공원 데이터 다루기3
공원 데이터 다루기 마지막
이번이 공원의 마지막이 될 것 같다.
# 중복 제거
train_no_duplicates = train.drop_duplicates(subset=columns_to_check)
print(f"원본 데이터셋 크기: {len(train)}")
print(f"중복 제거 후 데이터셋 크기: {len(train_no_duplicates)}")
print(f"제거된 행의 수: {len(train) - len(train_no_duplicates)}")
- 원본 데이터셋 크기: 1801228
- 중복 제거 후 데이터셋 크기: 1717611 제거된 행의 수: 83617
train_sample = train_no_duplicates.sample(frac=0.01, random_state=42)
print(f"중복제거 데이터셋 크기: {len(train_no_duplicates)}")
print(f"1/100 후 데이터셋 크기: {len(train_sample)}")
print(f"제거된 행의 수: {len(train_no_duplicates) - len(train_sample)}")
- 중복제거 데이터셋 크기: 1717611
- 1/100 후 데이터셋 크기: 17176
- 제거된 행의 수: 1700435
처음에 걍 본래 데이터로 하다가 너무 데이터가 커서 그런가 너무 오래걸려서 중복데이터 처리하고 랜덤으로 1/100으로 나눔

- 대공원(면적10만이상)
- 중공원(면적1만~10만)
- 소공원(면적 1만 이하)
이렇게 3개로 나누어서 상관관계 분석 진행
대공원 3,5,10km
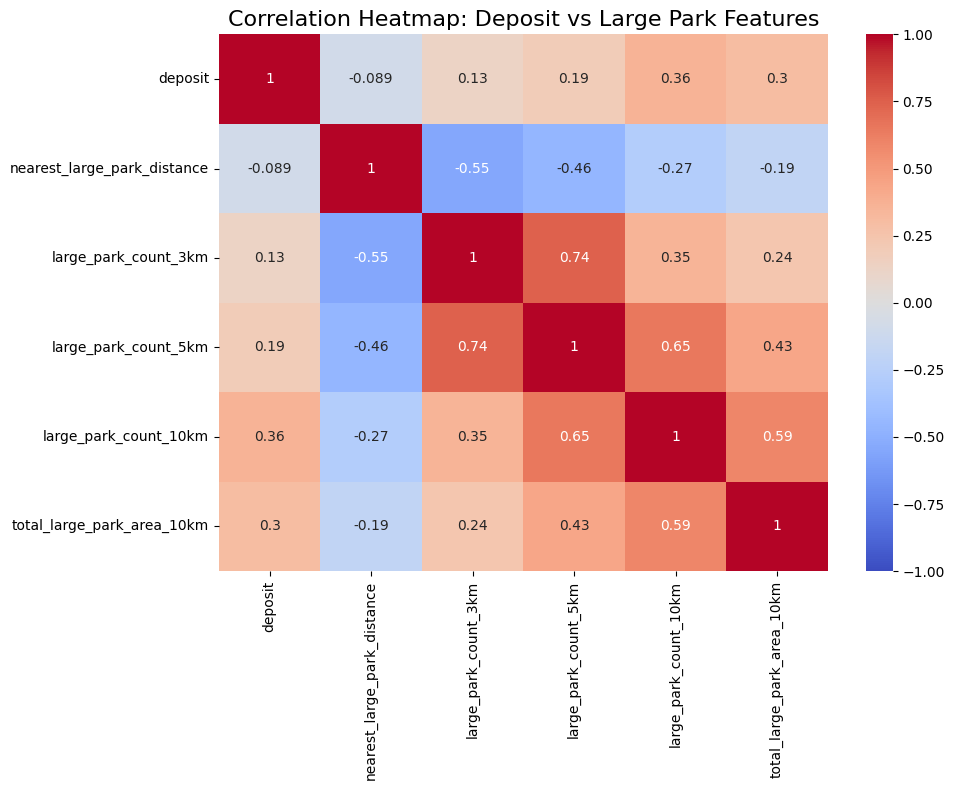
- large_park_count_10km 0.359712
- total_large_park_area_10km 0.304367
첨에는 3,5,10km로 나누어서 분석했는데 10km쪽이 개수든 10km이내 공원의 면적이든 상관관계가 크게 나왔음. 예상하긴 했음. 아무래도 대공원이니까.
nearest_large_park_distance는 음의 상관관계로 나왔는데 정상임. 작을수록 거리가 작다는 거여서. 다른 값들은 커지니까 양의 상관관계로 나오는거고.
대공원 10,20,30,50km
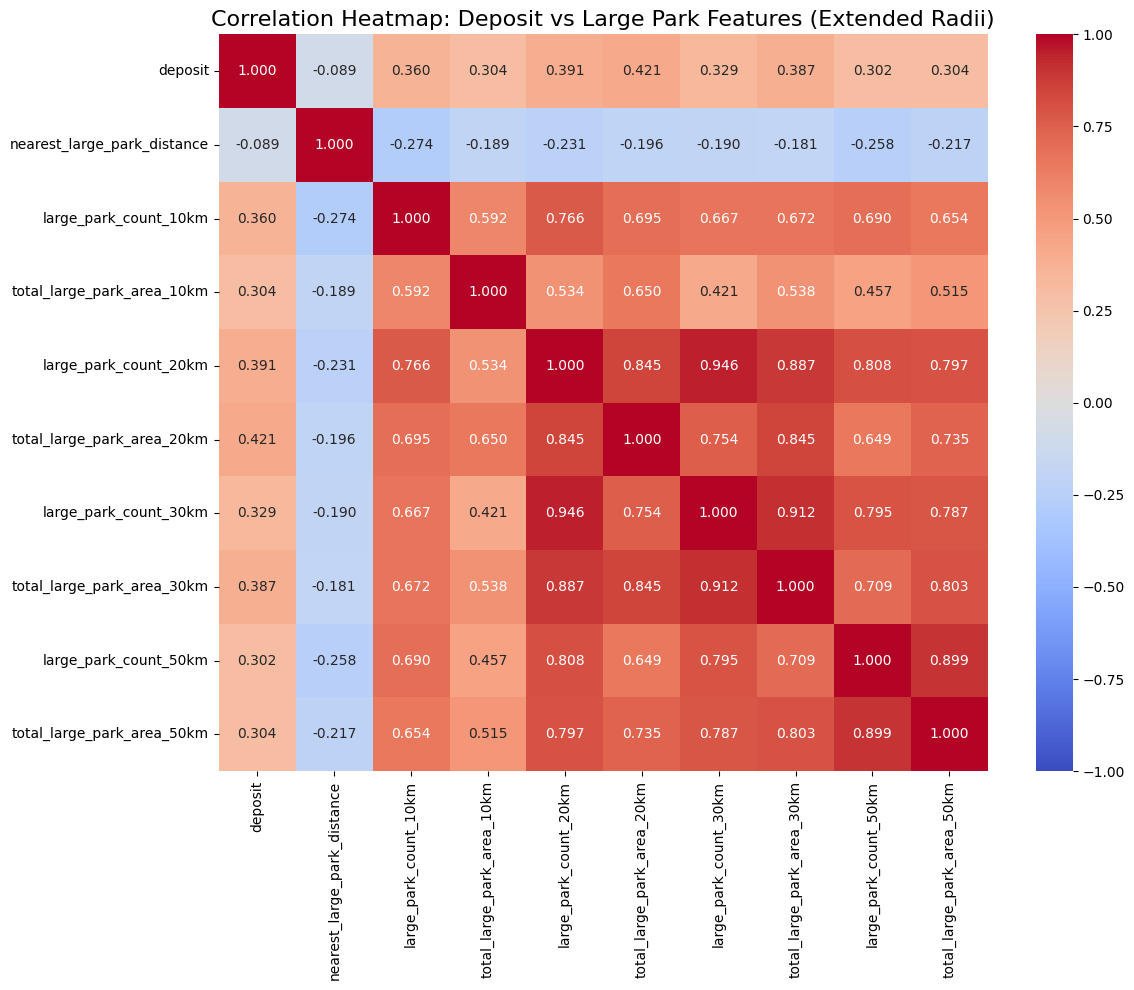
10km가 잘 나왔으니까 10,20,30,50으로 진행해봄.
