AutoRec: Autoencoders Meet Collaborative Filtering
2015년 제안된 AutoRec은 추천시스템 설계 시, 사용자와 항목을 복합적으로 고려하는 collaborative filtering을 위해 설계된 autoencoder 모델입니다. 이를 통해 기존 존재했던 matrix factorization, neighbourhood model보다 우수한 성능을 달성할 수 있었습니다.
자세한 내용은 논문을 참고하시는 것을 추천드립니다. AutoRec: Autoencoders Meet Collaborative Filtering
ABSTRACT
This paper proposes AutoRec, a novel autoencoder frame work for collaborative ltering (CF)
이 논문에서는 협업필터링을 위한 새로운 오토인코더 프레임 작업인 AutoRec을 제안합니다.
INTRODUCTION
Owing to the Net ix challenge, a panoply of di erent CF models have been proposed, with popular choices being matrix factori sation and neighbourhood models.
Netflix 챌린지 이후 다양한 CF 모델이 제안됨. 주요 모델로는 행렬 분해(matrix factorization)와 이웃 모델(neighbourhood models)이 있음
We argue that AutoRec has represen tational and computational advantages over existing neural approaches to CF.
기존 신경망 기반 CF 접근법에 비해 표현력과 계산 효율성 면에서 이점이 있다고 주장
THE AUTOREC MODEL
In rating-based collaborative ltering, we have m users, n items, and a partially observed user-item rating matrix R Rm n.
평점 기반 협업 필터링에서는 m명의 사용자, n개의 아이템, 그리고 부분적으로 관측된 사용자-아이템 평점 행렬 R이 있습니다.
Eachuseru U = 1 m canberepresented by a partially observed vector r(u) = (Ru1 Similarly, each item i Run) Rn. I = 1 n can be represented by a partially observed vector r(i) = (R1i Rmi) Rm.
각 사용자 u는 부분적으로 관측된 벡터 r(u)로 표현될 수 있습니다.
r(u)는 사용자 u의 모든 아이템에 대한 평점을 나타내며, n차원의 실수 벡터입니다.
Our aim in this work is to design an item-based (user-based) autoencoder which can take as input each partially observed r(i) (r(u)), project it into a low-dimensional latent (hidden) space, and then reconstruct r(i) (r(u)) in the output space to predict missing ratings for purposes of recommendation.
오토인코더는 부분적으로 관측된 r(i)나 r(u)를 입력받아 저차원의 은닉 공간으로 투영 후, 다시 출력 공간으로 r(i)나 r(u)를 재구성해 누락된 평점을 예측
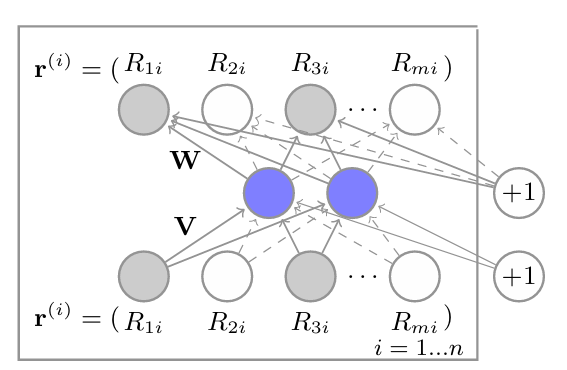
입력 벡터: r(i) = (R1i, R2i, R3i, …, Rmi)
- 이는 i번째 아이템에 대한 모든 사용자의 평점을 나타냅니다.
- 회색 원은 관측된 평점을, 흰색 원은 누락된 평점을 나타냅니다.
가중치 행렬:
- V: 입력층에서 은닉층으로의 가중치 행렬
- W: 은닉층에서 출력층으로의 가중치 행렬
은닉층:
- 파란색 원으로 표시된 부분으로, 저차원 잠재 공간을 나타냅니다.
출력층:
- 입력과 동일한 차원을 가지며, 재구성된 평점 벡터를 나타냅니다.
- ‘+1’로 표시된 부분은 편향(bias)을 나타냅니다.
모델의 구조:
- 이 신경망은 n개의 복사본(각 아이템에 대해 하나씩)으로 구성됩니다.
- W와 V는 모든 복사본에서 공유됩니다(tied weights).
목적:
- 이 모델은 부분적으로 관측된 평점 벡터를 입력으로 받아, 은닉층을 통해 압축하고, 다시 원래 차원으로 복원하여 누락된 평점을 예측합니다.

표 (a): I/U-AutoRec과 RBM 모델들의 RMSE 비교
- ML-1M(MovieLens 1M 데이터셋)과 ML-10M(MovieLens 10M 데이터셋)에서의 성능을 비교합니다.
- I-AutoRec이 두 데이터셋 모두에서 가장 낮은 RMSE를 보여 최고의 성능을 나타냅니다.
표 (b): I-AutoRec의 활성화 함수 선택에 따른 RMSE (MovieLens 1M 데이터셋)
- f()와 g()는 각각 출력층과 은닉층의 활성화 함수를 나타냅니다.
- Identity(항등 함수)와 Sigmoid 함수의 조합들을 실험했습니다.
- 출력층에 Sigmoid, 은닉층에 Sigmoid를 사용했을 때 가장 낮은 RMSE(0.831)를 얻었습니다.
