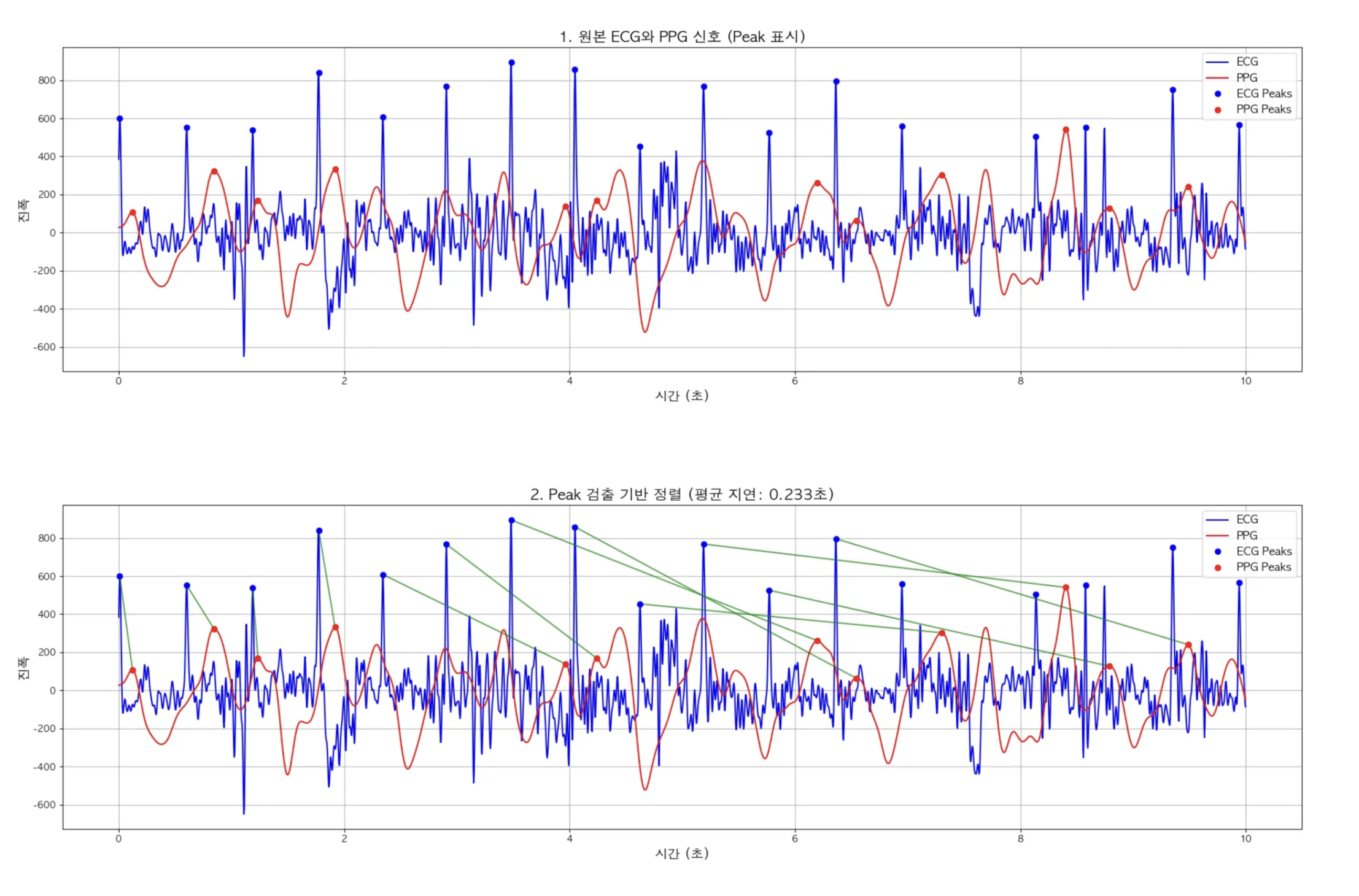
Peak 검출 기반 정렬 & 지연 시간 기반 정렬 탐색
시각화
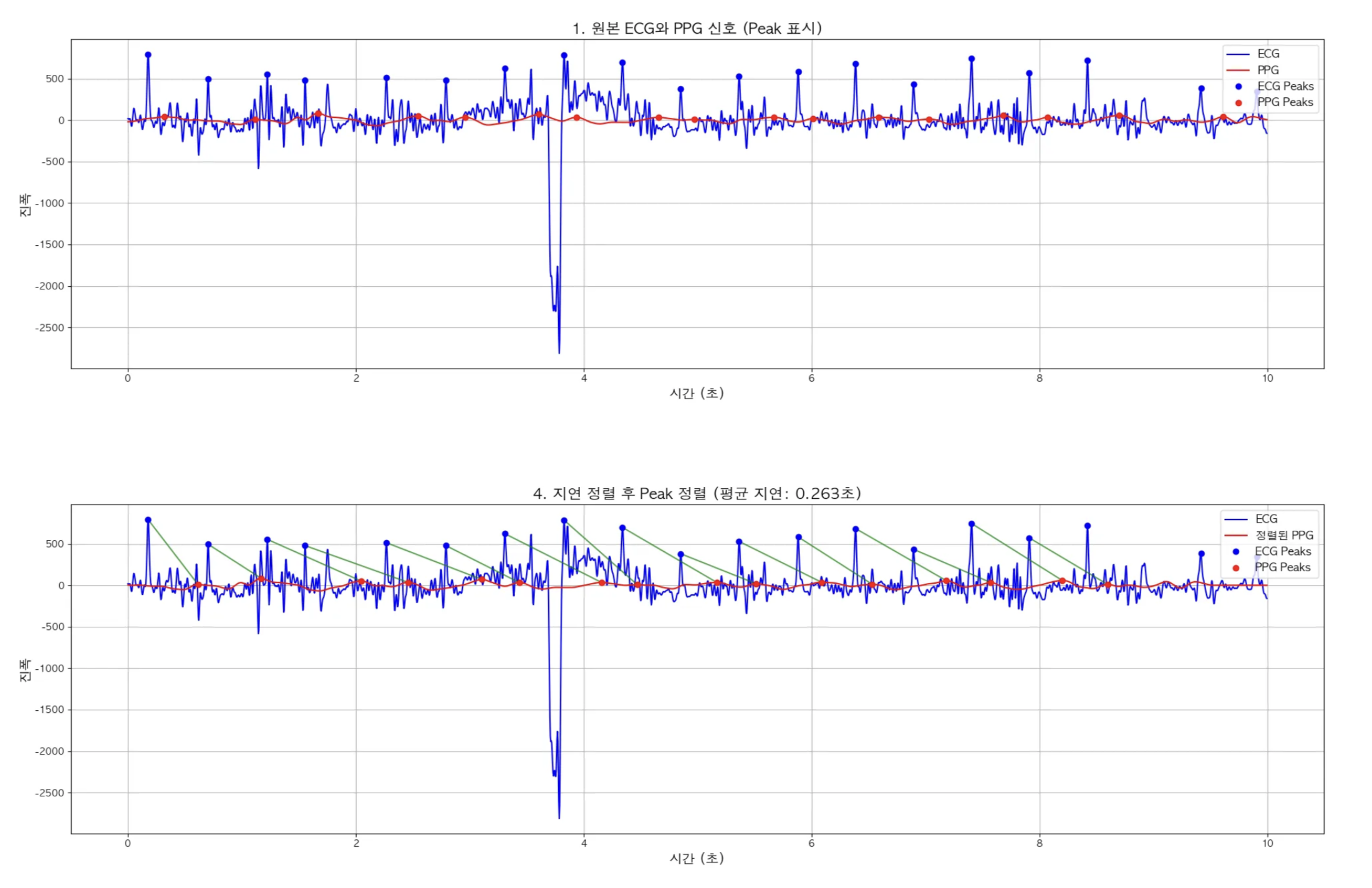
- 원본 ECG와 PPG 신호 (Peak 표시)
- Peak 검출 기반 정렬
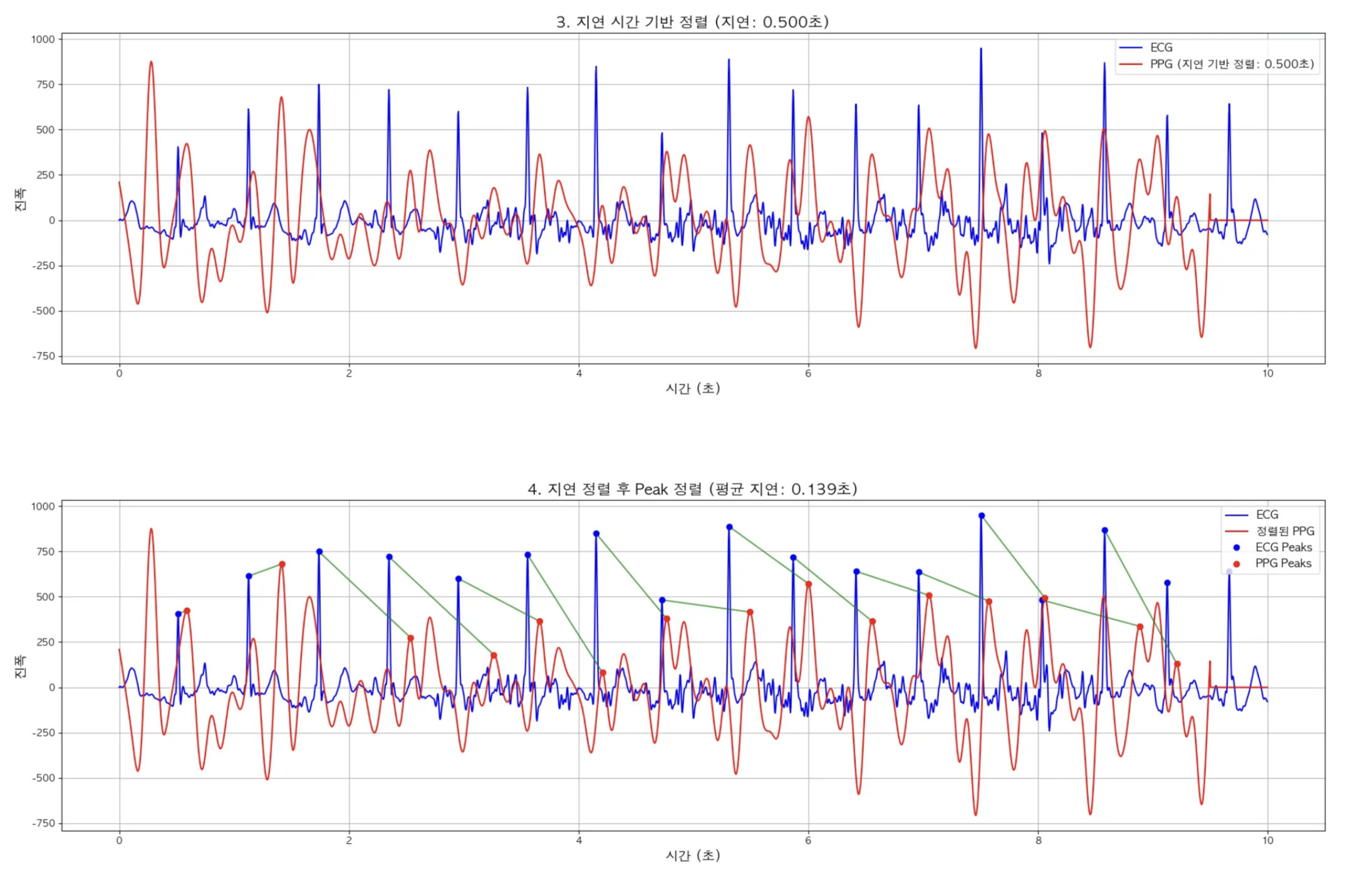
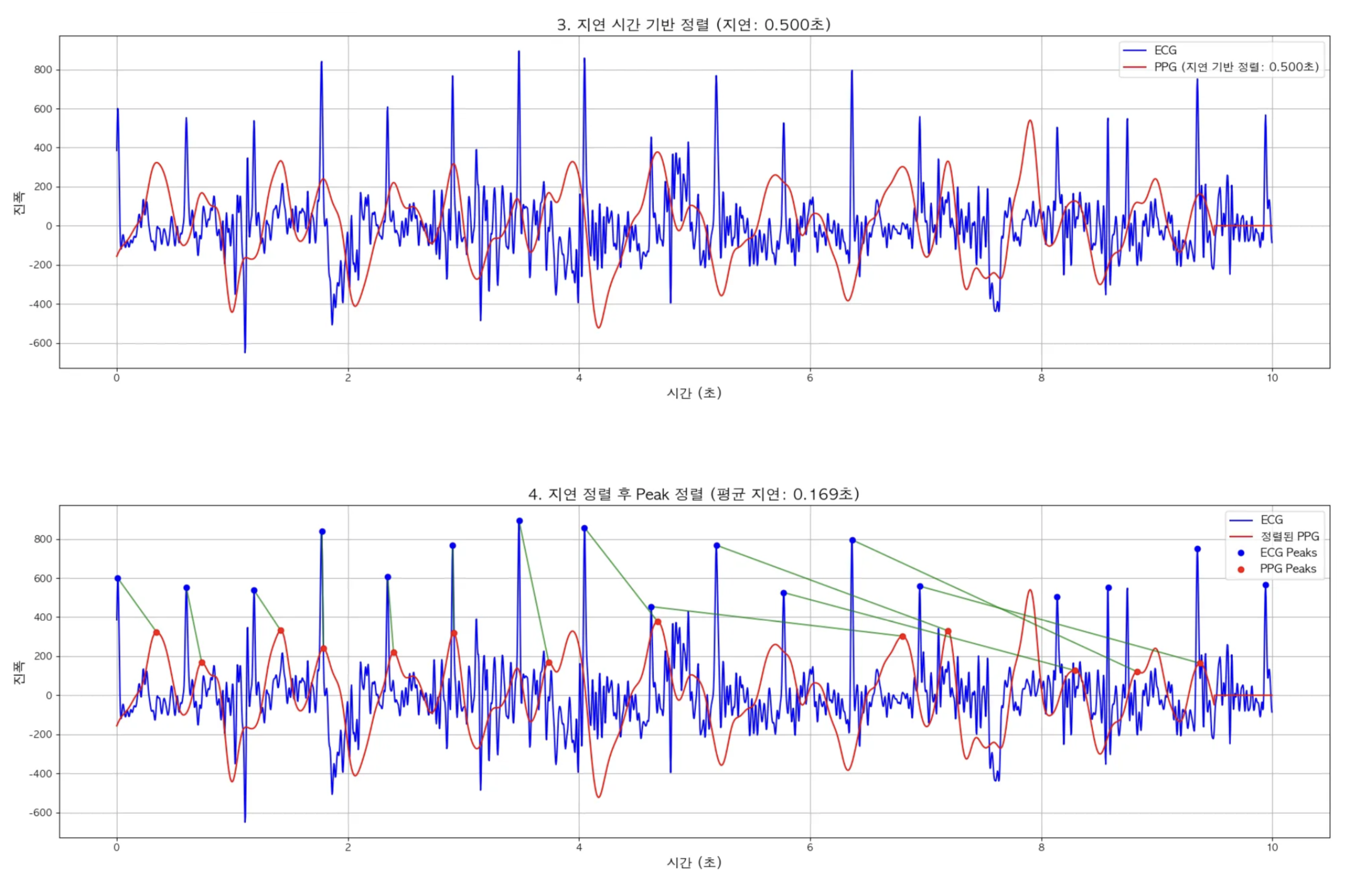
- 지연 시간 기반 정렬
- 지연 시간 기반으로 정렬 후 Peak 검출 기반 정렬
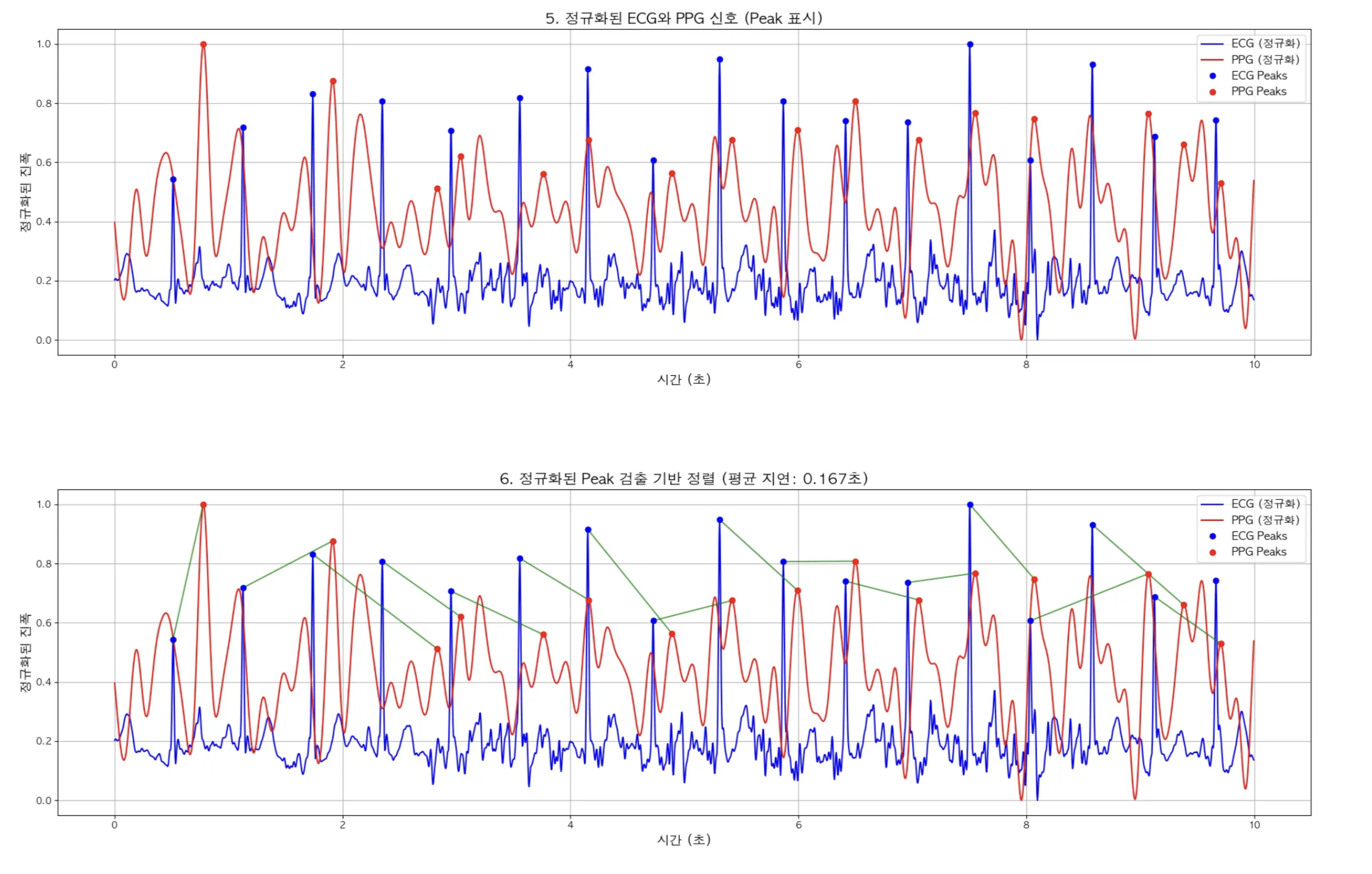