total_large_park_area_20km (0.421022):
- 20km 반경 내 대형 공원의 총 면적이 전세가와 가장 강한 양의 상관관계를 보입니다.
- 이는 넓은 지역에 걸친 대형 공원의 존재가 전세가에 긍정적인 영향을 미칠 수 있음을 시사합니다.
large_park_count_20km (0.391221):
- 20km 반경 내 대형 공원의 수도 전세가와 상당한 양의 상관관계를 보입니다.
- 공원의 수와 면적 모두 20km 반경에서 가장 강한 상관관계를 보이는 점이 주목할 만합니다.
total_large_park_area_30km (0.386995):
- 30km 반경 내 대형 공원의 총 면적도 전세가와 양의 상관관계를 보입니다.
- 20km보다는 약간 낮지만, 여전히 중요한 영향을 미치는 것으로 보입니다.
20km가 가장 강한 상관관계를 가지고 아무래도 대공원이라 그런가 공원의 수보다는 공원의 면적에 더 강한 상관관계를 가짐.
대공원 15,20,25km
20km가 잘나왔으니까 마지막으로 15,20,25로 돌려봄.
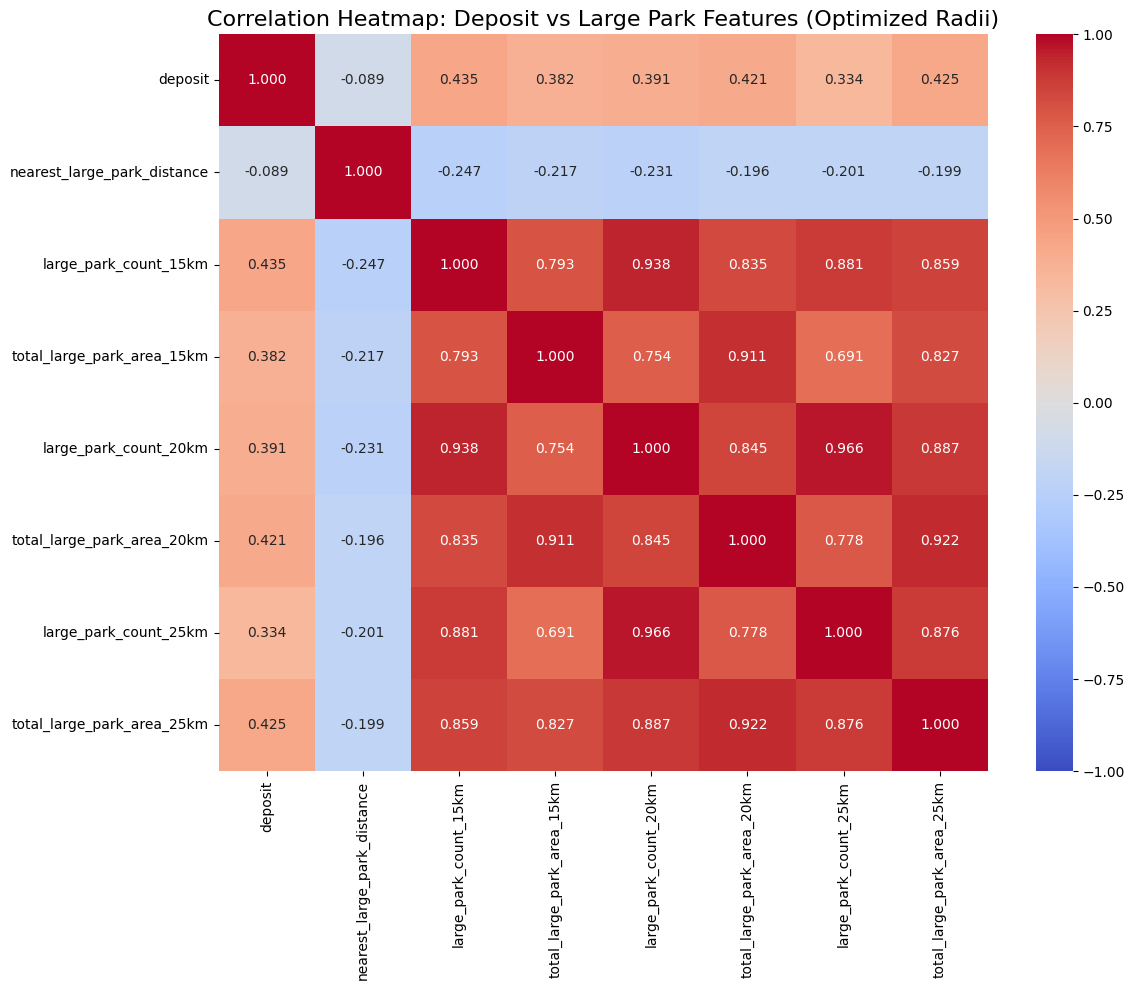
15km 반경 내 대공원의 수(0.434845) > 25km 반경 내 대공원의 총 면적(0.424748) > 20km 반경 내 대공원의 총 면적(0.421022) > 20km 반경 내 대공원의 수(0.391221)
신기하게 15km반경 내 대공원 개수가 가장 높게 나옴. 뭐 대충 이정도로 대공원은 마무리 함.
