pdf 파서해서 pinecone에 넣기
코드짜자
에서 대충 구조를 잡았으니 코드를 짜보자.
사실 주제만 다르지 옛날에 아주 비슷한 프로젝트를 해봤기 때문에 이번 프로젝트는 금방 끝낼 것 같다.
이게 옛날에 했던 LLM기반 프로젝튼데 저번이 수능 데이터를 가져와서 학생들을 대상으로 했던 내용이라면
이번엔 고용노동부 데이터를 가져와서 시민들로 대상이 바뀐 것 그 이상 그 이하도 아니긴하다.
# API 키
OPENAI_API_KEY=sk-your-openai-api-key
PINECONE_API_KEY=your-pinecone-api-key
PINECONE_ENVIRONMENT=us-west1-gcp
# 데이터베이스
MYSQL_HOST=localhost
MYSQL_USER=root
MYSQL_PASSWORD=****
MYSQL_DB=labor_policy
MYSQL_PORT=3306
# JWT
SECRET_KEY=your-secret-key-for-jwt
OPENAI_API_KEY는 Chatgpt에서 API키를 받아서 입력했고
pinecone에서 API키를 발급받아 사용했다.
- Dimensions: 1536 (OpenAI의 text-embedding-3-small 모델 차원)
- Metric: Cosine
MySQL은 Docker 컨테이너로 실행했다.
이제 PDF 파싱 스크립트를 실행해서 pdf를 텍스트로 변환해보기로 했다.
# PDF parser
import os
print(f"로드된 OpenAI API 키: {os.getenv('OPENAI_API_KEY')[:10]}...")
import re
import pdfplumber
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from pinecone import Pinecone, ServerlessSpec
from tqdm import tqdm
import time
import json
import sys
from pathlib import Path
# 상위 디렉토리를 모듈 검색 경로에 추가
sys.path.append(str(Path(__file__).resolve().parent.parent))
from backend.app.core.config import settings
# OpenAI 및 Pinecone 초기화
os.environ["OPENAI_API_KEY"] = settings.OPENAI_API_KEY
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Pinecone 클라이언트 초기화 (변경된 부분)
pc = Pinecone(api_key=settings.PINECONE_API_KEY)
# Pinecone 인덱스 생성 또는 가져오기
if settings.PINECONE_INDEX_NAME not in pc.list_indexes().names():
pc.create_index(
name=settings.PINECONE_INDEX_NAME,
dimension=1536, # text-embedding-3-small 모델의 차원
metric="cosine",
spec=ServerlessSpec(
cloud="aws", # 또는 "gcp"나 "azure"
region=settings.PINECONE_ENVIRONMENT
)
)
# 인덱스 가져오기
index = pc.Index(settings.PINECONE_INDEX_NAME)
def extract_text_from_pdf(pdf_path):
"""PDF에서 텍스트 추출"""
all_text = ""
page_texts = []
try:
with pdfplumber.open(pdf_path) as pdf:
total_pages = len(pdf.pages)
for i, page in enumerate(tqdm(pdf.pages, desc="PDF 페이지 처리 중")):
text = page.extract_text() or ""
clean_text = text.replace('\n', ' ').strip()
# 페이지 번호와 함께 저장
page_texts.append({
"page_number": i + 1,
"text": clean_text,
"total_pages": total_pages
})
all_text += clean_text + " "
print(f"PDF에서 총 {len(page_texts)} 페이지 추출 완료")
return all_text, page_texts
except Exception as e:
print(f"PDF 추출 오류: {e}")
return "", []
def split_text_into_chunks(text, page_texts):
"""텍스트를 청크로 분할"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", ".", " ", ""],
length_function=len,
)
chunks = text_splitter.split_text(text)
# 청크에 페이지 번호 할당
chunk_metadata = []
current_position = 0
for chunk in chunks:
chunk_start = text.find(chunk, current_position)
if chunk_start != -1:
current_position = chunk_start