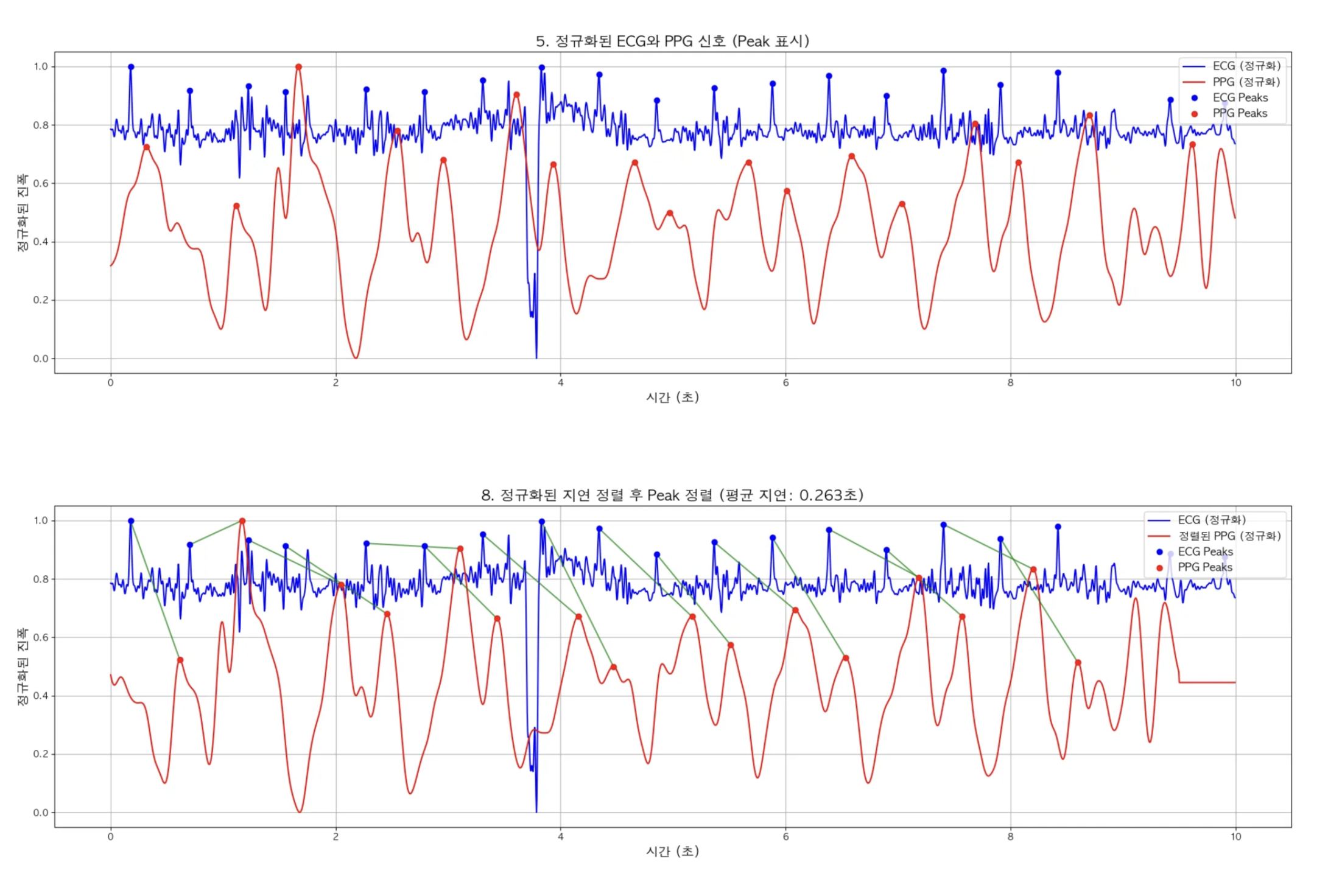
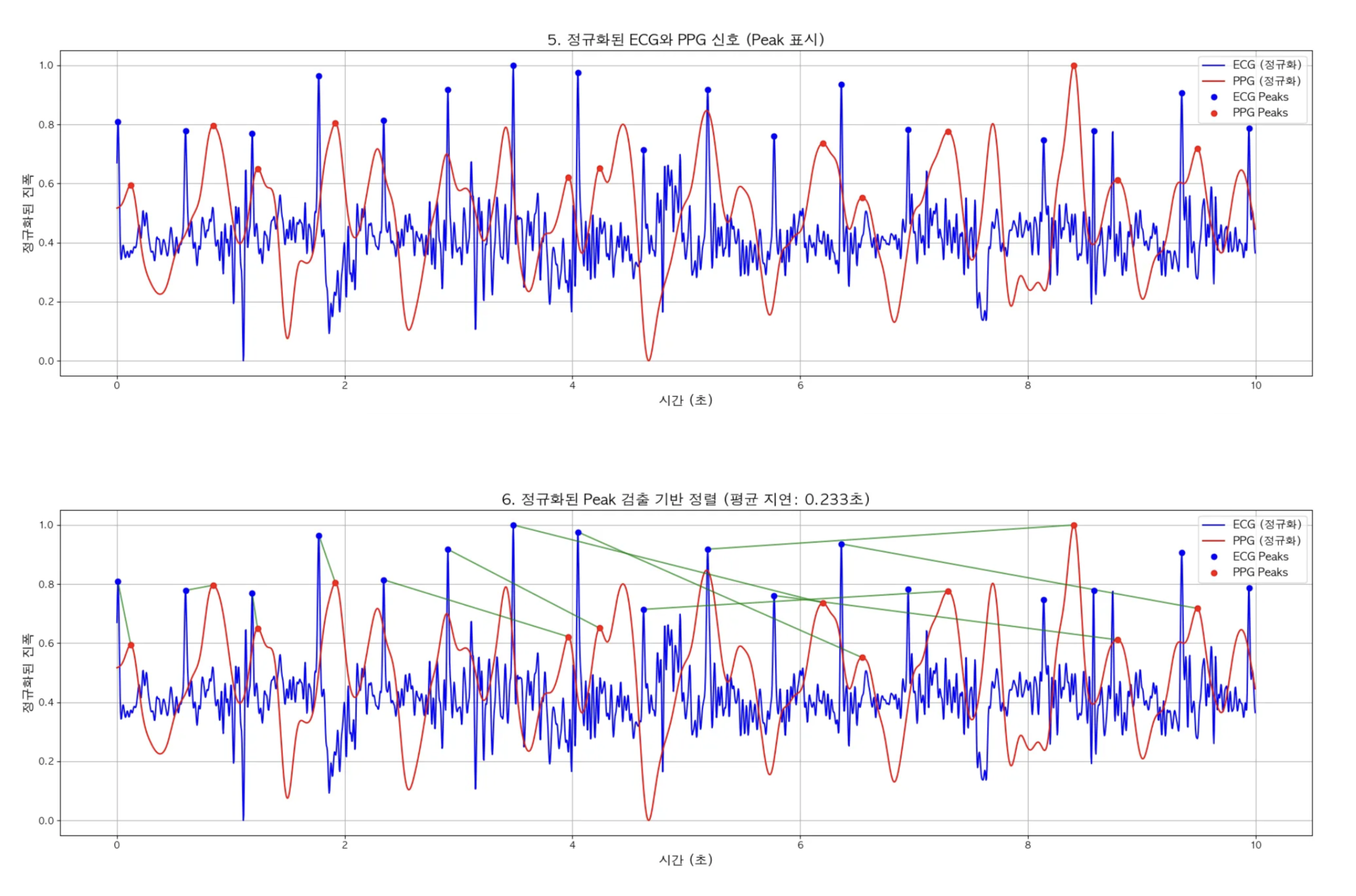
- 정규화된 ECG와 PPG 신호 (Peak 표시)
- 정규화된 Peak 검출 기반 정렬
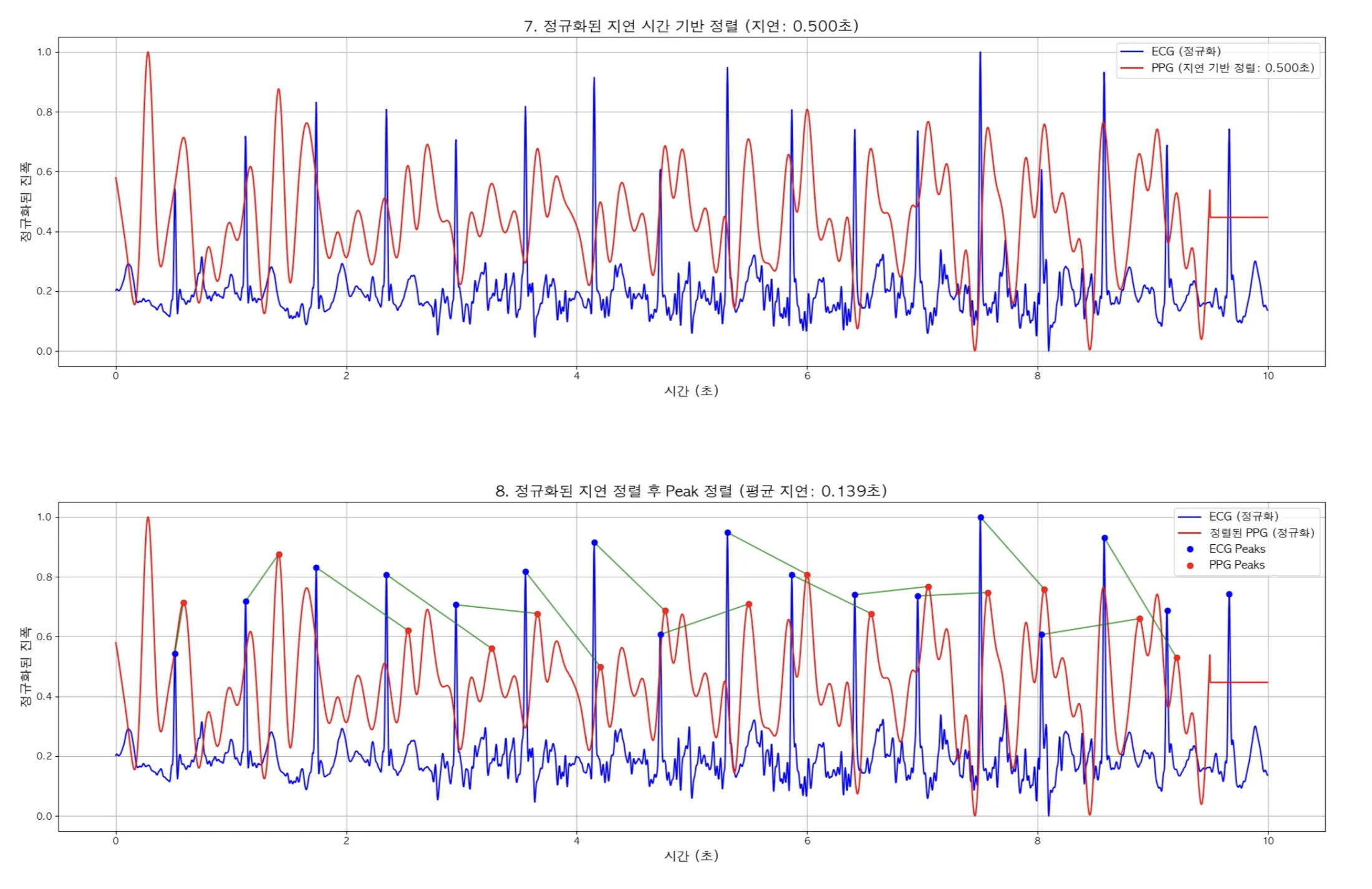
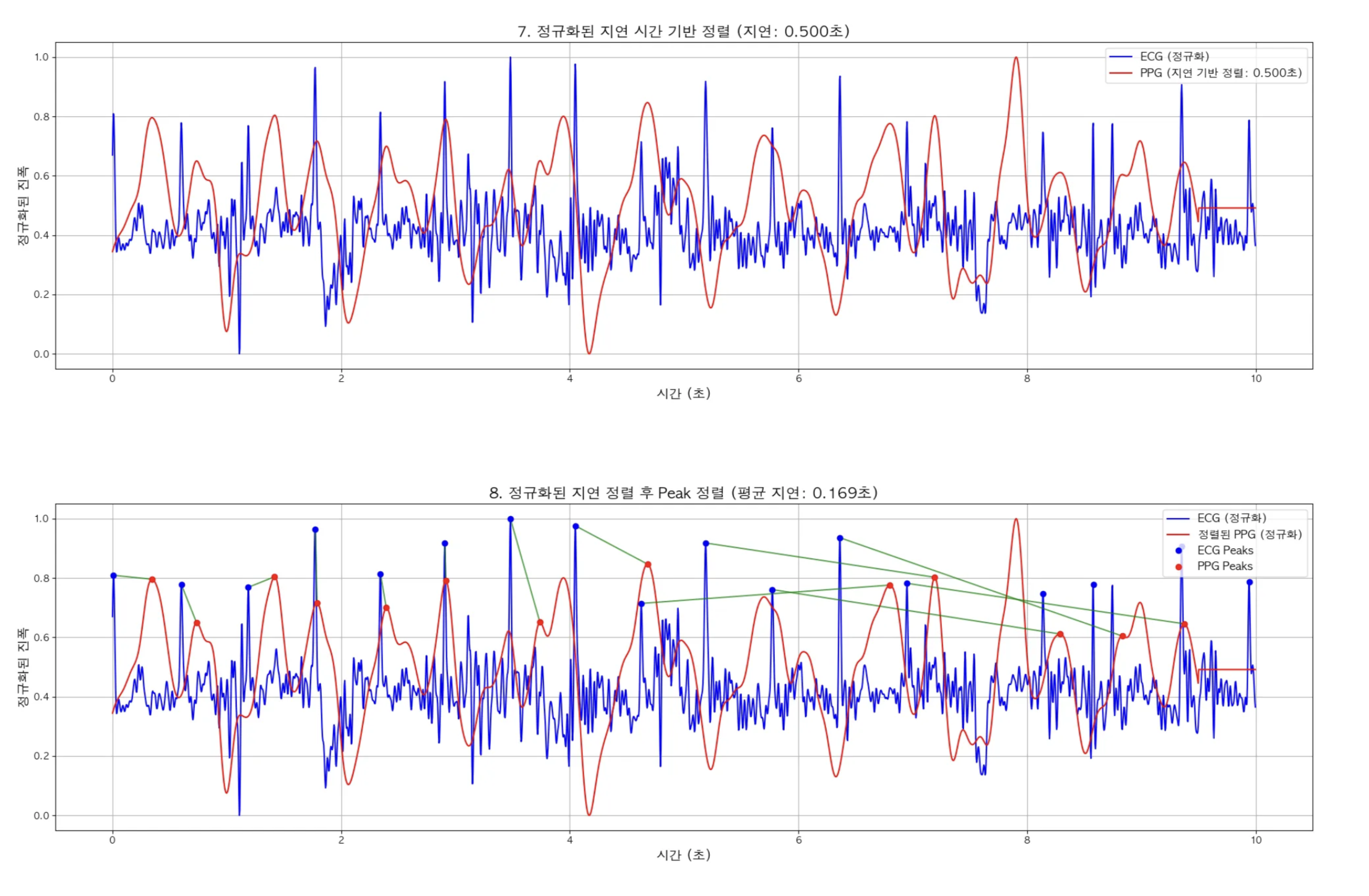
- 정규화된 지연 시간 기반 정렬
- 정규화된 지연 시간 기반으로 정렬 후 Peak 검출 기반 정렬
우선 현재 Peak 검출 방식을 대략적으로 설명하자면
