학교 데이터 다루기
학교 데이터 다루기
이번엔 공원에 이어서 학교와 deposit과의 연관관계를 다뤄봅시다. 공원때는 전셋집 반경의 공원의 수랑 공원의 면적을 봤지만 학교는 최소한 한개씩만 존재하면 되겟지? 해서 그것부터 돌려봄. 어차피 학교 데이터는 학교 면적도 없네.
이번에도 중복데이터 제거하고 랜덤으로 1/100샘플링해서 진행했다.
초,중,고 1,3,5km 반경 존재하는지
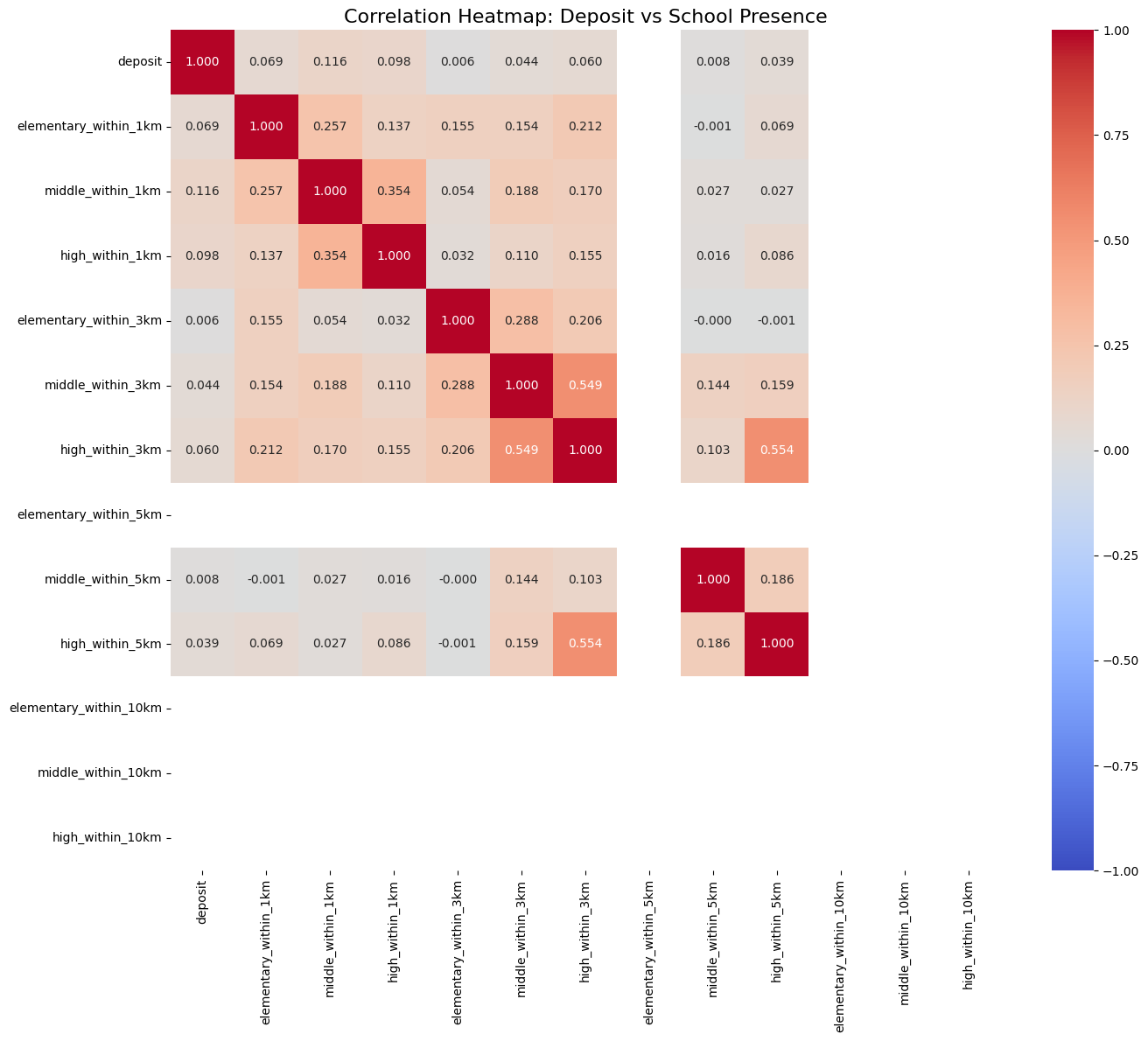
- middle_within_1km 0.116310
- high_within_1km 0.097602
- elementary_within_1km 0.069337
생각보다 상관관계가 많이 낮구나 하고 보고있는데 아래 10km반경 NaN이 떴다.
- elementary_within_5km NaN
- elementary_within_10km NaN
- middle_within_10km NaN
- high_within_10km NaN
갑자기 머리가 아파왔다. 뭐가 문젠지 생각해봤다. 데이터가 잘못 되었나? gpt한테 물어봤는데 아마 반경 10km이내에 전부 학교가 없거나 혹은 전부 있어서 측정불가라고 한다.
그런가? 한국에 학교가 그렇게 많나?
고등학교가 가장 적다고 하니 고등학교로 서치해봤다.