# 청크가 속한 페이지 찾기
accumulated_length = 0
page_number = 1
for page_data in page_texts:
page_text = page_data["text"]
page_length = len(page_text)
if accumulated_length + page_length > chunk_start:
page_number = page_data["page_number"]
break
accumulated_length += page_length + 1 # +1 for space added between pages
chunk_metadata.append({
"chunk": chunk,
"page_number": page_number
})
print(f"텍스트를 {len(chunks)} 청크로 분할 완료")
return chunk_metadata
def embed_and_store_chunks(chunk_metadata):
"""청크를 임베딩하여 Pinecone에 저장"""
batch_size = 100 # 한 번에 처리할 청크 수
vectors = []
for i in tqdm(range(0, len(chunk_metadata), batch_size), desc="청크 임베딩 및 저장 중"):
# 현재 배치에서 처리할 청크
current_batch = chunk_metadata[i:i+batch_size]
chunks = [item["chunk"] for item in current_batch]
# 임베딩 생성
try:
embeddings_list = embeddings.embed_documents(chunks)
# 벡터 및 메타데이터 준비
for j, (chunk_data, embedding) in enumerate(zip(current_batch, embeddings_list)):
vector_id = f"chunk_{i+j}"
metadata = {
"text": chunk_data["chunk"],
"page": chunk_data["page_number"]
}
vectors.append((vector_id, embedding, metadata))
# 일정 크기의 배치가 모이면 Pinecone에 저장
if len(vectors) >= 100:
upsert_vectors_to_pinecone(vectors)
vectors = [] # 벡터 리스트 초기화
except Exception as e:
print(f"임베딩 오류: {e}")
continue
# 남은 벡터 저장
if vectors:
upsert_vectors_to_pinecone(vectors)
print("모든 청크 임베딩 및 저장 완료")
def upsert_vectors_to_pinecone(vectors):
"""벡터를 Pinecone에 업서트"""
try:
# 새 Pinecone API에 맞게 업데이트
records = [(id, embedding, metadata) for id, embedding, metadata in vectors]
index.upsert(vectors=records)
time.sleep(1) # API 제한 방지
except Exception as e:
print(f"Pinecone 업서트 오류: {e}")
def process_pdf(pdf_path):
"""PDF 처리 전체 파이프라인"""
print(f"PDF 처리 시작: {pdf_path}")
# 1. PDF에서 텍스트 추출
all_text, page_texts = extract_text_from_pdf(pdf_path)
if not all_text:
print("텍스트 추출 실패")
return False
# 2. 텍스트를 청크로 분할
chunk_metadata = split_text_into_chunks(all_text, page_texts)
# 3. 청크 임베딩 및 저장
embed_and_store_chunks(chunk_metadata)
print("PDF 처리 완료")
return True
if __name__ == "__main__":
if len(sys.argv) < 2:
print("사용법: python pdf_parser.py <PDF 파일 경로>")
sys.exit(1)
pdf_path = sys.argv[1]
process_pdf(pdf_path)
python scripts/pdf_parser.py data/policies/labor.pdf
~/labor-policy-assistant │ main !12 ?61 python scripts/pdf_parser.py data/policies/labor.pdf
PDF 처리 시작: data/policies/labor.pdf
PDF 페이지 처리 중: 100%|███████████████████████| 319/319 [01:24<00:00, 3.78it/s]
PDF에서 총 319 페이지 추출 완료
텍스트를 0 청크로 분할 완료
청크 임베딩 및 저장 중: 0it [00:00, ?it/s]
모든 청크 임베딩 및 저장 완료
PDF 처리 완료
PDF에서 페이지는 다 추출되었는데 청크가 0개로 분할되었다.
뭔가 문제가 생긴 모양이다.
예상 이유로는 PDF파일이 마우스로 드래그되는 글자가 아니라 통 이미지라서 안 읽히는 것 같다. 저번 프로젝트때도 똑같은 문제가 있었다.
우선 글자가 드래그되는 PDF로 테스트를 해보았다.