중공원 5,15,25km
중공원은 면적 1만이상 10만이하다. 5,15,25km로 처음에 진행했다.
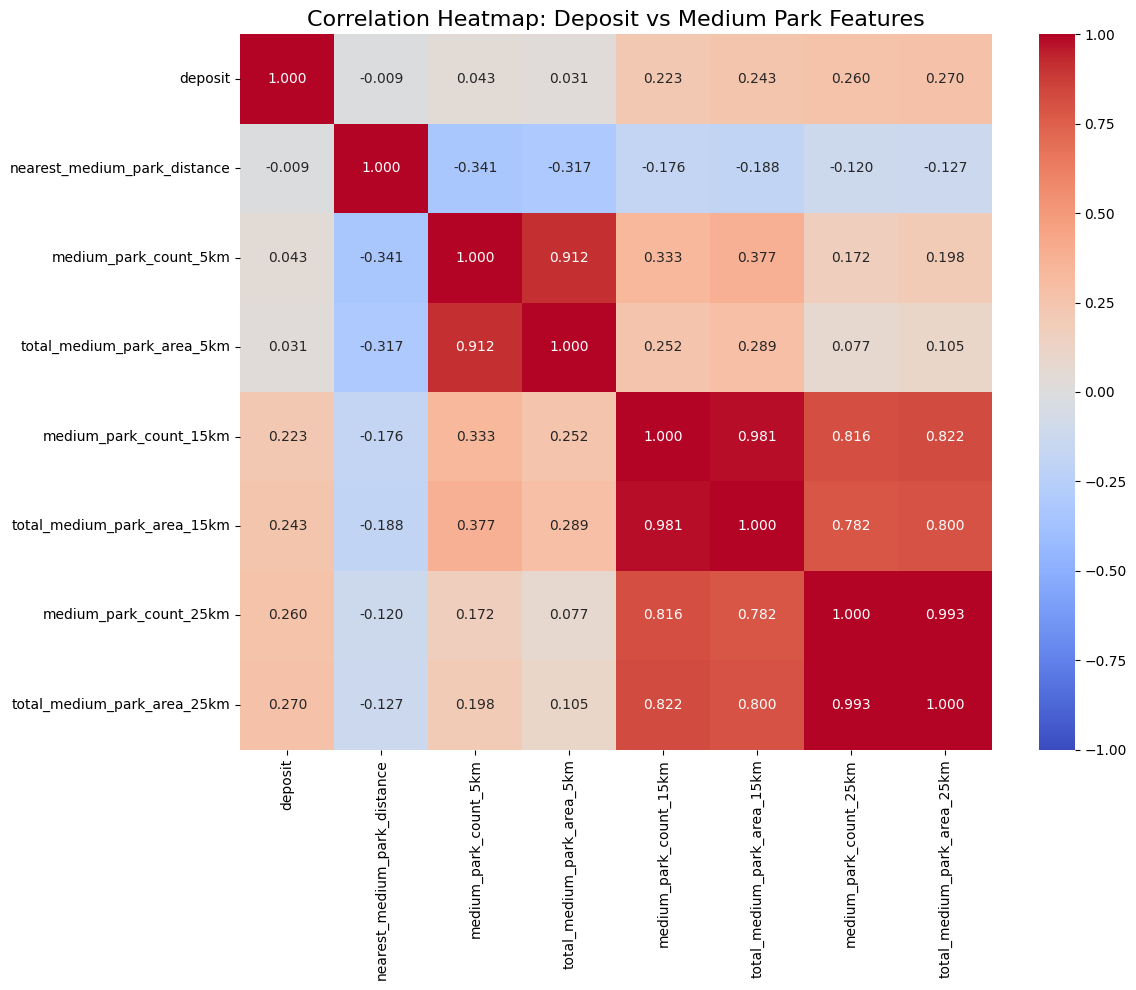
- total_medium_park_area_25km 0.270252
- medium_park_count_25km 0.260282
- total_medium_park_area_15km 0.242637
너무 낮다. 소공원으로 넘어가자.