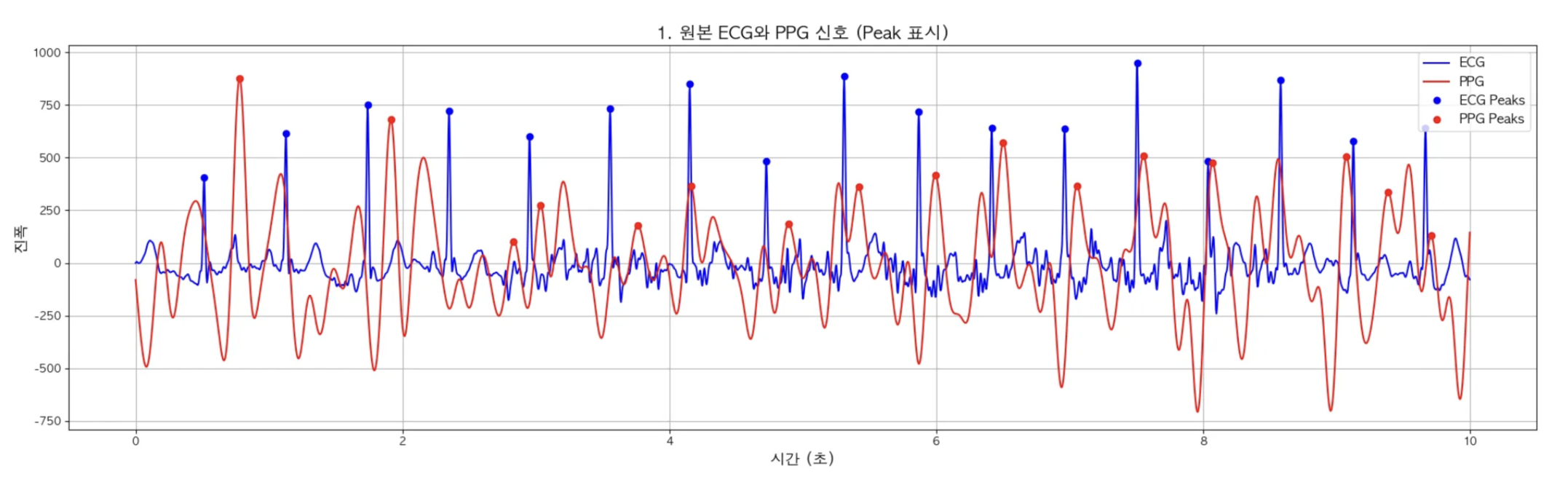
-
높이 기준(Height Threshold):
height=0.4*np.max(signal)- 이는 전체 신호의 최대값의 40%를 기준으로 검출
- 최대값이 1000 이라면 400 이상의 값만 peak를 검출
-
거리 기준(Distance Threshold):
distance=0.3*sampling_freq- 연속된 peak 간의 최소 거리를 샘플링 주파수의 30%로 설정하여 중복 검출을 방지
s3_run
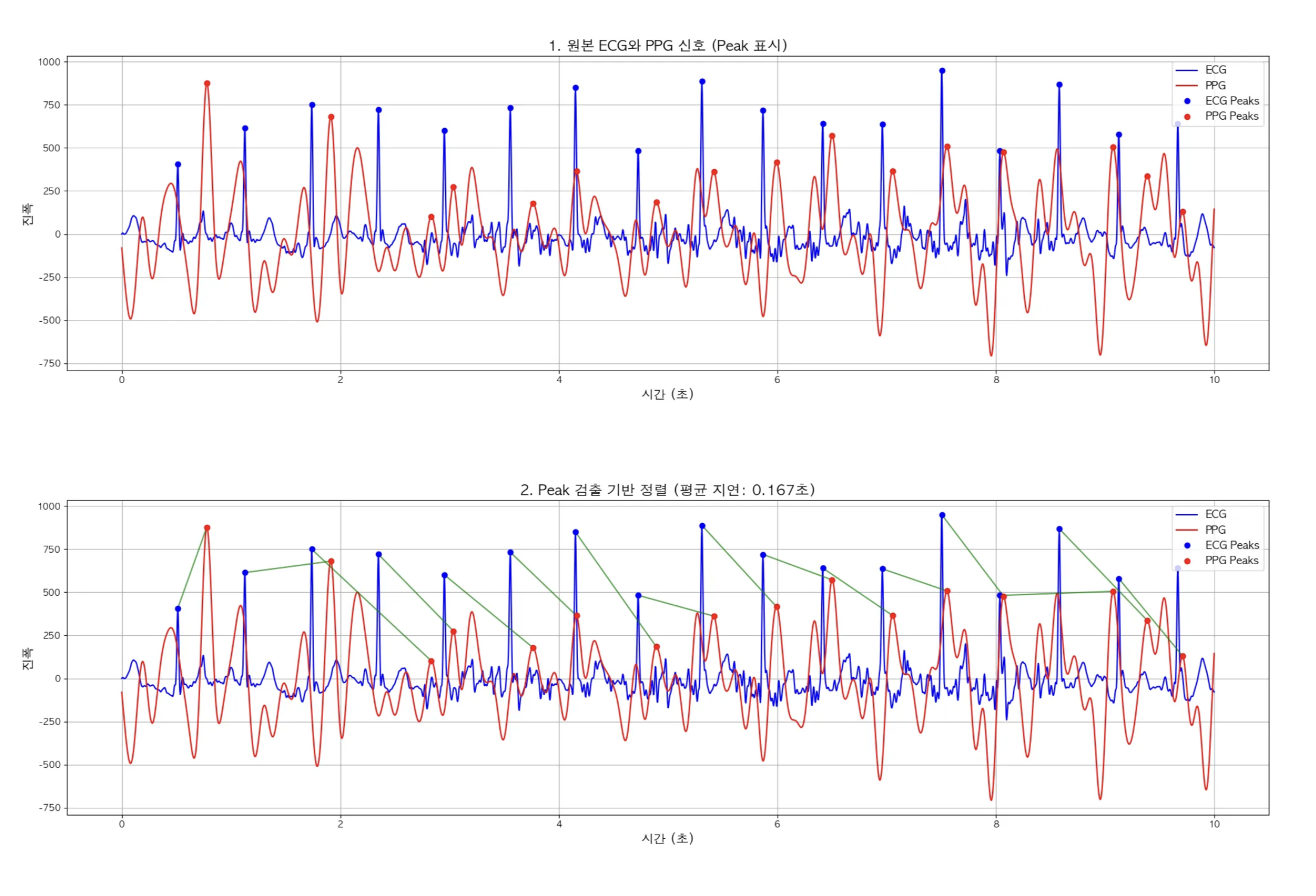
임의로 0.5초 PPG데이터를 왼쪽으로 Shift한 다음 Peak별로 매칭
정규화해서 Peak 매칭
정규화해서 0.5초 PPG데이터를 왼쪽으로 Shift한 다음 Peak별로 매칭
정규화를 한 이유
s3_high_resistance_bike
다 그런건 아닌데 정규화를 하지않으면 위와 같이 PPG 원본 데이터가 peak가 잘 보이지가 않아서 아래처럼 정규화해서 시각화를 진행함.
s3_low_resistance_bike
근데 지금 하는 작업은 결국 Shift해서 Peak의 x축을 최대한 일치시키는 작업인데
이건 그냥 ECG와 PPG의 그래프모양만 비슷하게 맞추는거 아닌가? 의미가 있나?