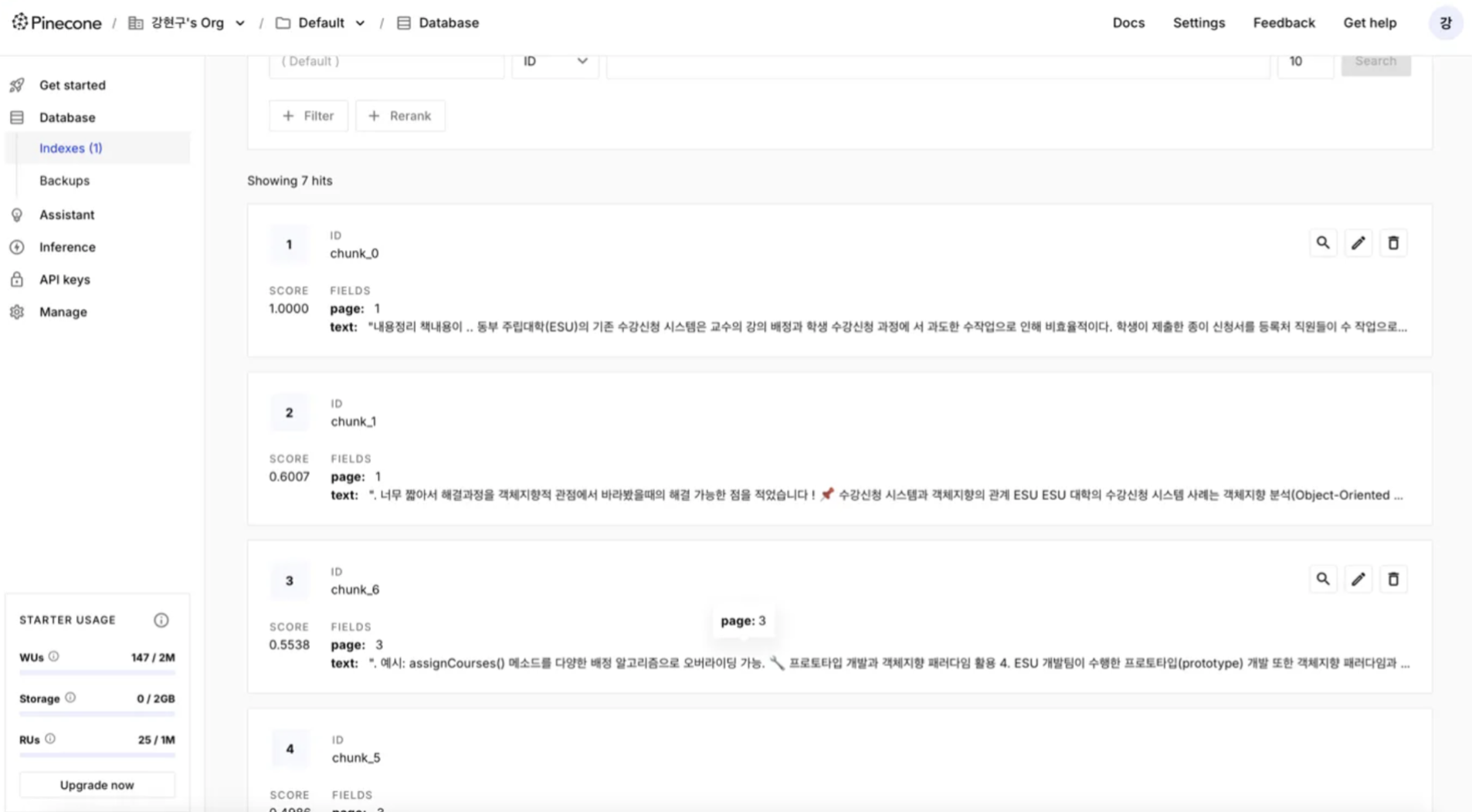
음. 잘 들어온다. 예상대로 이미지라서 chunk로 변환이 안되는 모양이다.
어쩔 수 없다. 귀찮긴한데 OCR을 한번 거쳐야겠다. OCR은 다음 포스트에 이어쓰도록하자.