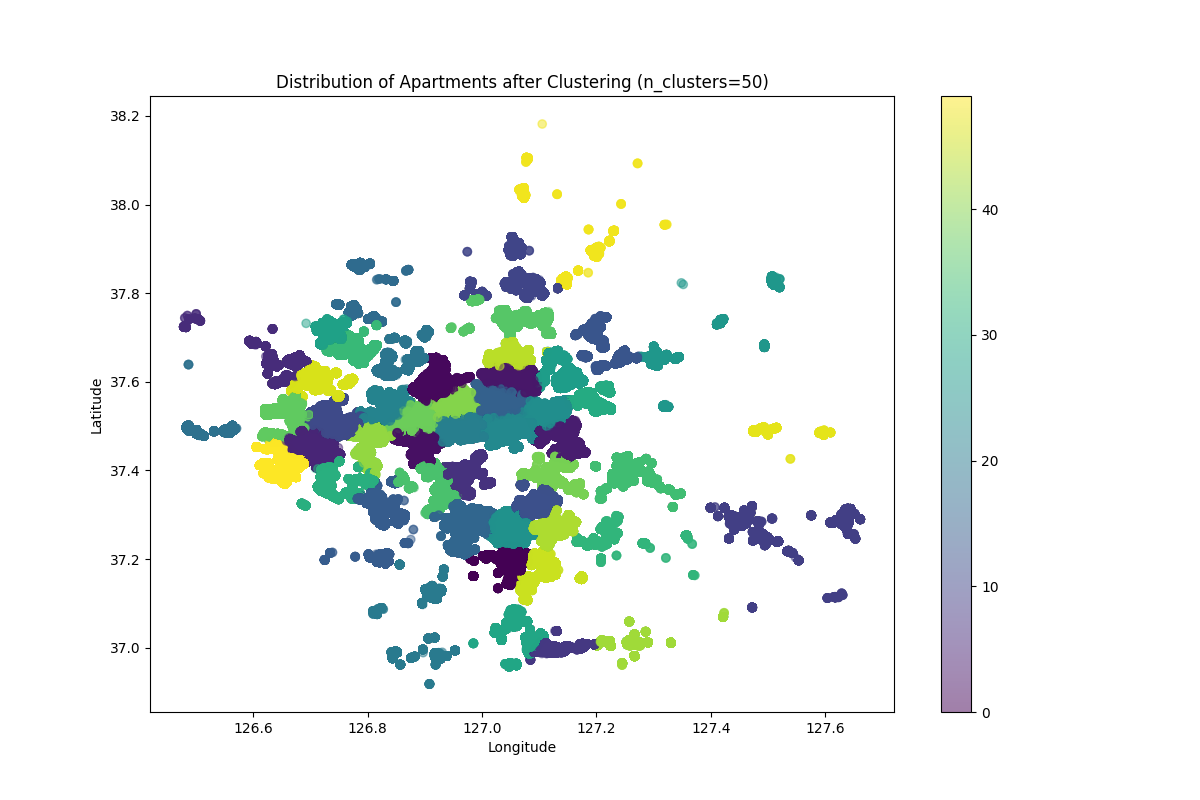
# 2. 클러스터링 후 시각화
plt.figure(figsize=(12, 8))
scatter = plt.scatter(train['longitude'], train['latitude'], c=train['cluster'], cmap='viridis', alpha=0.5)
plt.colorbar(scatter)
plt.title(f'Distribution of Apartments after Clustering (n_clusters={n_clusters})')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.savefig('after_clustering.png')
plt.close()
# 각 클러스터의 평균 전세가 계산 및 추가
cluster_mean_deposit = train.groupby('cluster')['deposit'].mean()
train['cluster_mean_deposit'] = train['cluster'].map(cluster_mean_deposit)
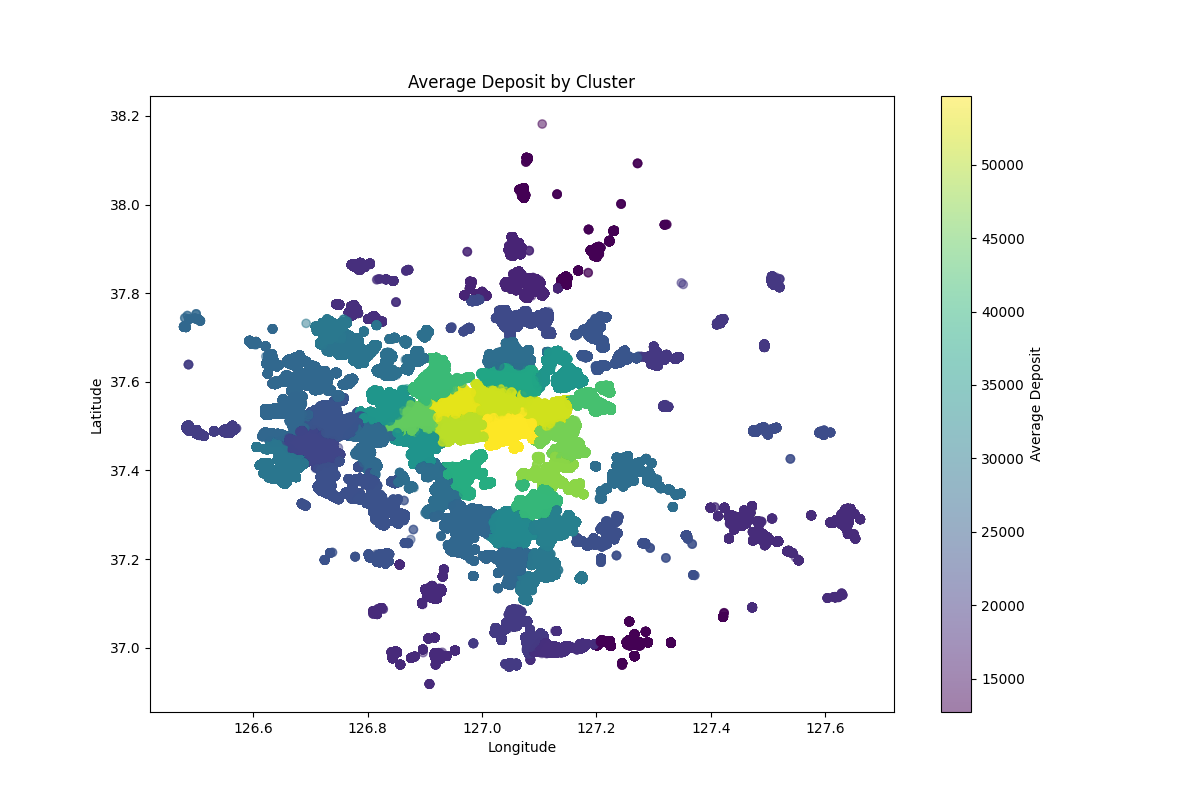
# 3. 클러스터별 평균 전세가 시각화
plt.figure(figsize=(12, 8))
scatter = plt.scatter(train['longitude'], train['latitude'], c=train['cluster_mean_deposit'], cmap='viridis', alpha=0.5)
plt.colorbar(scatter, label='Average Deposit')
plt.title('Average Deposit by Cluster')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.savefig('cluster_average_deposit.png')