그래서 다시 주제를 잡고 파이프라인 다시 수정
1. 데이터 준비
- ECG와 PPG 동시 측정 데이터 수집
- 안정 상태와 활동 상태 데이터 포함
2. 기본 전처리
- 대역 통과 필터링 (노이즈 제거)
- 신호 정규화
3. ECG 기준 심박수 계산
- 검증된 R-피크 검출 알고리즘 적용
- 심박수 계산 (분당 비트 수)
4. PPG 피크 검출 알고리즘 구현
- 방법 1: 현재 사용 중인 고정 임계값 방식
- 방법 2: 적응형 임계값 (10초 윈도우 내 로컬 최대값 기반)
- 방법 3: 기울기 변화 기반 검출 (1차 미분 활용)
5. 성능 평가
- 심박수 추정 오차 계산 (ECG vs PPG)
- 오차 지표: 평균절대오차(MAE), 최대오차
- 시각화: Bland-Altman 플롯
6. 최적화
- 각 방법의 파라미터 조정
- 최적 알고리즘 선택
7. 검증
- 다른 데이터셋에서 성능 확인
- 실시간 처리 가능성 평가
1. 데이터 준비
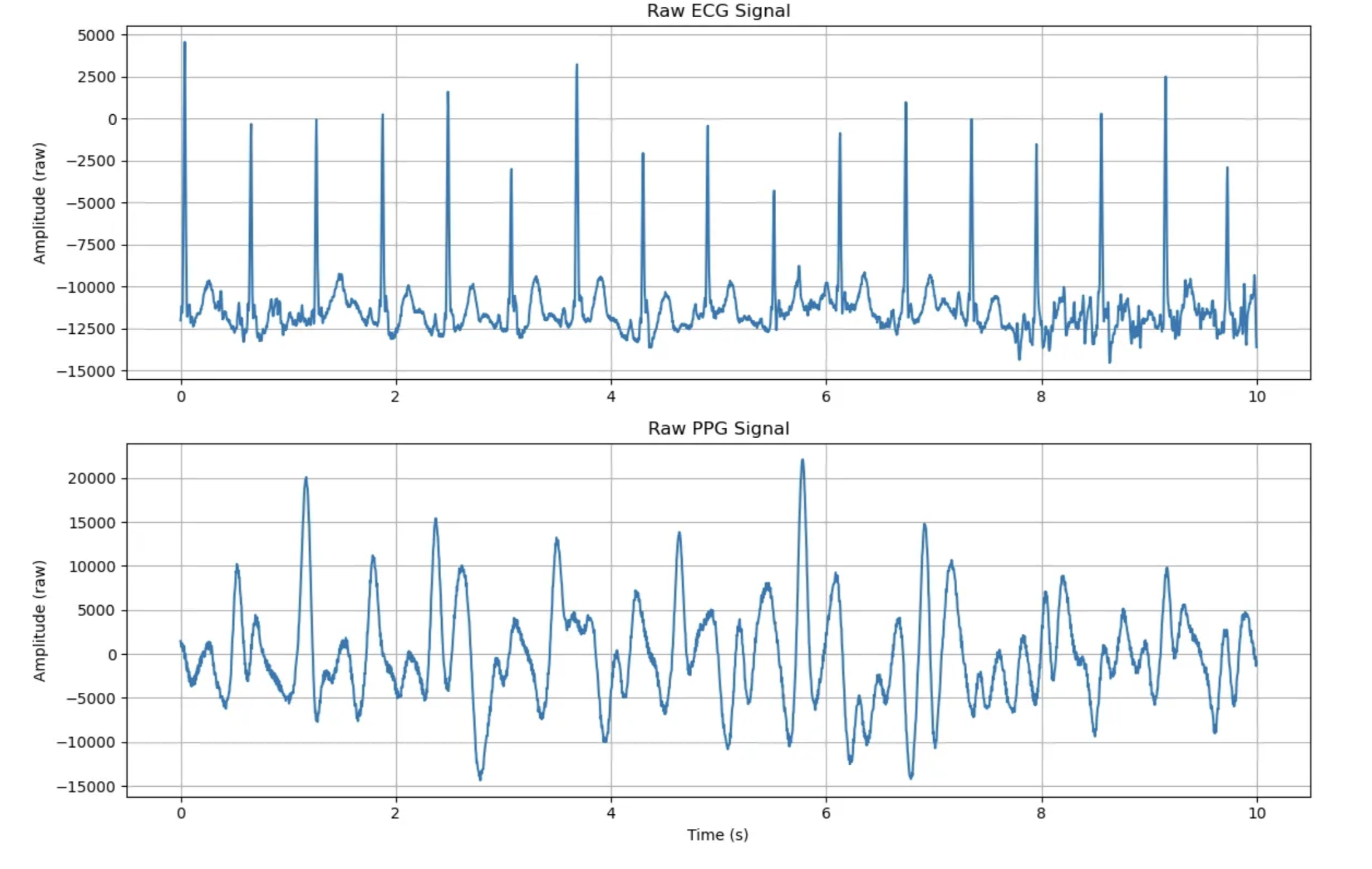
- s3_run.dat 파일(2,357,790 바이트)에서 ECG와 PPG 동시 측정 데이터를 성공적으로 로드