생각보다 촘촘히 되어있구나.
그래도 아래같은 도서산간은 10km 넘는데 있는데?
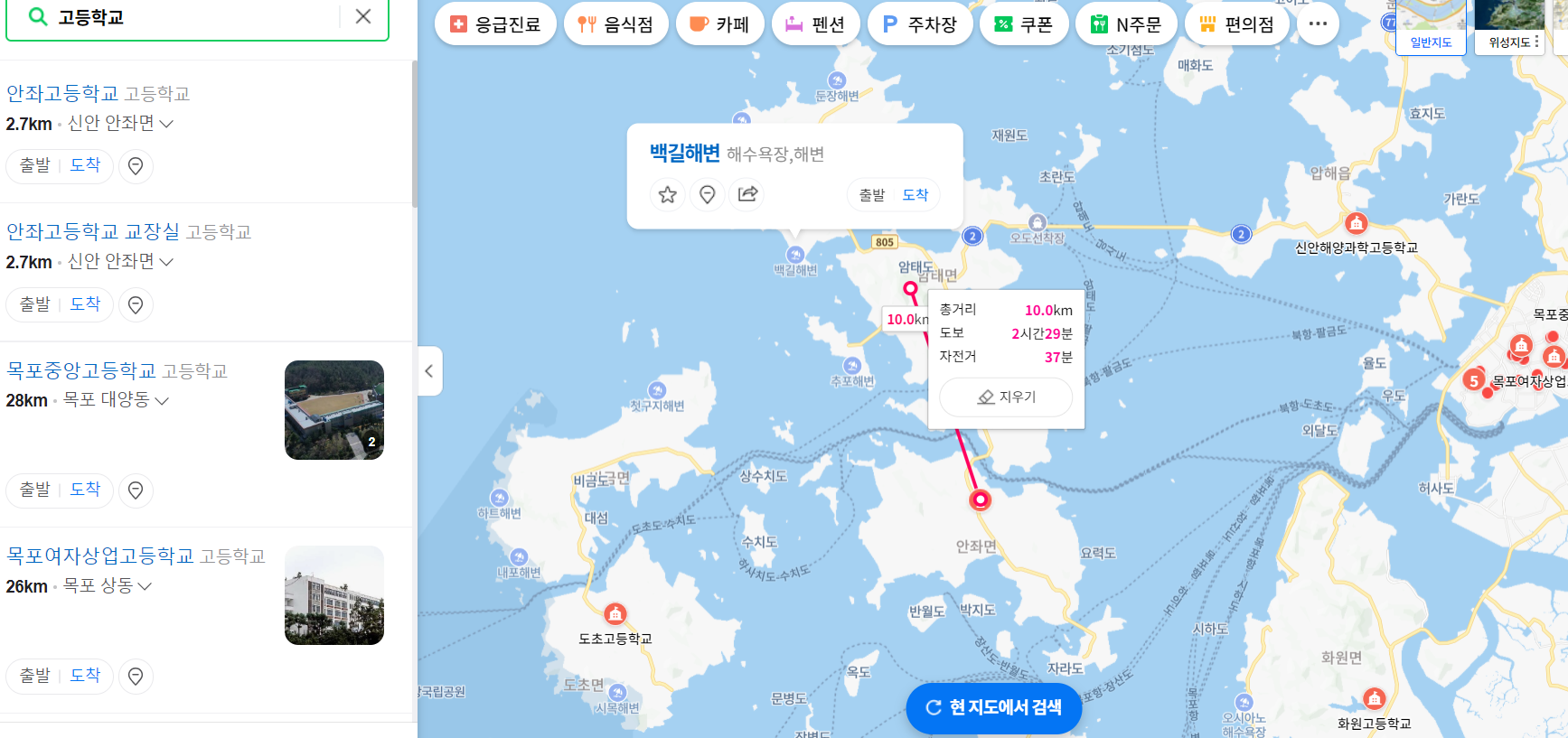
위도 경도 직접 찍어서 돌려봤다.
가장 가까운 elementary 학교:
거리: 0.72 km
위도: 34.89071154, 경도: 126.0468935
가장 가까운 middle 학교:
거리: 0.44 km
위도: 34.88817128, 경도: 126.0441776
가장 가까운 high 학교:
거리: 16.78 km
위도: 34.75002635, 경도: 126.1291567
뭐야. 10km 진짜 넘잖아.
그러면 1/100 샘플링 되면서 데이터가 소실되어서 안 잡힌건가?
해서 train 기존 데이터로 잡아봤는데
찾고자 하는 위치가 train 데이터셋에 존재하지 않습니다.
가장 가까운 위치:
위도: 36.9179099, 경도: 126.9080289
차이: 위도 3.65826859, 경도 0.40106224
거리: 3.68018750
애초에 해당 위도경도의 집이 train 데이터에 없는 것 같았다.
아 생각해보니까 train 데이터의 위도경도는 수도권만 존재한다. 그러면 엥간한 5km이내에 전부 학교가 있겠구나. 그래서 NaN이 나왔겠구나.
그러면 다시 상관관계를 높일 수 있는 기준을 생각해보자.
공원때처럼 생각해보자.
근처에 고등학교가 많아! -> 그렇다고 매일매일 다양한 고등학교를 가진 않겠지! -> 그러나 학교가 많다 -> 학습권이 좋다. -> 전셋값이 비쌈.
거리내의 학교 개수로 상관관계 해보자.
초,중,고 5,15,25km 학교 갯수

middle_count_15km 0.431299
high_count_15km 0.409298
elementary_count_15km 0.404774
middle_count_25km 0.389875
되게 높다. 좀 간격을 줄여보자.
초,중,고 10,15,20km 학교 갯수

middle_count_15km 0.431299
middle_count_20km 0.420702
high_count_15km 0.409298
elementary_count_15km 0.404774
신기하게 공원때랑 마찬가지로 15km반경이 가장 상관관계가 높다.