plt.close()
print("시각화가 완료되었습니다. 'before_clustering.png', 'after_clustering.png', 'cluster_average_deposit.png' 파일을 확인해주세요.")
# 결과 확인
print(train[['latitude', 'longitude', 'deposit', 'cluster', 'cluster_mean_deposit']].head())
# 클러스터 중심점 확인
cluster_centers = pd.DataFrame(kmeans.cluster_centers_, columns=['latitude', 'longitude'])
print("\n클러스터 중심점:")
print(cluster_centers.head())
클러스터링 전 위도와 경도 시각화
K-means 클러스터링 후 시각화
클러스터별 평균 전세가 시각화
latitude longitude deposit cluster cluster_mean_deposit
0 37.054314 127.045216 17000.0 29 19843.132735
1 37.054314 127.045216 23000.0 29 19843.132735
2 37.054314 127.045216 23000.0 29 19843.132735
3 36.964647 127.055847 5000.0 29 19843.132735
4 36.972390 127.084514 1800.0 8 18374.126192
클러스터 중심점:
latitude longitude
0 37.200820 127.052740
1 37.596156 126.918466
2 37.460977 126.883407
3 37.608796 127.052230
4 37.473787 127.140393
지도 저거 맞나? 난 왜 한강이 안보이지? 다른 사람들 지도 시각화는 한강보였던것 같은데?