소공원 5,15,25km
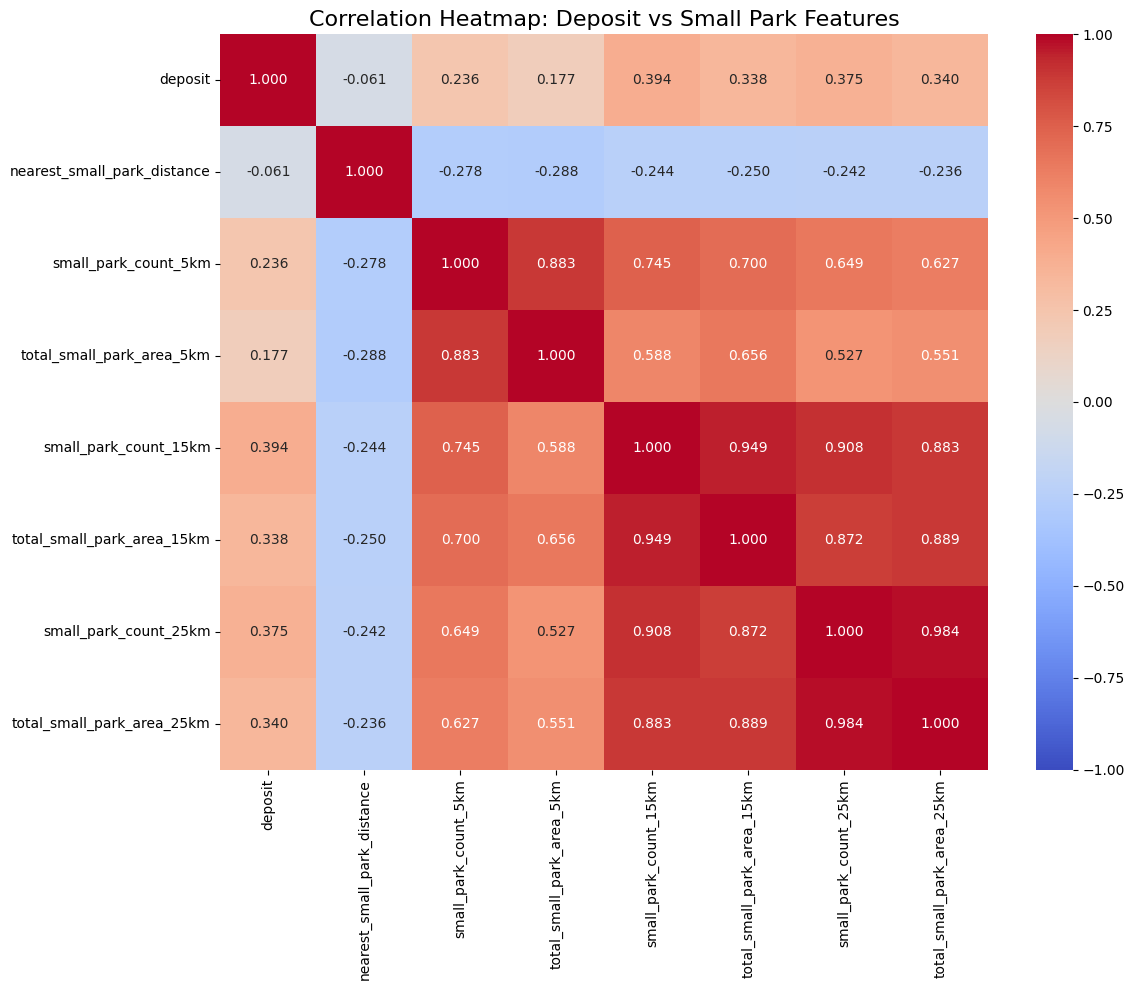
- small_park_count_15km 0.394039
- small_park_count_25km 0.374573
- total_small_park_area_25km 0.340177
오, 꽤나 높다. 근데 첨에 생각한건 소공원이면 가까운 게 더 상관관계가 높지 않을까 생각해서 한번 짧은 거리로 돌려봤다.
소공원 1,3,8,15km
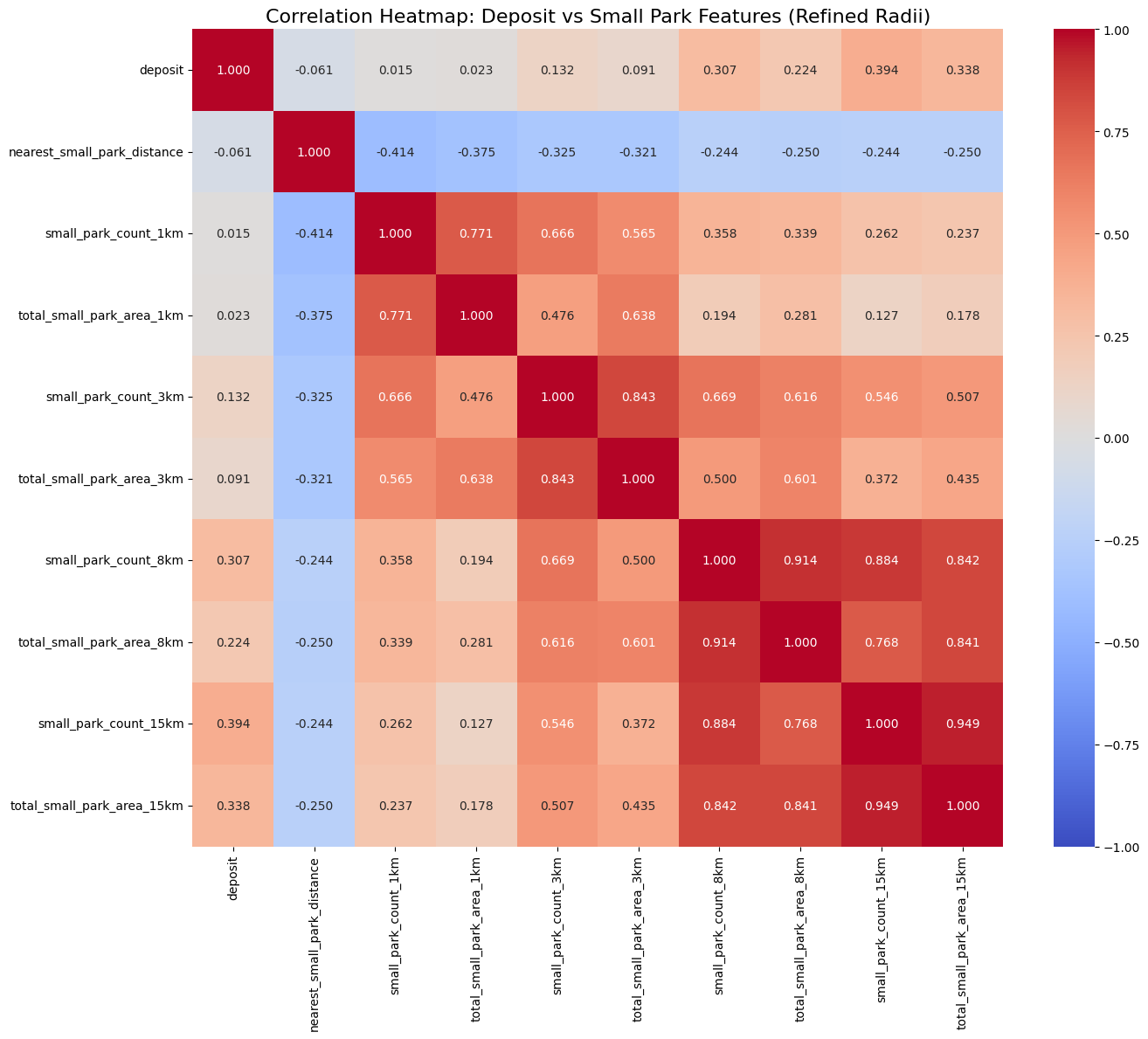
- small_park_count_15km 0.394039
- total_small_park_area_15km 0.337794
- small_park_count_8km 0.306508
- total_small_park_area_8km 0.223965
흠.. 15km가 가장 높게 나왔다. 왜지..? 소공원이면 면적1만 미만이니까 가볍게 갈만한 그런 곳이니까 집앞에 있어야 되는 거아닌가? 15km면 차타고 가야되는 거리 아닌가?