- 총 78,593개의 샘플이 수집되었으며, 이는 256Hz 샘플링 레이트에서 약 5분 분량
2. 기본 전처리
- 노치 필터로 50Hz와 60Hz 전원 노이즈 제거
- ECG: 0.5-40Hz 밴드패스 필터 적용
- PPG: 0.8-3.5Hz 밴드패스 필터 적용 (달리기 중 아티팩트 감소)
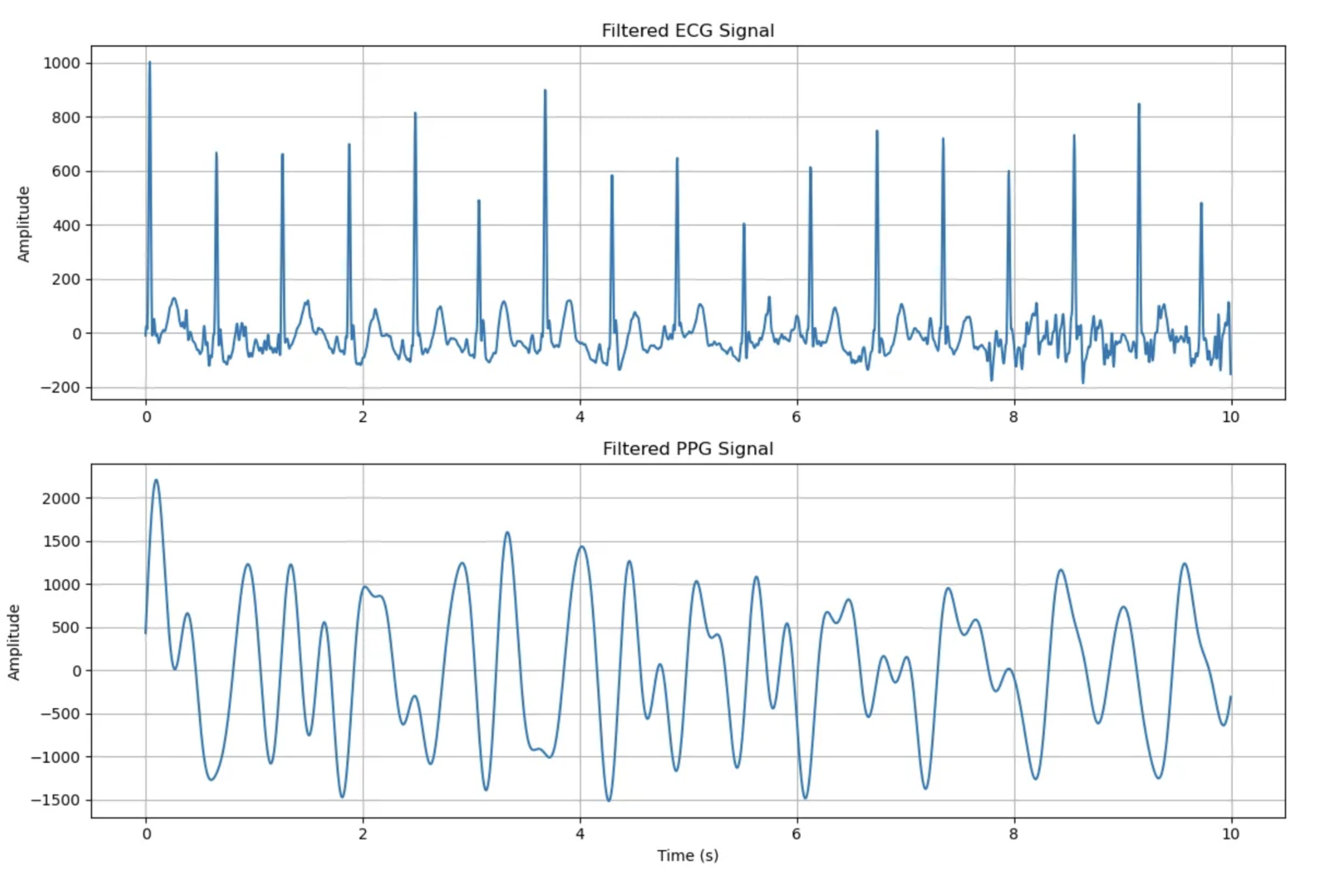
3. 현재 알고리즘으로 ECG, PPG 피크 검출
-
높이 기준(Height Threshold):
height=0.4*np.max(signal)- 이는 전체 신호의 최대값의 40%를 기준으로 검출
- 최대값이 1000 이라면 400 이상의 값만 peak를 검출
-
거리 기준(Distance Threshold):
distance=0.3*sampling_freq- 연속된 peak 간의 최소 거리를 샘플링 주파수의 30%로 설정하여 중복 검출을 방지
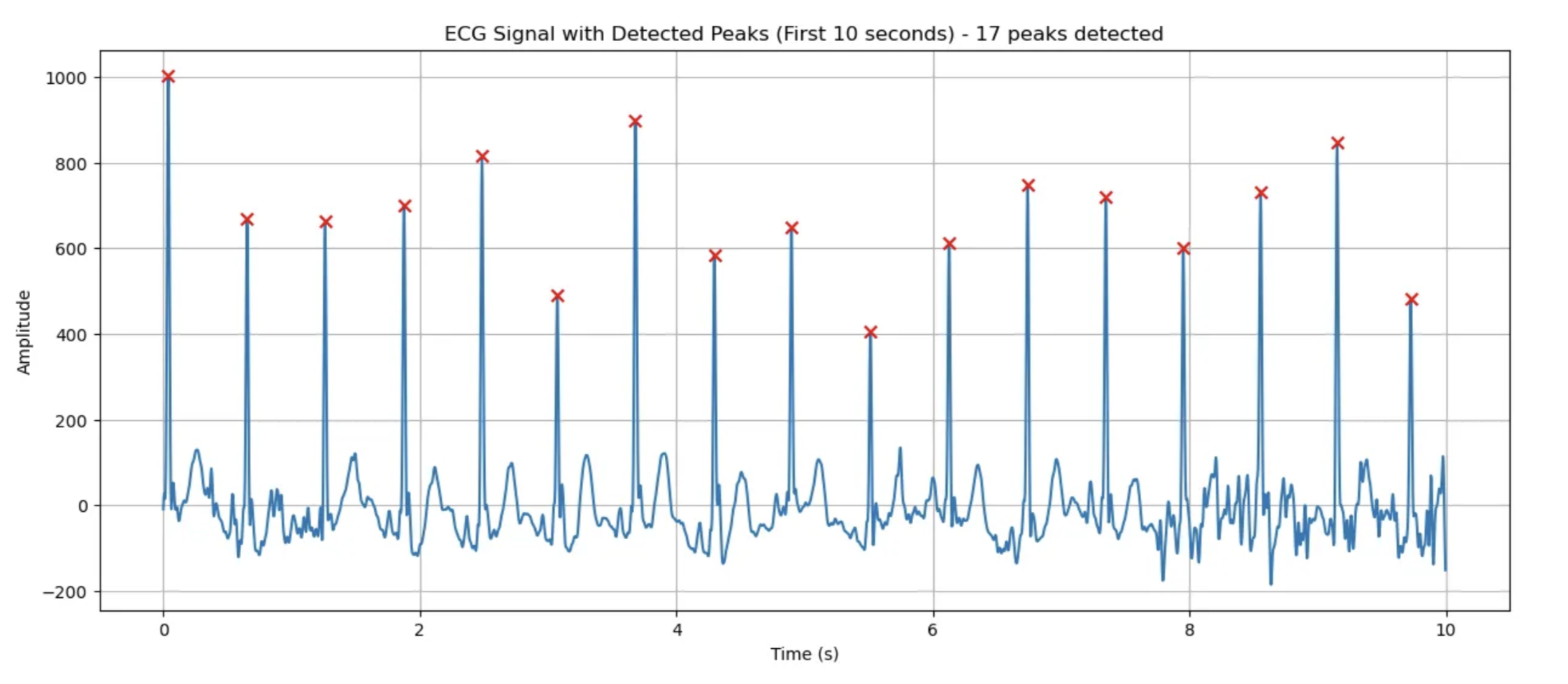
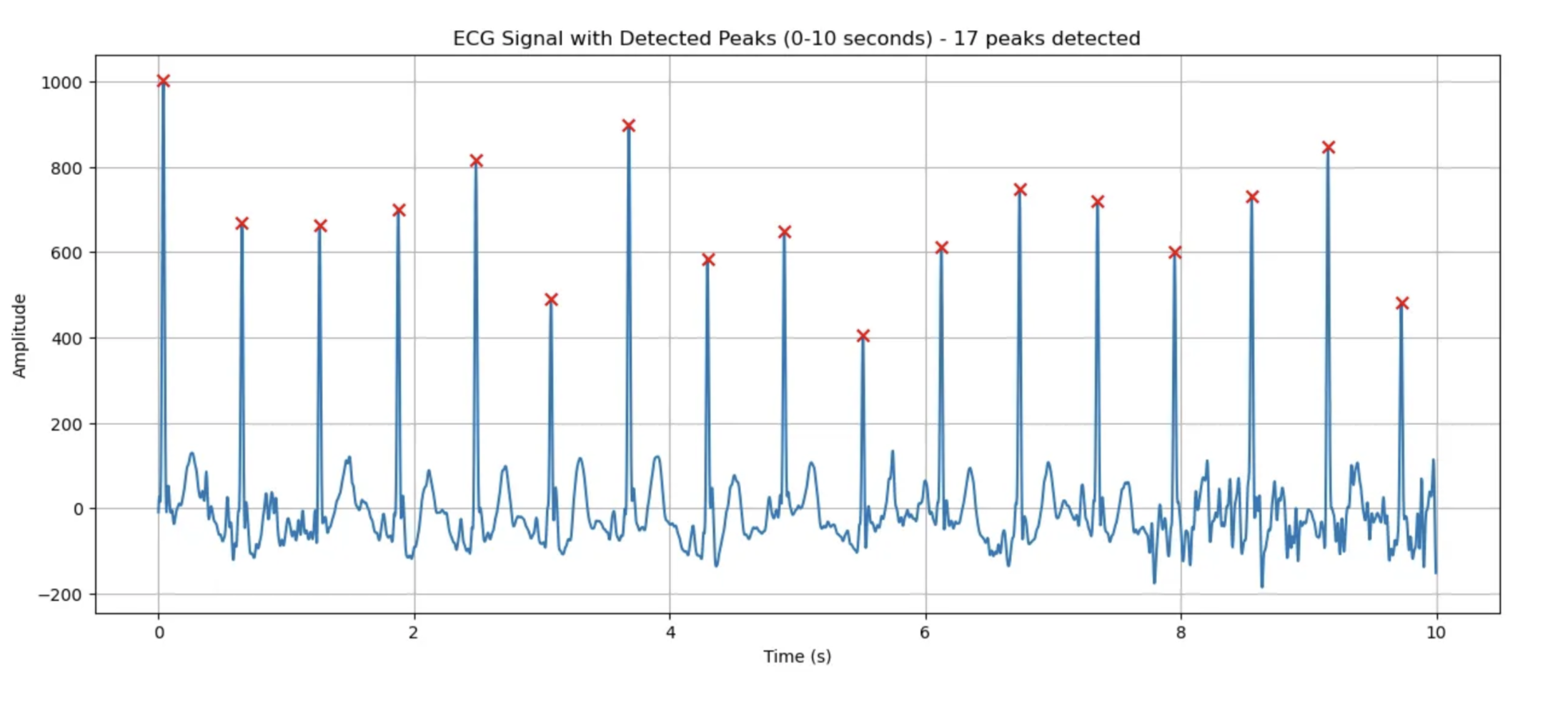
