PDF OCR하기
저번까지의 문제
~/labor-policy-assistant │ main !12 ?61 python scripts/pdf_parser.py data/policies/labor.pdf
PDF 처리 시작: data/policies/labor.pdf
PDF 페이지 처리 중: 100%|███████████████████████| 319/319 [01:24<00:00, 3.78it/s]
PDF에서 총 319 페이지 추출 완료
텍스트를 0 청크로 분할 완료
청크 임베딩 및 저장 중: 0it [00:00, ?it/s]
모든 청크 임베딩 및 저장 완료
PDF 처리 완료
PDF에서 텍스트가 정상적으로 추출되지 않는다.
OCR을 통해 이 문제를 해결하자.
OCR
저번 프로젝트에서는 Upstage의 OCR API를 사용했다.
아마 이번에는 다른 방향으로 한번 해보지 않을까? 아니면 여러개 해보고 그 성능을 비교해서 좋은 걸로 가도대고.
Claude가 추천해준 건 우선
- Tesseract OCR + PyTesseract: 가장 널리 사용되는 오픈소스 OCR 엔진
- EasyOCR: 한국어 지원이 좋은 최신 OCR 라이브러리
- Google Cloud Vision API: 정확도가 높지만 비용 발생
- Naver CLOVA OCR: 한국어 특화된 OCR 서비스
4가지 정도이다.
EasyOCR
Easyocr 라이브러리를 활용하는 방법을 시도해보았다.
def perform_ocr_on_images(image_folder, output_folder, num_pages):
import easyocr
import os
# 출력 폴더가 없으면 생성
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# EasyOCR 리더 초기화 (한국어 + 영어)
reader = easyocr.Reader(['ko', 'en'])
for page_num in range(1, num_pages + 1):
image_path = os.path.join(image_folder, f"page_{page_num}.png")
output_file = os.path.join(output_folder, f"page_{page_num}.txt")
# OCR 실행
results = reader.readtext(image_path)
# 결과를 텍스트 파일로 저장
with open(output_file, 'w', encoding='utf-8') as f:
for (_, text, _) in results:
f.write(text + '\n')
print(f"Processed page {page_num}/{num_pages}")
우선 5페이지로 샘플링된 pdf로 테스트해보니 이미지, 해당 페이지의 텍스트, 전체 테스트까지 잘 산출되었다.
Page_3.txt
Cantents
01
취업 취약계층 고용안정 및 취업지원
청년
(7) 청년일자리도악장려금 사업
(2) 청년미래플러스 사업
3
(3) 청년도전지원사업
청년성장프로적트
5
(5) 직장적응 지원
(6) 일학습병행
청년일경험지원
(8) 대학일자리플러스센터 운영
70
(9) 해외취업지원
(70) 능력중심의 투명한 공정채용문화 확산
14
(77) 채용절차의 공정성 제고
75
(12) 대학 재학생 맞춤형 고용서비스
76
(13) 미래유망분야 고졸인력양성
7
(14) 고교 재학생 맞춤형 고용서비스
79
(75) 졸업생 특화프로그램
20
(76) 플리택 하이테크과정
27
고렇자(신중년)
(17) 고렇자 계속고용장려금
22
(78) 고렇자 고용지원금
23
(79) 중장년 경력지원제
24
(20) 중장년내일센터
25
생각보다 OCR 이 정도면 잘 된 것 같은데..
오타가 몇개 보이긴한데 눈으로 흝어봤을때는 전체 페이지의 95%이상 오타가 없는 것 같다.
EasyOCR
1. EasyOCR
EasyOCR은 다음과 같은 특징이 있습니다:
- 딥러닝 기반: CRAFT(Character Region Awareness for Text Detection)라는 텍스트 감지 알고리즘과 CRNN(Convolutional Recurrent Neural Network) 문자 인식 모델을 사용합니다.
- 다국어 지원: 80개 이상의 언어를 지원하며, 한국어 인식 성능이 우수합니다.
- GPU 가속: GPU가 있으면 처리 속도가 크게 향상됩니다.
2. 내부 작동 방식
텍스트 감지(CRAFT)
- CRAFT 알고리즘은 각 픽셀이 문자의 중심부에 얼마나 가까운지와 문자 간 연결성을 예측합니다.
- 이 정보를 바탕으로 텍스트 영역에 대한 경계 상자(bounding box)를 생성합니다.
