기본 모델 돌려보기
기본 모델 돌려보기
우선 앙상블, 하이퍼파라미터를 하기전에 데이터를 토대로 트리기반 베이스 모델을 돌려보기로 했다. 아래의 사이트를 참고했다.
7 Most Popular Boosting Algorithms to Improve Machine Learning Model’s Performance
AdaBoost와 GBM, SGB는 추천되지않았기에
-
LightGBM
-
XGboost
-
CatBoost
-
HPboost
만 진행하였다.
LightGBM
1. LightGBM 매개변수 설정
params = {
"boosting_type": "gbdt",
"objective": "multiclass",
"metric": "multi_logloss",
"num_class": 4,
"num_leaves": 30,
"learning_rate": 0.02,
"n_estimators": 30,
"random_state": 42,
'verbose': -1
}
이 부분은 LightGBM 모델의 하이퍼파라미터를 설정합니다. “gbdt”는 그래디언트 부스팅 결정 트리를 사용하고, “multiclass”는 다중 분류 문제임을 나타냅니다. 4개의 클래스가 있으며, 학습률은 0.02, 트리의 최대 잎 노드 수는 30개입니다.
2. LightGBM 훈련 함수 정의
def lgbm_train(x_train, y_train, x_valid, y_valid, params):
# LightGBM 데이터셋 생성
train_data = lgb.Dataset(x_train, label=y_train, categorical_feature = category_cols)
valid_data = lgb.Dataset(x_valid, label=y_valid, reference=train_data, categorical_feature = category_cols)
# LightGBM 모델 훈련
lgb_model = lgb.train(
params=params,
train_set=train_data,
valid_sets=valid_data
)
# 검증 데이터에 대한 예측
y_valid_pred = lgb_model.predict(x_valid)
y_valid_pred_class = np.argmax(y_valid_pred, axis = 1)
# 성능 평가
accuracy = accuracy_score(y_valid, y_valid_pred_class)
auroc = roc_auc_score(y_valid, y_valid_pred, multi_class="ovr")
return lgb_model, y_valid_pred_class, accuracy, auroc
이 함수는 LightGBM 모델을 훈련시키고, 검증 데이터에 대한 예측을 수행한 후 정확도와 AUROC 점수를 계산합니다.
3. 모델 훈련 및 평가
lgb_random, y_pred_random, accuracy_random, auroc_random = lgbm_train(x_train_random, y_train_random, x_valid_random, y_valid_random, params)
lgb_ts, y_pred_ts, accuracy_ts, auroc_ts = lgbm_train(x_train_ts, y_train_ts, x_valid_ts, y_valid_ts, params)
이 부분에서는 랜덤 분할된 데이터와 시계열 분할된 데이터 각각에 대해 모델을 훈련시키고 평가합니다.
4. 결과 출력
print(f"random split - acc: {accuracy_random}, auroc: {accuracy_random}")
print(f"ts split - acc: {accuracy_ts}, auroc: {accuracy_ts}")
각 분할 방식에 대한 정확도와 AUROC 점수를 출력하고, 예측된 클래스의 분포를 보여줍니다.
random split - acc: 0.4463470319634703, auroc: 0.4463470319634703 ts split - acc: 0.45969945355191255, auroc: 0.45969945355191255
- 랜덤 분할: 정확도(accuracy)와 AUROC가 약 0.4463 (44.63%)
- 시계열 분할: 정확도와 AUROC가 약 0.4597 (45.97%)
- 리더보드 제출 결과: 0.4055 (40.55%)
이 결과는 모델의 성능이 그리 높지 않음을 나타냅니다. 일반적으로 다중 분류에서 랜덤 추측의 성능이 클래스 수의 역수(이 경우 1/4 = 25%)이므로, 이 모델은 랜덤 추측보다는 나은 성능을 보이고 있지만, 여전히 개선의 여지가 많습니다.
Counter(y_pred_random)
Counter({2: 935, 1: 817})
Counter(y_pred_ts)
Counter({2: 794, 1: 670})
예측 분포:
- 랜덤 분할: 클래스 2 (935개), 클래스 1 (817개)
- 시계열 분할: 클래스 2 (794개), 클래스 1 (670개)
- 테스트 데이터: 클래스 2 (1804개), 클래스 1 (988개)
모델이 주로 클래스 1과 2만 예측하고 있으며, 클래스 0과 3은 거의 예측하지 않고 있습니다. 이는 클래스 불균형 문제를 나타낼 수 있습니다.