표 (c): I-AutoRec과 다른 베이스라인 모델들의 RMSE 비교
- ML-1M, ML-10M, Netflix 데이터셋에서의 성능을 비교합니다.
- I-AutoRec이 모든 데이터셋에서 가장 낮은 RMSE를 보여 최고의 성능을 나타냅니다.
주요 발견:
- I-AutoRec이 대부분의 경우에 가장 우수한 성능을 보입니다.
- 비선형 활성화 함수(Sigmoid)를 사용하는 것이 선형 함수(Identity)보다 더 나은 결과를 제공합니다.
AutoRec is distinct to existing CF approaches.
AutoRec은 기존의 협업 필터링(CF) 접근 방식들과 다릅니다.
First, RBM-CF proposes a generative, probabilistic model based on restricted Boltzmann machines, while AutoRec is a discriminative model based on autoencoders.
첫째, RBM-CF는 제한된 볼츠만 머신을 기반으로 한 생성적, 확률적 모델을 제안하는 반면, AutoRec은 오토인코더를 기반으로 한 판별적 모델입니다.
Second, RBM-CF estimates parameters by maximising log likelihood, while AutoRec directly minimises RMSE, the canonical performance in rating prediction tasks.
둘째, RBM-CF는 로그 가능도를 최대화하여 파라미터를 추정하는 반면, AutoRec은 평점 예측 작업의 표준 성능 지표인 RMSE를 직접 최소화합니다.
Third, training RBM-CF requires the use of contrastive divergence, whereas training AutoRec requires the comparatively faster gradient-based backpropagation.
셋째, RBM-CF 훈련에는 대조 발산(contrastive divergence)이 필요한 반면, AutoRec 훈련에는 비교적 빠른 그래디언트 기반 역전파가 필요합니다.
Finally, RBM-CF is only applicable for discrete ratings, and estimates a separate set of parameters for each rating value.
마지막으로, RBM-CF는 이산적인 평점에만 적용 가능하며, 각 평점 값에 대해 별도의 파라미터 세트를 추정합니다.
AutoRec은 r에 구애받지 않으므로 더 적은 파라미터가 필요하며 그렇기 때문에 메모리 사용량이 적고 과적합에 덜 취약합니다.
Further, while MF learns a linear latent representation, AutoRec can learn a nonlinear latent representation through activation function g().
또한, MF가 선형 잠재 표현을 학습하는 반면, AutoRec은 활성화 함수 g()를 통해 비선형 잠재 표현을 학습할 수 있습니다.
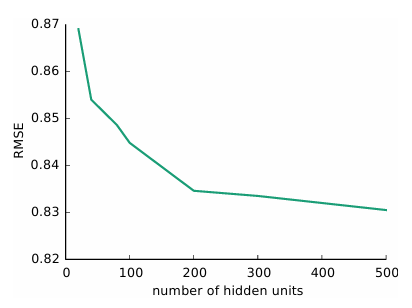
AutoRec, 특히 I-AutoRec이 다른 협업 필터링 방법들에 비해 우수한 성능을 보임
은닉층의 비선형성이 중요한 역할을 함
은닉 유닛 수 증가에 따른 성능 향상이 있지만 점차 그 효과가 감소함
깊은 신경망 구조가 추가적인 성능 향상 가능성을 보여줌
수식설명
오토인코더의 기본 수식 \(h(r; θ) = f(W g(V r + μ) + b)\)
r: 입력 벡터입니다. 여기서는 아이템이나 사용자의 부분적으로 관측된 평점 벡터입니다.
V: 입력 층에서 은닉 층으로의 가중치 행렬입니다.
Vr: 입력 벡터를 은닉 층의 차원으로 변환합니다.
μ: 은닉 층의 편향(bias) 벡터입니다.
g(): 은닉 층의 활성화 함수입니다. 비선형성을 도입하여 모델의 표현력을 높입니다.
W: 은닉 층에서 출력 층으로의 가중치 행렬입니다.
b: 출력 층의 편향 벡터입니다.
f(): 출력 층의 활성화 함수입니다.
입력 r을 받아 Vr + μ 연산을 통해 은닉 층으로 투영합니다.
g() 함수를 통해 은닉 층의 활성화값을 계산합니다.
W를 곱하고 b를 더해 출력 층으로 변환합니다.
마지막으로 f() 함수를 적용하여 최종 출력을 생성합니다.
I-AutoRec의 목적 함수 \(min_θ ∑_{i=1}^n ||r(i) - h(r(i); θ)_O||²_2 + λ/2 (||W||²_F + ||V||²_F)\)
min_θ: 이는 파라미터 θ에 대해 최소화를 수행한다는 의미입니다.
∑_{i=1}^n: 모든 아이템 i (1부터 n까지)에 대해 합산합니다.
r(i) - h(r(i); θ) ²_O:
- r(i): i번째 아이템의 실제 평점 벡터
- h(r(i); θ): 모델이 예측한 평점 벡터
… ²_O: 관측된 평점에 대해서만 제곱 오차를 계산합니다.
λ/2 ( W ²_F + V ²_F):
- 정규화 항으로, 과적합을 방지합니다.
- λ: 정규화 강도를 조절하는 하이퍼파라미터
W ²_F, V ²_F: W와 V 행렬의 프로베니우스 노름의 제곱