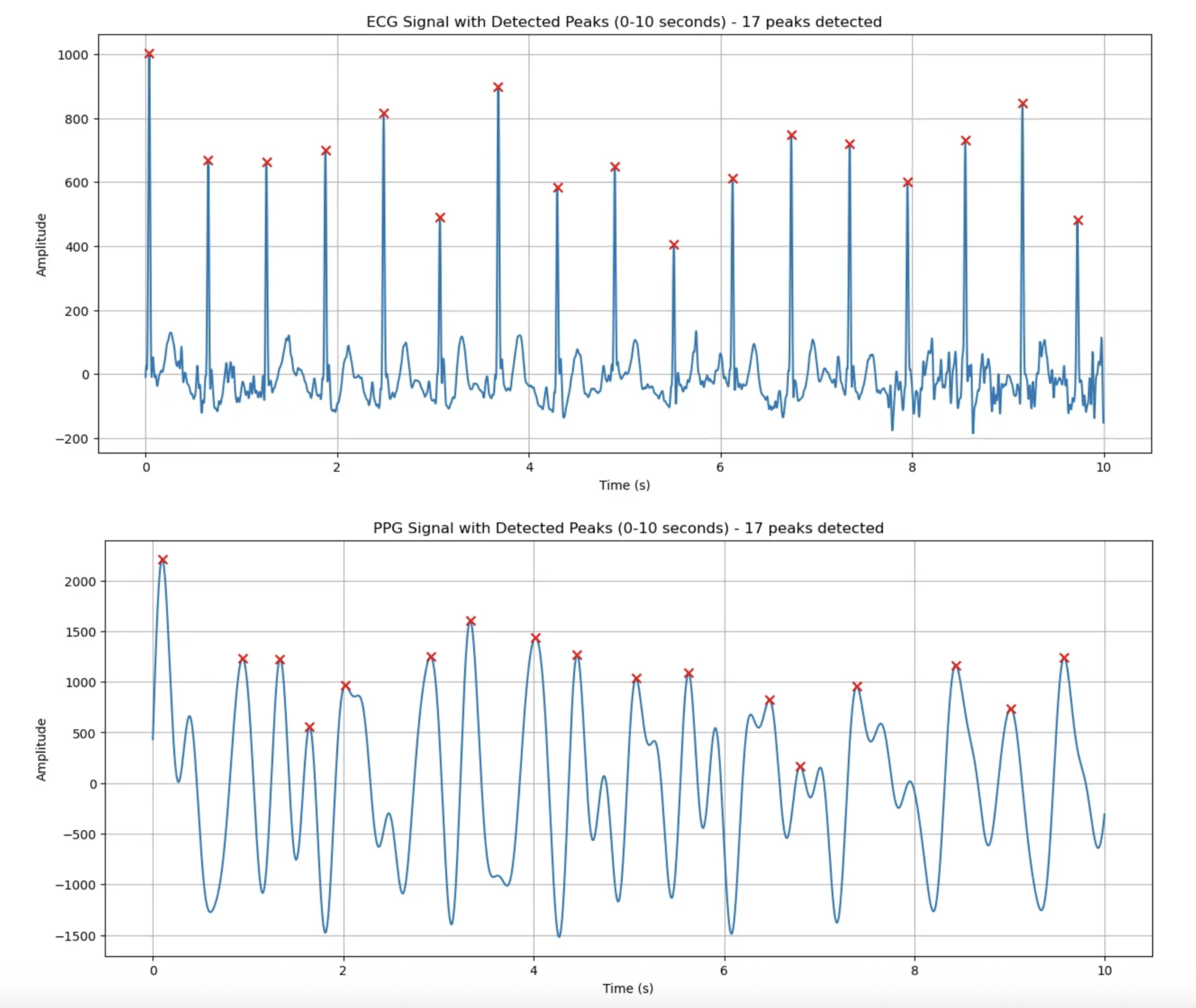
ECG 피크 검출 결과:
- 분석 구간: 처음 10초
- 높이 임계값: 401.41 (최대값의 40%)
- 거리 임계값: 76 샘플 (0.30초)
- 검출된 피크 수: 17개
- 피크 간 평균 거리: 0.61초
- 추정 심박수: 99.1 BPM
PPG 피크 검출 결과
- 분석 구간: 처음 10초
- 높이 임계값: 884.51 (최대값의 40%)
- 거리 임계값: 76 샘플 (0.30초)
- 검출된 피크 수: 13개
- 피크 간 평균 거리: 0.79초
- 추정 심박수: 76.0 BPM
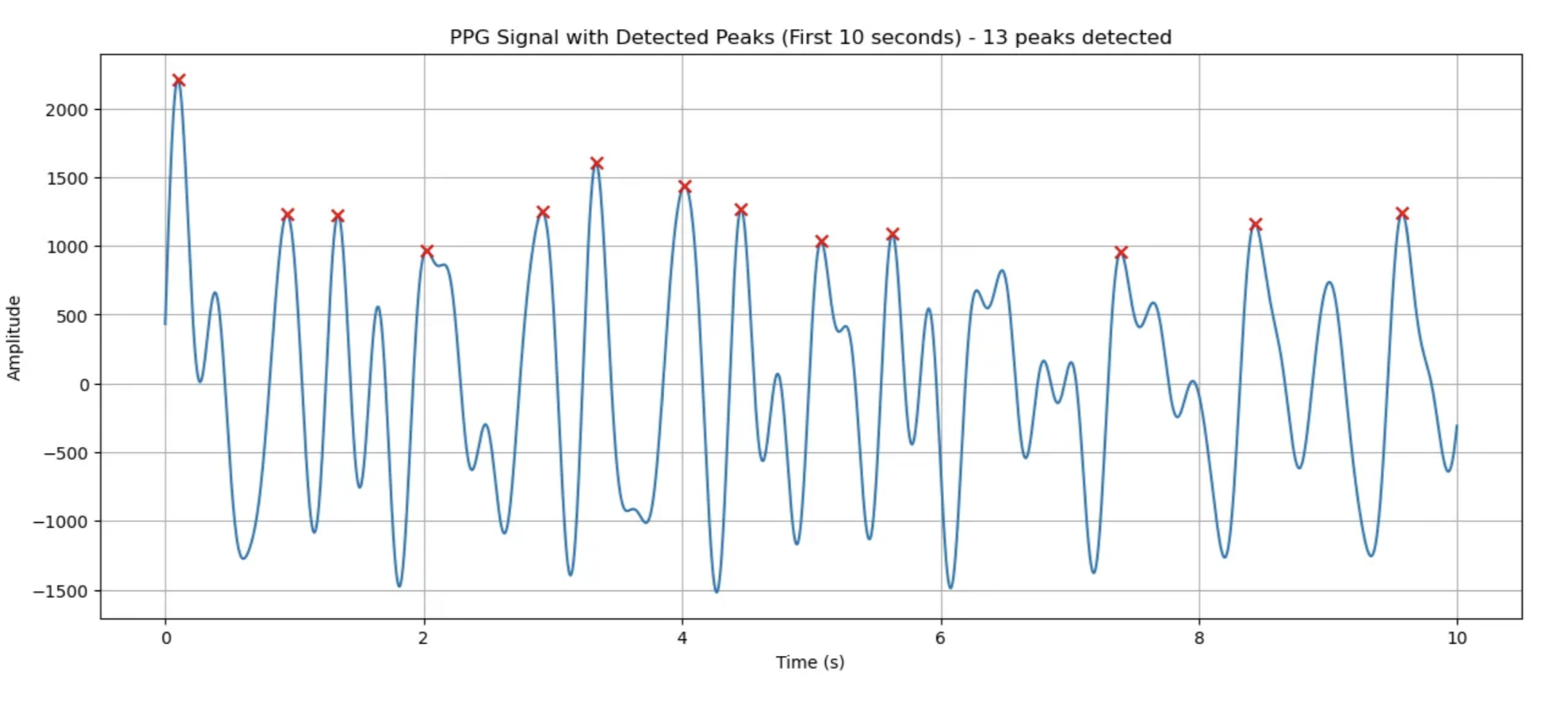
ECG데이터에 비해 4개가 덜 검출댐.
높이 기준: 최대값의 40% → 30%
ECG는 동일 peak 17개
PPG peak 13개 → 15개로 증가
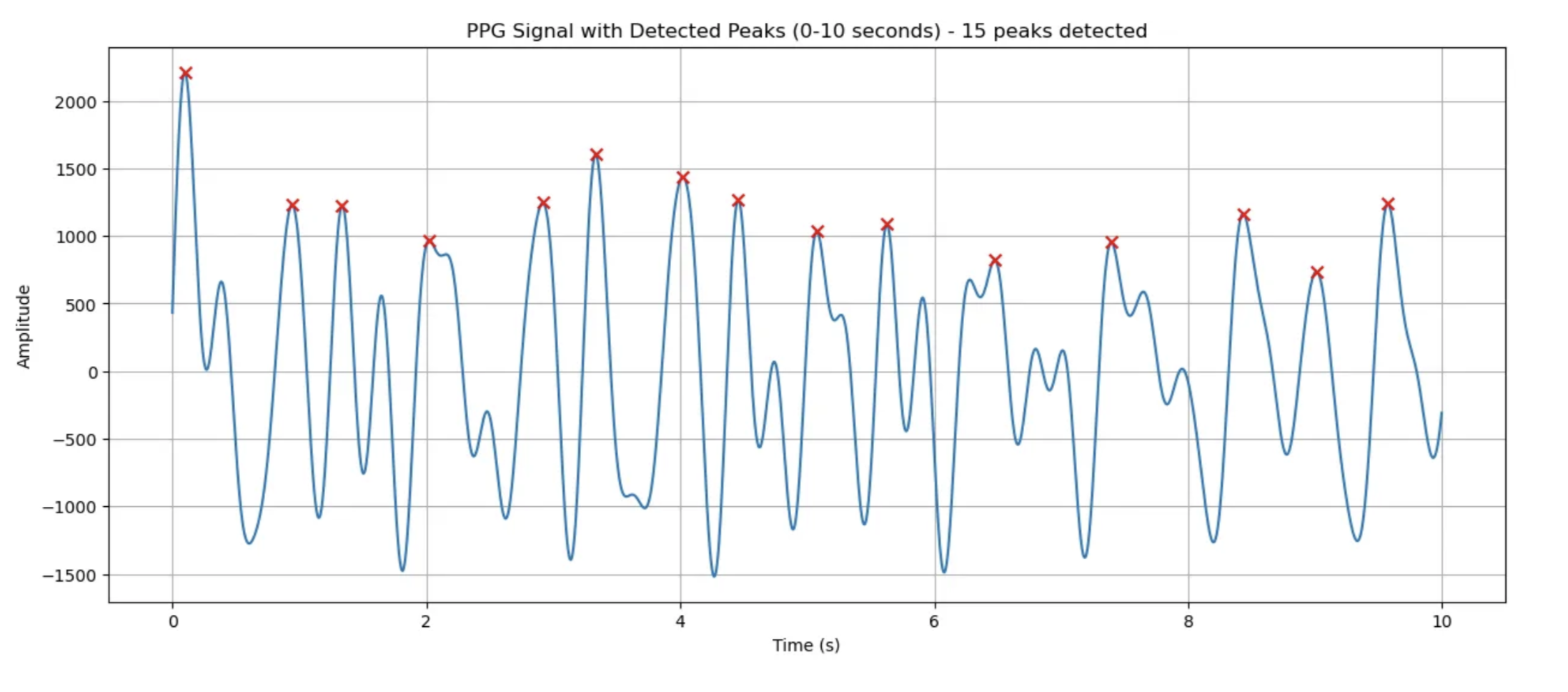
계속 내려보다가 높이기준 0.05로 설정했을때 ECG, PPG 둘 다 peak 17개로 동일해짐
