공원, 학교 피처 베이스라인에 넣어보기
test
이제 그동안 다뤘던 데이터 학교,공원 했고 이제 지하철하기 전에 제출횟수도 많은 김에 피처 하나하나 넣어가며 테스트 해보고 싶어졌다.
| 제출 output.csv | LightGBM MAE | 리더보드 MAE |
|---|---|---|
| baseline(중복처리x, 이후는 다 중복처리함) | 7904.04 | 7685.6469 |
| 1007_baseline_with_schools(1/100 샘플링하고 school_count_15km 피처추가 ) | 7906.37 | 7754.0806 |
| 1007_baseline_with_schools(그냥 school_count_15km 피처추가 ) | 7702.59 | 7523.0314 |
| 1007_baseline_with_schoolsparks(피처 10개) | 6558.13 | 7474.4724 |
| 1007_baseline_with_schoolsparks2(대표 피처 3개) | 6669.15 | 7671.2701 |
| PCA(제출x) | 8469.12 |
가볍게 15km반경이내 학교개수만 넣어서 제출했는데 MAE가 오히려 올랐다. 뭘 잘못 했나 했더니 데이터EDA할때 너무 오래걸려서 1/100 샘플링한 코드로 학습해버려서 오히려 올라갔다.
다시 중복만 제거한 코드에서 15km반경이내 학교개수 피처만 추가해서 돌리니까 100정도 낮게 나왔다.
이제 EDA에서 거친 상관계수 높은 것들을 넣어보았다.
대공원 = 면적 10만이상 소공원 = 면적 1만이하
15km 반경 내 대공원의 수(0.434845) 25km 반경 내 대공원의 총 면적(0.424748) 20km 반경 내 대공원의 총 면적(0.421022) 20km 반경 내 대공원의 수(0.391221) 15km 반경 내 소공원의 수 (0.394039) 25km 반경 내 대공원의 수 (0.374573)
15km 반경 내 중학교의 수 0.431299 20km 반경 내 중학교의 수 0.420702 15km 반경 내 고등학교의 수 0.409298 15km 반경 내 초등학교의 수 0.404774
위의 10개를 피쳐로 train에 추가하였다.
- 우선 한번 그대로 돌려보고