쨌든 저기서 평균 전셋값 클러스터로 모델링하면 괜찮을 것 같애서 Elbow로 돌려봤다.
Elbow Method
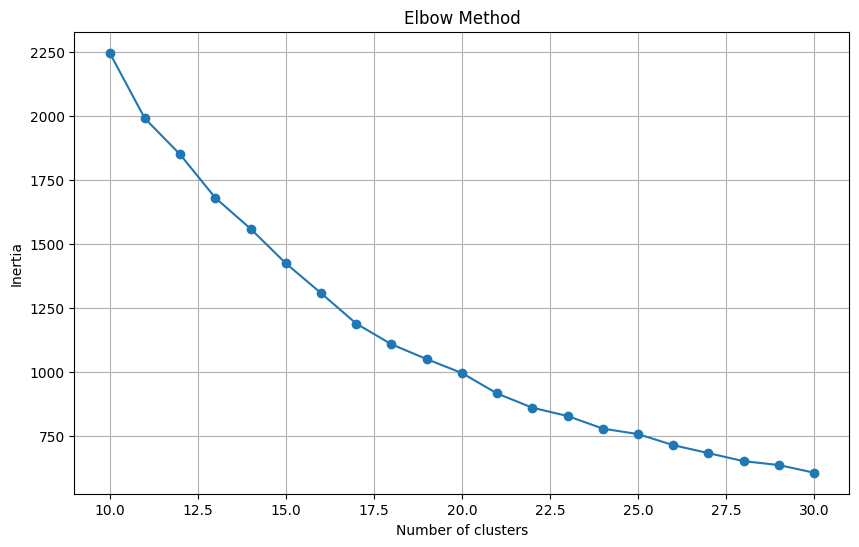
최적의 클러스터 수 (Elbow Method): 11
클러스터 수를 11로 두고
- 클러스터별 평균 전세가 계산
- 클러스터 중심까지의 거리 계산
RF모델링해서 냈는데 valid랑 리더보드랑 차이가 너무 심하고 15000가까이 MAE가 산출되었다.
모델링 잘못인가? 해서 LGBM으로 바꿔서 제출했는데도 여전했다. 오늘은 딴거 하지말고 이 문제만 한번 해결해보자.
문제해결해보기
- 과적합인가?
다중공선성(Multicollinearity)을 확인하고 VIF(Variance Inflation Factor)를 사용해 과적합 문제를 해결하는 코드
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 데이터 로드
train = pd.read_csv('train.csv')
# 필요한 특성 선택 (이전에 사용한 특성들)
features = ['latitude', 'longitude', 'area_m2', 'cluster', 'cluster_mean_deposit', 'distance_to_center']
# 데이터 준비
X = train[features]
# 스케일링 (VIF 계산 전에 권장됨)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled = pd.DataFrame(X_scaled, columns=features)
# VIF 계산
vif_data = pd.DataFrame()
vif_data["feature"] = features
vif_data["VIF"] = [variance_inflation_factor(X_scaled.values, i) for i in range(len(features))]
# VIF 결과 출력
print("VIF 결과:")
print(vif_data.sort_values("VIF", ascending=False))
# VIF가 높은 특성 제거 (예: VIF > 10)
high_vif_features = vif_data[vif_data["VIF"] > 10]["feature"].tolist()
print(f"\nVIF가 10을 초과하는 특성: {high_vif_features}")
# 높은 VIF를 가진 특성을 제거한 새로운 특성 목록
new_features = [f for f in features if f not in high_vif_features]
print(f"\n제거 후 남은 특성: {new_features}")
# 새로운 특성으로 모델 재학습 (예시 코드)
# X_new = train[new_features]
# y = train['deposit']
# 여기에 모델 재학습 코드 추가 (예: LightGBM 사용)
- VIF = 1: 다중공선성 없음
- 1 < VIF < 5: 약간의 다중공선성 (대체로 문제 없음)
- 5 < VIF < 10: 중간 정도의 다중공선성 (주의 필요)
- VIF > 10: 높은 다중공선성 (문제가 될 수 있음)
VIF 결과: feature VIF 4 cluster_mean_deposit 1.499729 3 cluster 1.231631 1 longitude 1.204037 0 latitude 1.156332 5 distance_to_center 1.080621 2 area_m2 1.005231 VIF가 10을 초과하는 특성: []
뭐지.. 이 문제는 아닌가? 오히려 저번에 공원피쳐 만들때 상관관계 높을 때 체크될 수 있을듯?