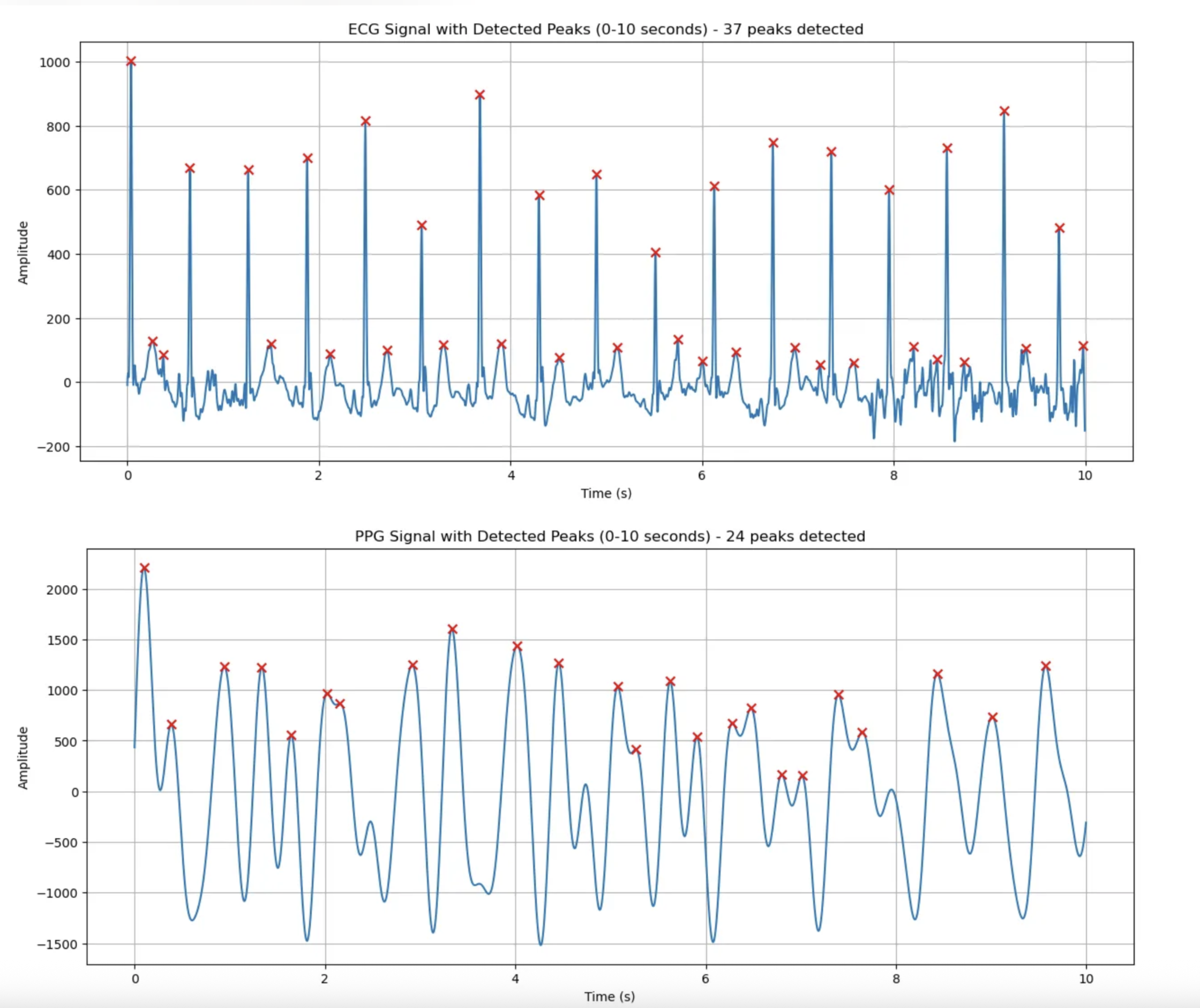
한번 높이기준 0.05 거리 기준(중복처리)를 0.3 에서 0.1로 수정하니까 중복처리가 제대로 되지않음을 확인할 수 있었음 - 거리 임계값: 25 샘플 (0.10초)
그래서 우선 기준을
- 높이 기준 0.05
- 거리 기준 0.3으로 기준으로 잡고 다른 시간대를 시각화 진행함
30~40초
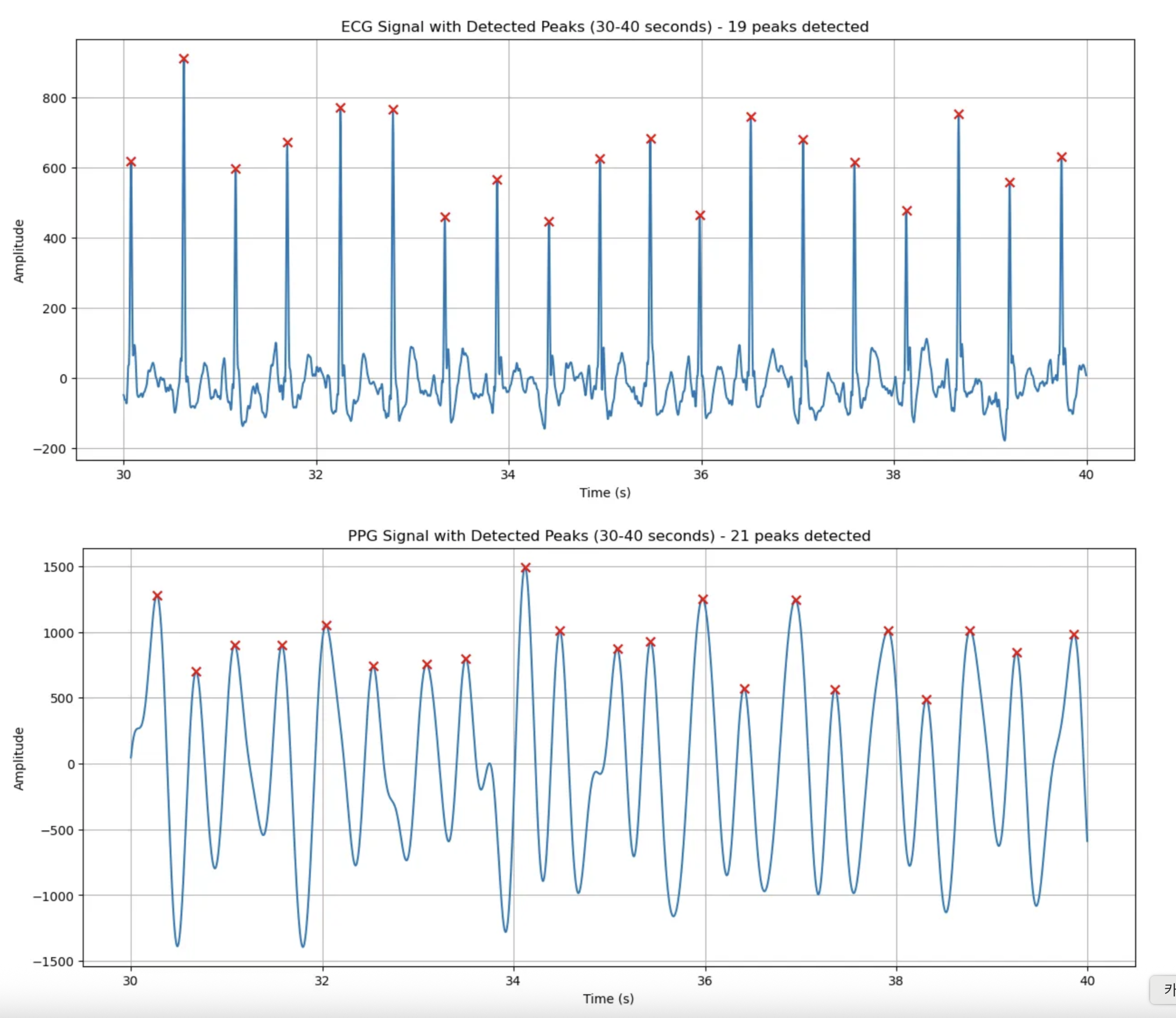
원래 초기 기준이었던 높이기준 0.4, 거리 기준0.3이 더 ECG와 비슷하게 peak를 검출함을 확인할 수 있었음
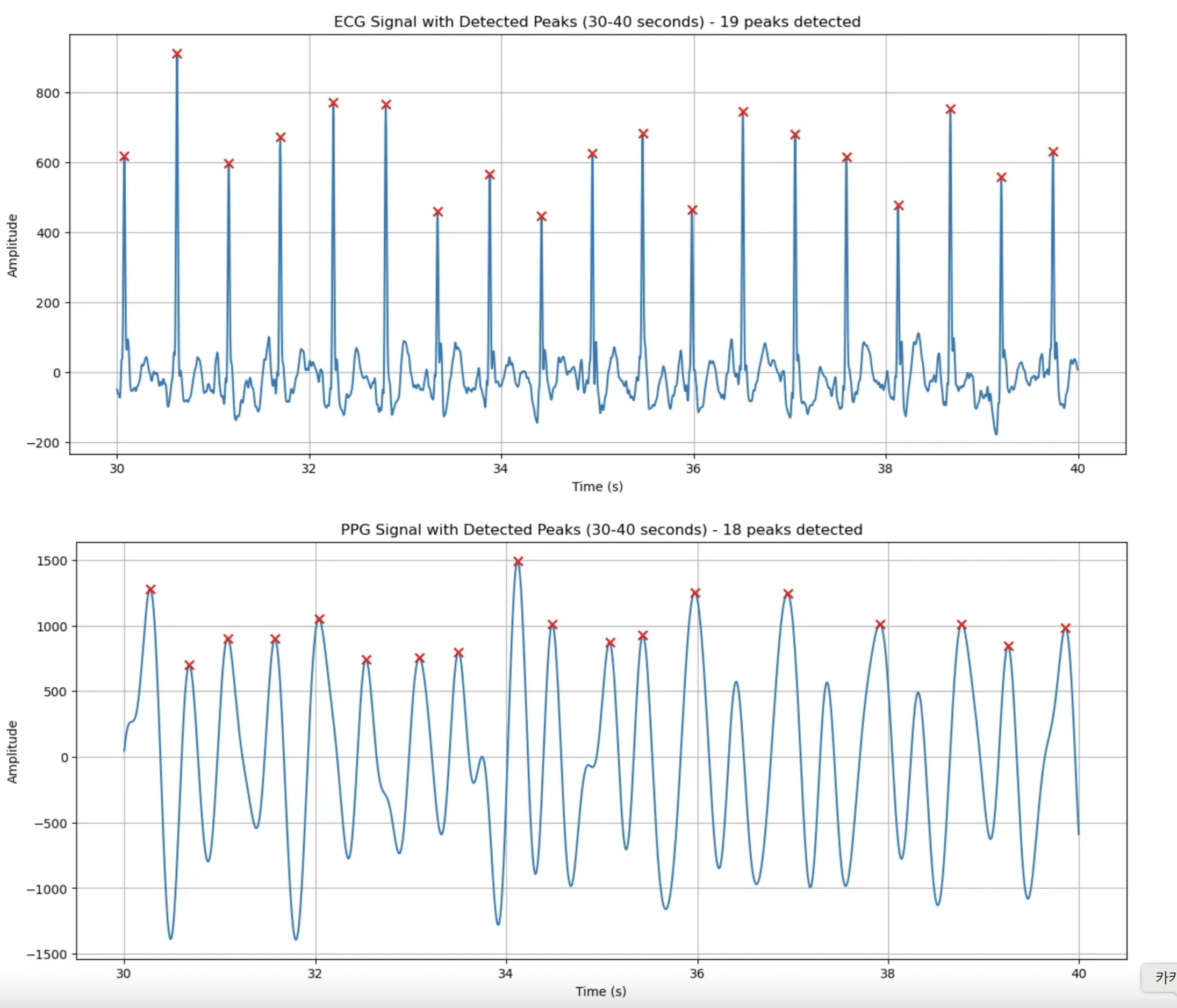
임상데이터가 아니라 필드 데이터인만큼 값이 튀는거때문에 작은 시간 세그먼트별로 무언가 확실한 기준으로 peak를 검출하는 알고리즘을 구할 순 없을듯.
그러면 이 s3_run 데이터가 0초부터 300초 가량 되는데 이걸 하이퍼 파라미터 튜닝하듯 그리드 서치나 그런걸로 ECG데이터와 가장 peak값이 비슷하도록 높이기준과 거리기준을 바꿔서 찾아볼까 고민중