5. 혼동 행렬 시각화
cm = confusion_matrix(y_valid_ts, y_pred_ts)
plt.figure(figsize=(6,4))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title('Confusion Matrix')
plt.show()
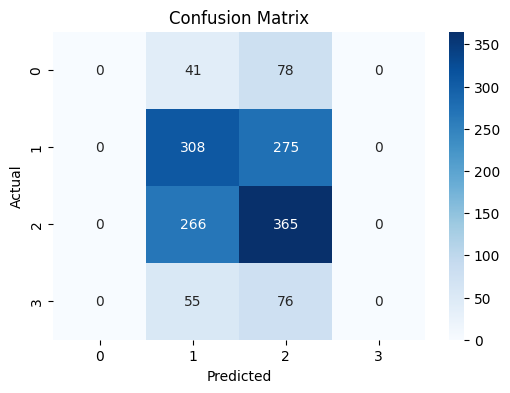
혼동 행렬 분석:
- 클래스 0: 41개를 클래스 1로, 78개를 클래스 2로 잘못 예측
- 클래스 1: 308개를 올바르게 예측, 275개를 클래스 2로 잘못 예측
- 클래스 2: 365개를 올바르게 예측, 266개를 클래스 1로 잘못 예측
- 클래스 3: 55개를 클래스 1로, 76개를 클래스 2로 잘못 예측
모델이 클래스 1과 2를 구분하는 데 어려움을 겪고 있으며, 클래스 0과 3을 거의 예측하지 못하고 있습니다.
6. 특성 중요도 시각화
feature_importance = lgb_ts.feature_importance()
sorted_idx = np.argsort(feature_importance)
fig = plt.figure(figsize=(15, 10))
plt.barh(range(len(sorted_idx[-50:])), feature_importance[sorted_idx[-50:]], align='center')
plt.yticks(range(len(sorted_idx[-50:])), np.array(x_train_ts.columns)[sorted_idx[-50:]])
plt.title('Feature Importance')
모델이 판단한 각 특성의 중요도를 시각화합니다. 상위 50개의 중요한 특성만 보여줍니다.
7. 중요도가 0인 특성 확인
np.array(x_train_ts.columns)[np.where(feature_importance == 0)]
len(np.where(feature_importance == 0)[0])
8. 전체 데이터로 최종 모델 훈련
x_train_full = train_df.drop(["target", "ID"], axis = 1)
y_train_full = train_df["target"].astype(int)
train_data = lgb.Dataset(x_train_full, label=y_train_full)
lgb_model = lgb.train(
params=params,
train_set=train_data,
)
검증 결과를 확인한 후, 전체 훈련 데이터를 사용하여 최종 모델을 훈련시킵니다.
9. 테스트 데이터에 대한 예측
y_test_pred = lgb_model.predict(test_df.drop(["target", "ID"], axis = 1))
y_test_pred_class = np.argmax(y_test_pred, axis = 1)
Counter(y_test_pred_class)
최종 모델을 사용하여 테스트 데이터에 대한 예측을 수행하고, 예측된 클래스의 분포를 확인합니다.
XGboost와 Catboost 모델도 위와 형식은 동일하게 코딩하여 제출하였다.
XGboost 혼동 행렬
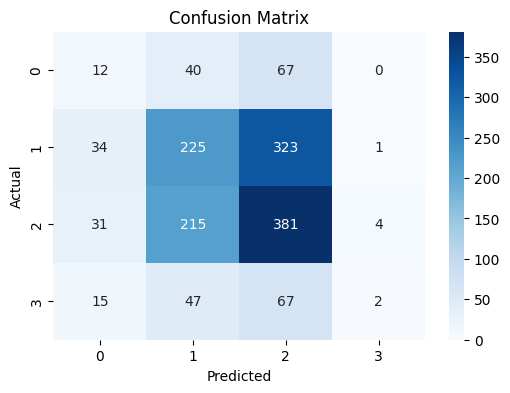
리더보드 제출: 0.4119
Catboost 혼동 행렬
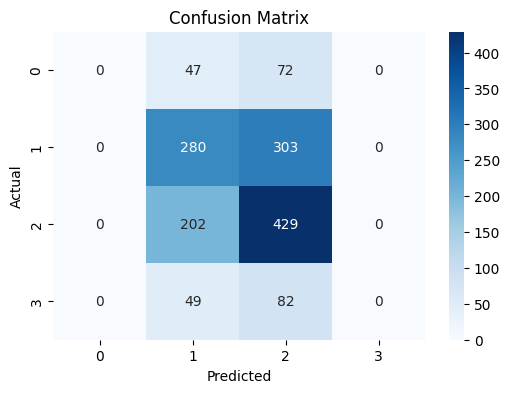
리더보드 제출: 0.3942
성능 XGBoost(0.4119) > lgbm(0.4055) > CatBoost(0.3942)
HPBoost랑 Propet? 두개 하려고 자려했는데 HPBoost가 학습이 너무 오래걸린다.. 언제되지..