해서 우리집으로도 한번 상상해봄. (심심해서 해봄)
# 찾고자 하는 좌표
target_lat = 37.5298
target_lon = 126.7949
# 정확한 좌표 매칭
exact_match = park_df[(park_df['latitude'] == target_lat) & (park_df['longitude'] == target_lon)]
if not exact_match.empty:
print("정확한 좌표 매칭 결과:")
print(exact_match[['latitude', 'longitude', 'area']])
else:
print("정확한 좌표 매칭 결과가 없습니다. 근사값을 찾아보겠습니다.")
# 근사값 찾기
park_df['distance'] = np.sqrt((park_df['latitude'] - target_lat)**2 + (park_df['longitude'] - target_lon)**2)
closest_match = park_df.loc[park_df['distance'].idxmin()]
print("\n가장 가까운 좌표의 공원 정보:")
print(f"Latitude: {closest_match['latitude']}")
print(f"Longitude: {closest_match['longitude']}")
print(f"Area: {closest_match['area']}")
print(f"Distance from target: {closest_match['distance']}")
# 추가적으로, 해당 좌표 주변의 공원들의 정보도 출력해보겠습니다
nearby_parks = park_df[park_df['distance'] < 0.001] # 약 100m 반경 내
if not nearby_parks.empty:
print("\n약 100m 반경 내 공원들:")
print(nearby_parks[['latitude', 'longitude', 'area']])
else:
print("\n100m 반경 내에 다른 공원이 없습니다.")
가장 가까운 좌표의 공원 정보: Latitude: 37.52978294 Longitude: 126.7961418 Area: 119392.0
우리집앞에 있는 그나마 가장 큰 공원을 찾아보니 11만이었다. 2km거리정도에 면적 10만정도.. 이게 가장 이상적인 그거라고 생각되긴 했다.
근데 왜 소공원이 15km가 가장 상관관계가 높게 나오는거지?
이해안되서 걍 직접 찍어봄
이해가 안 되서 걍 직접 인구 수 높은 도시 4개랑 인구 수 낮은 도시 10개정도를 직접 위도 경도 찍어서 서치해봤다.
500m 반경 내 소공원 수
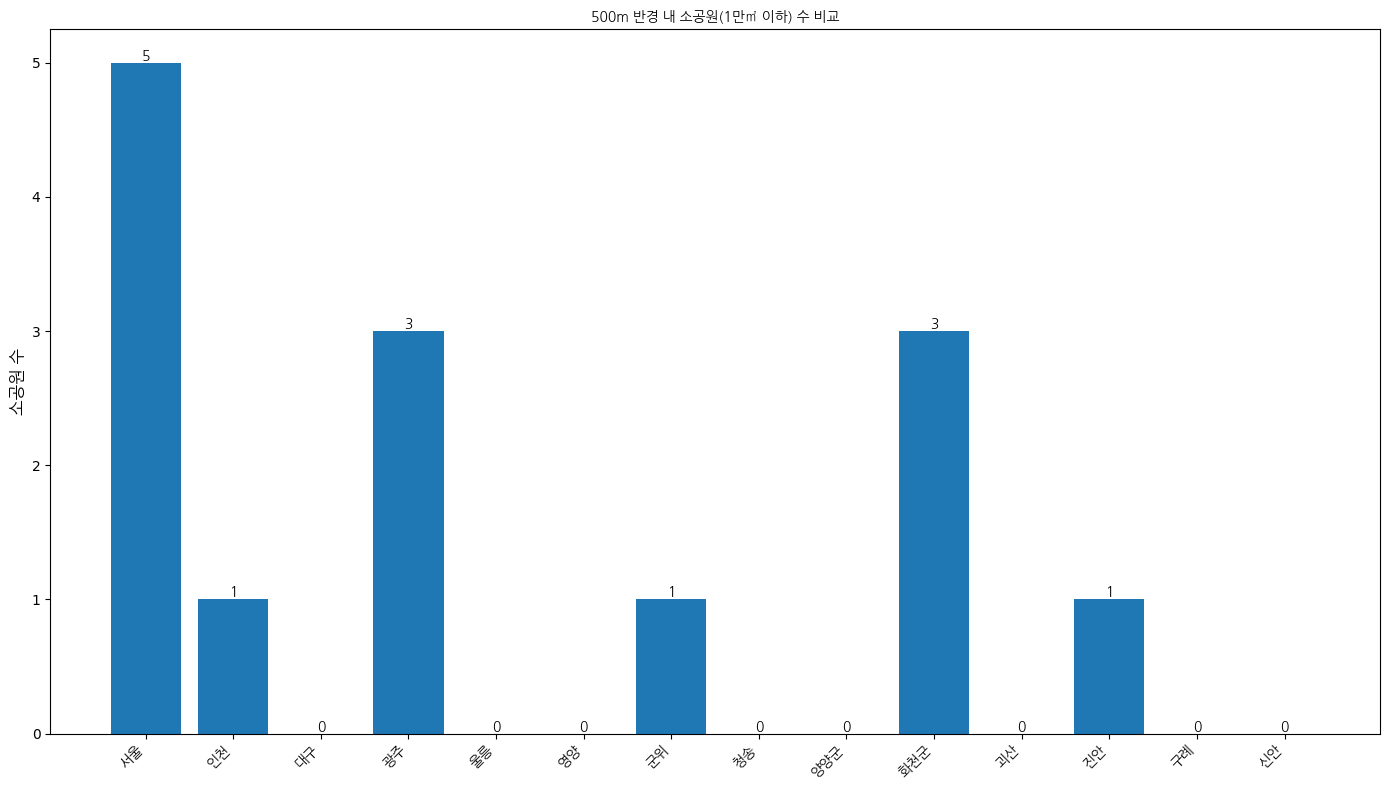
당장 여기서 뭔가 느끼긴 했다. 화천이 인천, 대구 보다 소공원의 수가 높게 나왔다. 500m이내는 너무 짧아서 데이터로써 부적절하겠구나.