- 위도, 경도를 정규화하면 안되지 않나?
다시 곰곰이 코드를 읽고 있는데
# 위도와 경도 데이터 추출 및 정규화
X_train = train[['latitude', 'longitude']].values
X_test = test[['latitude', 'longitude']].values
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# K-means 클러스터링 수행
optimal_cluster = 11
kmeans = KMeans(n_clusters=optimal_cluster, random_state=42, n_init=10)
train['cluster'] = kmeans.fit_predict(X_train_scaled)
test['cluster'] = kmeans.predict(X_test_scaled)
# 클러스터별 평균 전세가 계산 및 추가
cluster_mean_deposit = train.groupby('cluster')['deposit'].mean()
train['cluster_mean_deposit'] = train['cluster'].map(cluster_mean_deposit)
test['cluster_mean_deposit'] = test['cluster'].map(cluster_mean_deposit)
# 클러스터 중심까지의 거리 계산
train['distance_to_center'] = kmeans.transform(X_train_scaled).min(axis=1)
test['distance_to_center'] = kmeans.transform(X_test_scaled).min(axis=1)
# 특성 선택
features = ['latitude', 'longitude', 'area_m2', 'cluster', 'cluster_mean_deposit', 'distance_to_center']
# 모델 훈련
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(train[features], train['deposit'])
# 테스트 데이터에 대한 예측
test['deposit'] = rf_model.predict(test[features])
# 결과를 CSV 파일로 저장
output = test[['index', 'deposit']]
output['deposit'] = output['deposit'].round(6) # 소수점 6자리까지 반올림
output.to_csv('output.csv', index=False)
print("예측 결과가 'output.csv' 파일로 저장되었습니다.")
# 모델 성능 평가 (선택적)
X_train, X_val, y_train, y_val = train_test_split(train[features], train['deposit'], test_size=0.2, random_state=42)
rf_model_eval = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model_eval.fit(X_train, y_train)
y_pred_val = rf_model_eval.predict(X_val)
mae = mean_absolute_error(y_val, y_pred_val)
print(f"\nMean Absolute Error on Validation Set: {mae}")
중간에 gpt가 시키지도 않았는데 위도,경도 데이터를 받고 정규화를 시켰다. 위도, 경도를 정규화 하면 안되지 않나? 근데 이게 문제가 맞나? 정규화를 하지 않고 RF돌린 결과가 아래긴한데 비슷한거같은데..
Mean Absolute Error on Validation Set: 4754.120671282844
예측 결과가 'output_without_normalization.csv' 파일로 저장되었습니다.
특성 중요도:
feature importance
2 area_m2 0.351573
4 cluster_mean_deposit 0.245402
1 longitude 0.166073
0 latitude 0.159027
5 distance_to_center 0.076500
3 cluster 0.001425
근데 오늘은 제출횟수를 2번 써버려서 이따 밤에 횟수남으면 확인해봐야겠다.
제출했는데 여전히 14000언저리다. 다른 문제를 찾아보자.
-
샘플링해서 훈련 데이터셋과 테스트 데이터 셋의 데이터 불균형
훈련 데이터 형태: (15568, 23) 테스트 데이터 형태: (150172, 23)시간이 너무 오래걸려서 train을 1/100으로 샘플링하고 진행했는데 그러고 보니까 test 데이터셋이 train보다 10배 정도 커져 버렸다. 여기서 잘못 된건가 싶다.