- 이 독립변수 끼리 너무 상관관계가 높은(0.8이상) 것들은 제거하고 다시 돌려보고 누가 잘 나오는지 판단해봐야지.
1007_baseline_with_schoolsparks(피처 10개) 우선 한번 걍 돌려보고 제출해봄
vscode에서는 6558.13이 나왔는데 제출하니까 7474.4724가 나왔다.
피처를 더 넣은만큼 100정도 내려가긴 했는데 역시 과적합이라 그런가. 제출 간 차이가 너무 컸다.
추가한 독립변수끼리 상관관계 검사
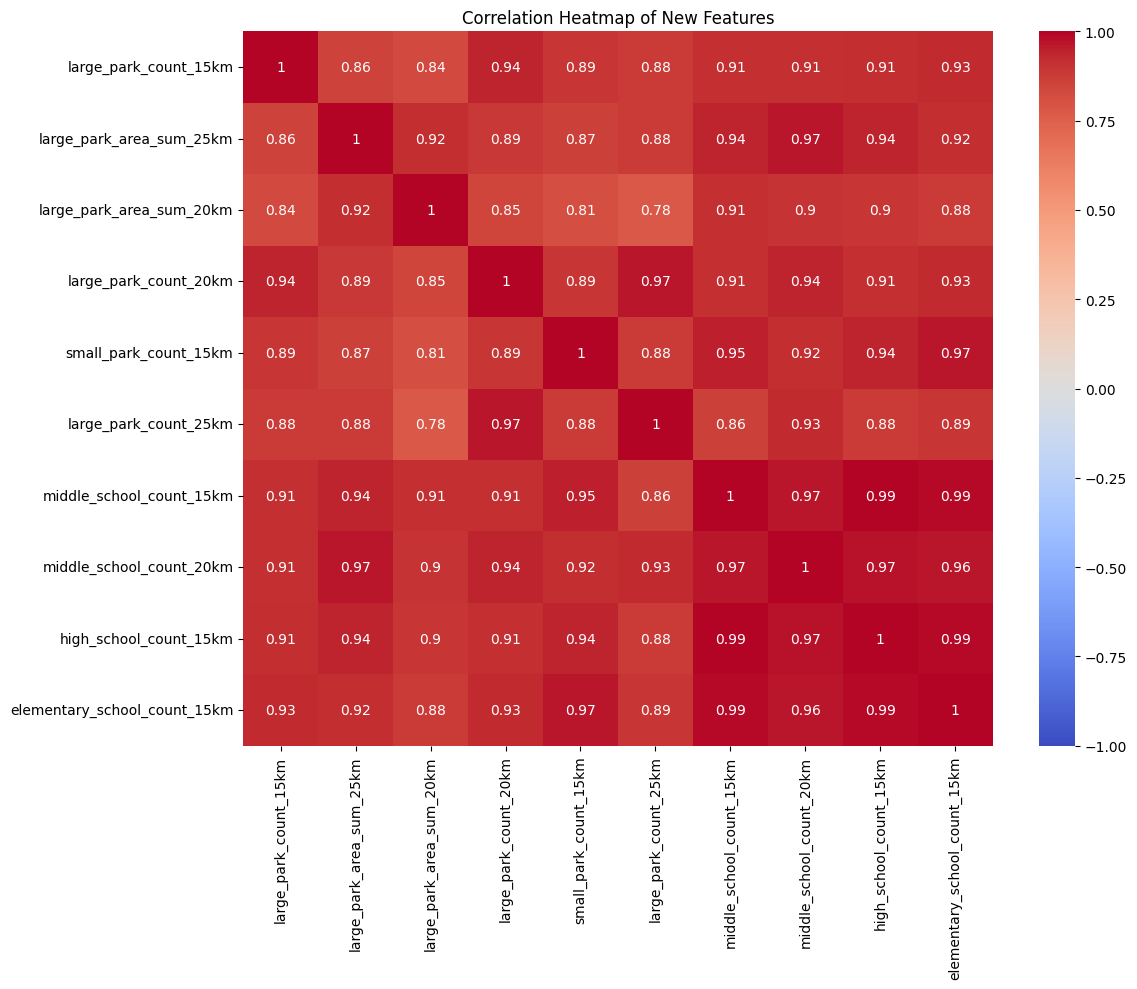
예상은 했다만 이정도일줄은 몰랐다. 공원피쳐끼리, 학교피쳐끼리는 높을줄 알았는데 걍 다 높네?
그래서 독립변수끼리 했는데 이렇게 나왔다.
원본 특성 MAE: 11932.339149102347
선택된 변수 MAE: 13415.662278707718
PCA MAE: 12906.793986183153
결합된 특성 MAE: 14036.204776826879
계층적 선택 MAE: 13415.662278707718
가장 작은 PCA로 해봤는데
검증 세트 MAE: 8469.12
예측 완료. 결과가 'output.csv' 파일로 저장되었습니다.
상위 10개 PCA 컴포넌트 중요도:
feature importance
0 PC_1 796
4 PC_5 622
3 PC_4 472
2 PC_3 399
6 PC_7 285
7 PC_8 199
1 PC_2 150
5 PC_6 77
8469.12가 나왔다. 너무 높네..? 과적합은 줄었겠지만 굳이 제출은 안해볼란다. 과적합은 걍 중요도 확인해서 다시 학습하던가 교차 검증하던가 해야되나? 마무리하려다가
마지막으로 이번에는
‘large_park_count_15km’
‘small_park_count_15km’
‘middle_school_count_15km’ 이 3개의 피처만 제외하고 7개를 드롭하고 돌려봤다.
6669.15로 피처전부넣었을때인 6558.13보다 높긴한데 과적합차이가 궁금해서 제출해봤다.
오히려 제출하고 보니까 피처10개보다 피처3개가 차이가 더 늘어났다… 흑흑.. 왜 더 늘어났지..?
쨋든 다음에는 남은 지하철이랑 금리 데이터를 파보고 다시 진행해보는 걸로 하자. 한번에 확 줄이는 것보다 조금씩 조금씩 줄어가니까 재밌는거 같당.