1km 반경 내 소공원 수
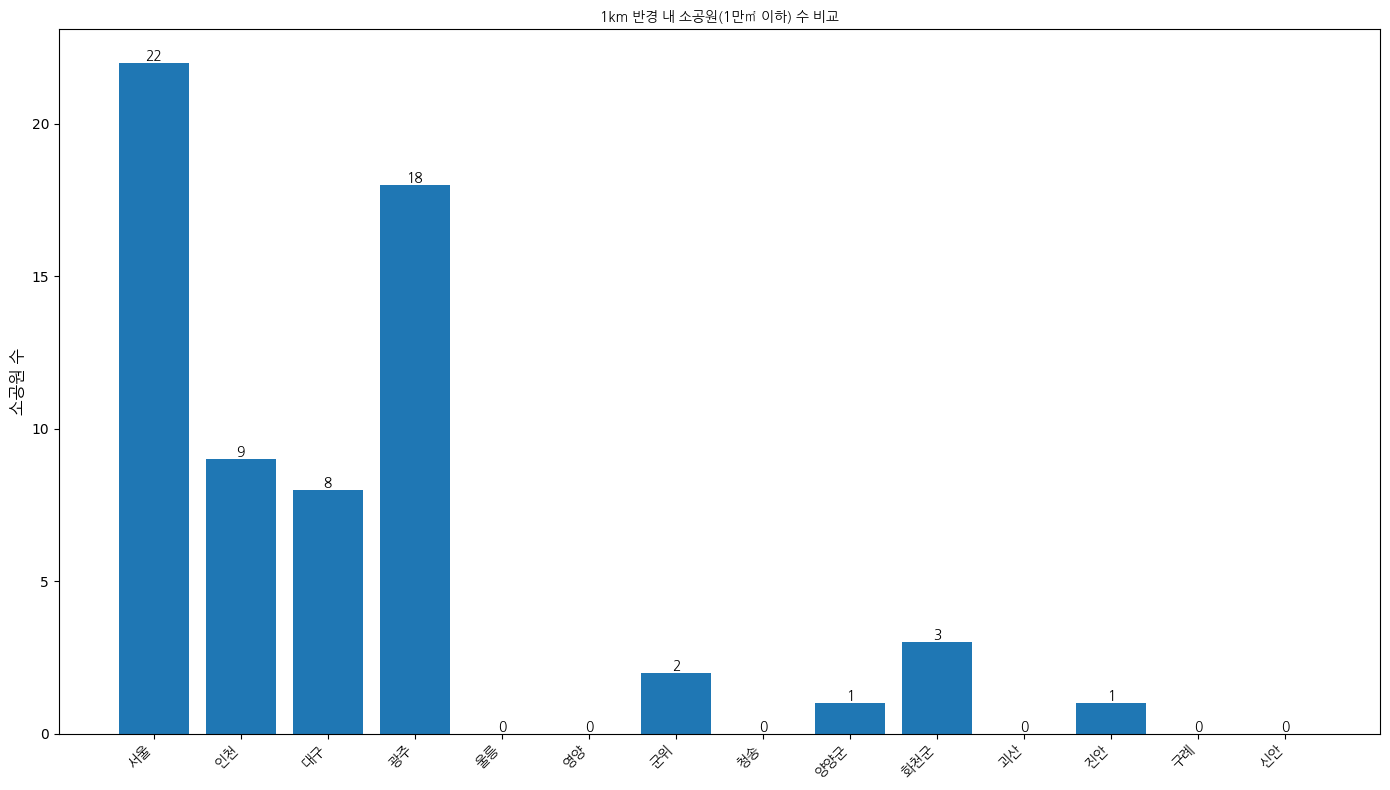
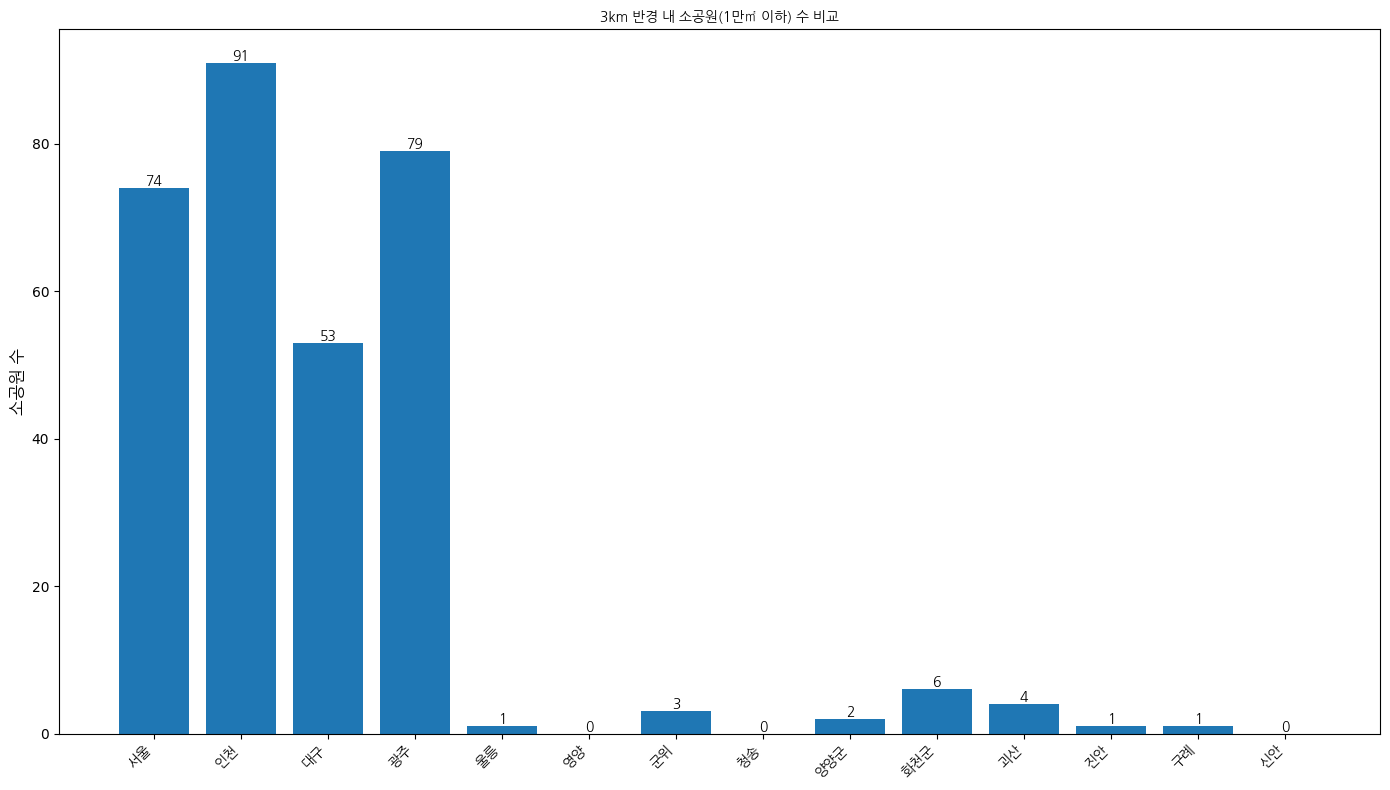
3km 반경 내 소공원 수
5km 반경 내 소공원 수
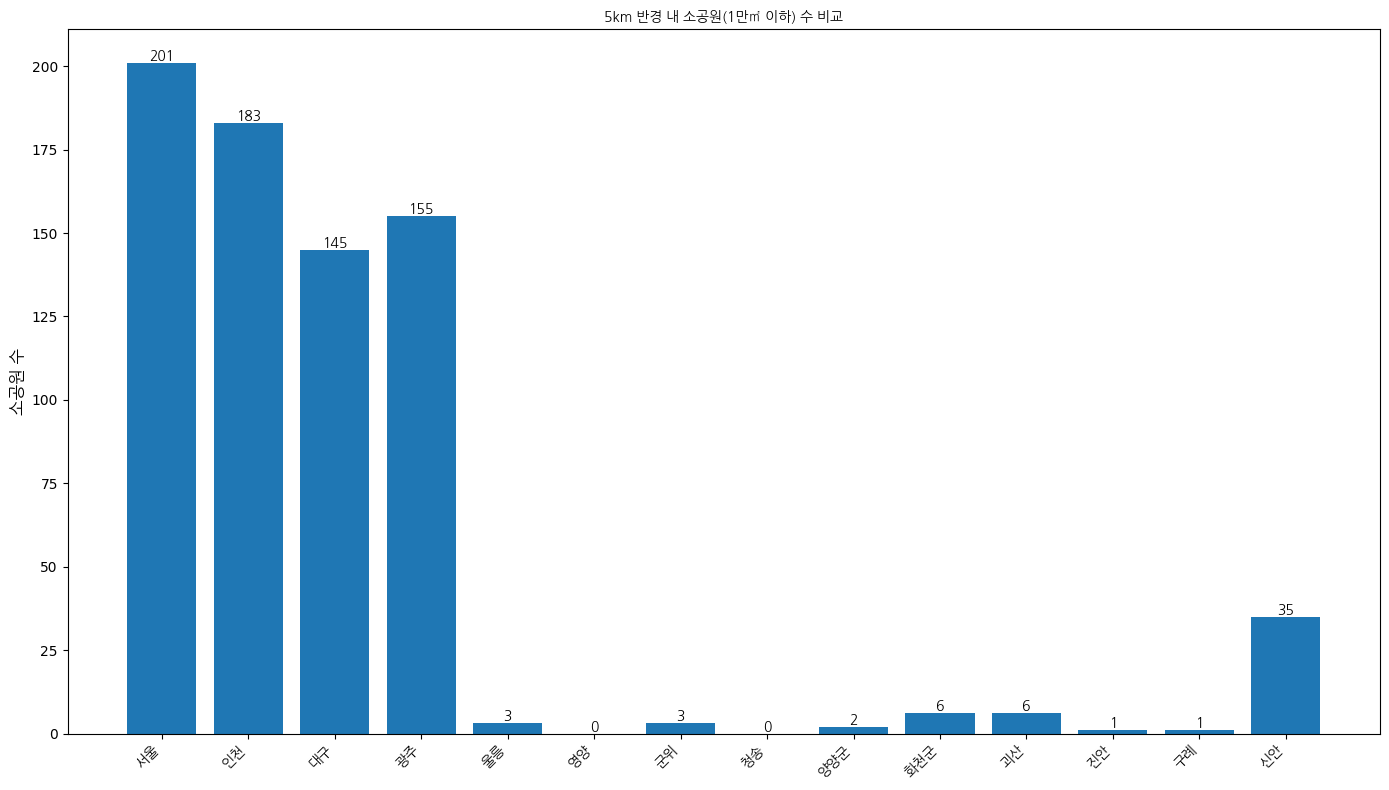
여기서 신안이 갑자기 늘어난 건 근처 목포가 5km내에 들어가서 목포의 공원 수가 데이터로 들어간 듯
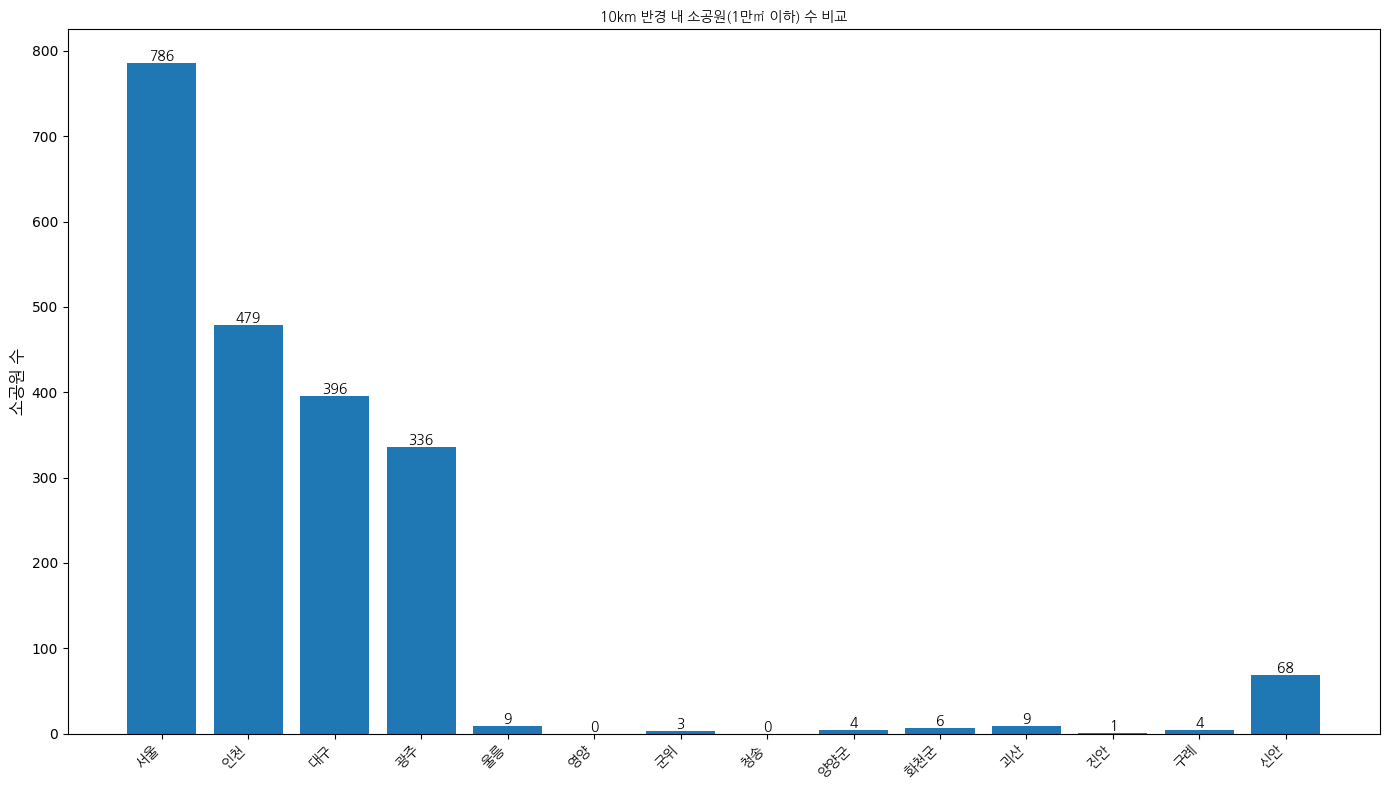
10km 반경 내 소공원 수
15km 반경 내 소공원 수
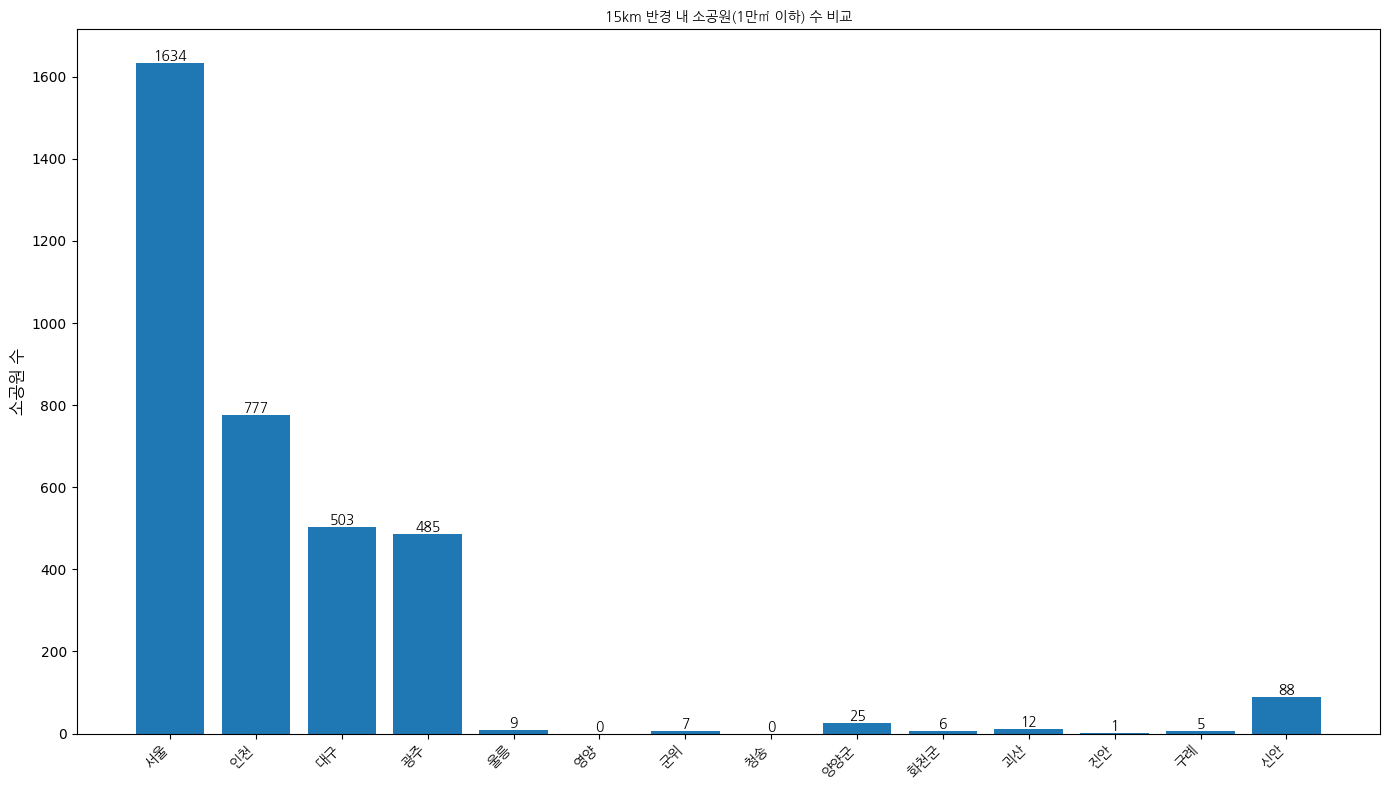
음.. 10, 15km가 더 예쁘게 나왔다. 왜지? 이유는 정리에 써놓긴 했다. 맞는진 모르겠지만.
정리
대공원은 상관관계 높게 나옴. 15,20,25km쪽이 특히 잘 나옴. 공원의 수랑 면적 둘 다 나중에 쓸만함.
중공원은 상관관계 낮게 나옴. 안쓸듯.
소공원은 상관관계 높게 나옴. 근데 보통 소공원은 걸어감에도 불구하고 15km쪽이 500m,1km보다 잘 나옴. 이유가 뭐냐면 너무 짧으면 아까 화천이 인천,대구보다 공원의 수가 많이 나온 것 처럼 잘못된 데이터로 나올 수 있음.
그리고 집앞에 괜찮은 소공원이 한두 개 있다 치자! -> 그러면 물론 거기사는 누군가의 삶의 긍정적인 영향을 끼칠 순 있지만 그게 전세값에 영향을 끼치지는 못한다.
오히려 15km 반경 내에 소공원이 많다! -> 15km내외에 있는 소공원에 내가 찾아가지는 않겠지! -> 그러나 소공원이 많이 조성된 만큼 내가 살고 있는 전셋집이 더 괜찮은 환경에 위치하고 있다 -> 그래서 더 비싼 전셋값. 이렇게 이해하는 게 맞는 것 같다.
소공원쪽 마지막 추론이 어려웠다. 공원은 이걸로 마무리할듯.