문자 인식(CRNN)
- CNN(Convolutional Neural Network)으로 문자 이미지의 특징을 추출합니다.
- RNN(Recurrent Neural Network)으로 추출된 특징의 시퀀스를 분석합니다.
- CTC(Connectionist Temporal Classification) 디코딩으로 최종 텍스트를 생성합니다.
이건 추가 공부페이지로 넣고 나중에 포스팅하고 오픈소스도 한번 해보는 걸로.
OCR로 추출된 텍스트 파일을 다시 청킹하고 임베딩을 생성한 후, Pinecone에 업로드
# upload_vectors.py
import os
import re
from tqdm import tqdm
from pinecone import Pinecone
from dotenv import load_dotenv
# .env 파일 로드
load_dotenv()
# 환경 변수 가져오기
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
INDEX_NAME = os.getenv("PINECONE_INDEX_NAME", "labor-policy")
# 작업 디렉토리 설정
work_dir = "work_labor_sample"
merged_file = os.path.join(work_dir, "labor_sample_text.txt")
# 텍스트 파일 다시 읽기
with open(merged_file, 'r', encoding='utf-8') as f:
text = f.read()
# 텍스트 청킹 함수 - 페이지 메타데이터 포함
def create_chunks_with_metadata(text, chunk_size=1000, chunk_overlap=200):
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 페이지 정보 추출을 위한 준비
chunks = []
metadatas = []
# 페이지 구분자로 텍스트 분리
page_pattern = "\n--- Page (\d+) ---\n"
page_splits = re.split(page_pattern, text)
# 첫 요소는 빈 문자열일 수 있으므로 제거
if page_splits[0] == '':
page_splits = page_splits[1:]
# 페이지 번호와 내용 쌍으로 재구성
pages = []
for i in range(0, len(page_splits), 2):
if i+1 < len(page_splits):
page_num = page_splits[i]
content = page_splits[i+1]
pages.append((page_num, content))
# 텍스트 스플리터 설정
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
# 각 페이지별로 청크 생성 및 메타데이터 추가
for page_num, content in pages:
page_chunks = text_splitter.split_text(content)
for chunk in page_chunks:
chunks.append(chunk)
metadatas.append({"page": page_num})
return chunks, metadatas
# 임베딩 생성 함수
def get_embeddings(chunks):
from openai import OpenAI
import time
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY)
embeddings = []
for chunk in tqdm(chunks, desc="임베딩 생성 중"):
response = client.embeddings.create(
input=chunk,
model="text-embedding-3-small"
)
embeddings.append(response.data[0].embedding)
time.sleep(0.1) # API 속도 제한 방지
return embeddings
# Pinecone에 업로드 - 메타데이터 포함
def upload_to_pinecone(chunks, embeddings, metadatas):
print("Pinecone에 업로드 중...")
# Pinecone 초기화
pc = Pinecone(api_key=PINECONE_API_KEY)
# 인덱스 존재 확인
existing_indexes = [index.name for index in pc.list_indexes()]
if INDEX_NAME not in existing_indexes:
print(f"인덱스 '{INDEX_NAME}' 생성 중...")
pc.create_index(
name=INDEX_NAME,
dimension=1536, # text-embedding-3-small 차원
metric="cosine"
)
# 인덱스 연결
index = pc.Index(INDEX_NAME)
# 데이터 업로드
batch_size = 100
for i in tqdm(range(0, len(chunks), batch_size), desc="벡터 업로드 중"):
i_end = min(i + batch_size, len(chunks))
vectors = []
for j in range(i, i_end):
vectors.append({
"id": f"chunk_{j}",
"values": embeddings[j],
"metadata": {
"text": chunks[j],
"page": metadatas[j]["page"]
}
})
# 벡터 업로드
index.upsert(vectors=vectors)
print("Pinecone 업로드 완료!")
# 메인 실행 코드
def main():
print(f"텍스트 파일 '{merged_file}' 처리 중...")
# 텍스트 청킹 (메타데이터 포함)
chunks, metadatas = create_chunks_with_metadata(text)
print(f"{len(chunks)}개의 청크 생성 완료")
# 임베딩 생성
embeddings = get_embeddings(chunks)
# Pinecone에 업로드 (메타데이터 포함)
upload_to_pinecone(chunks, embeddings, metadatas)
if __name__ == "__main__":
main()
python scripts/upload_vectors.py
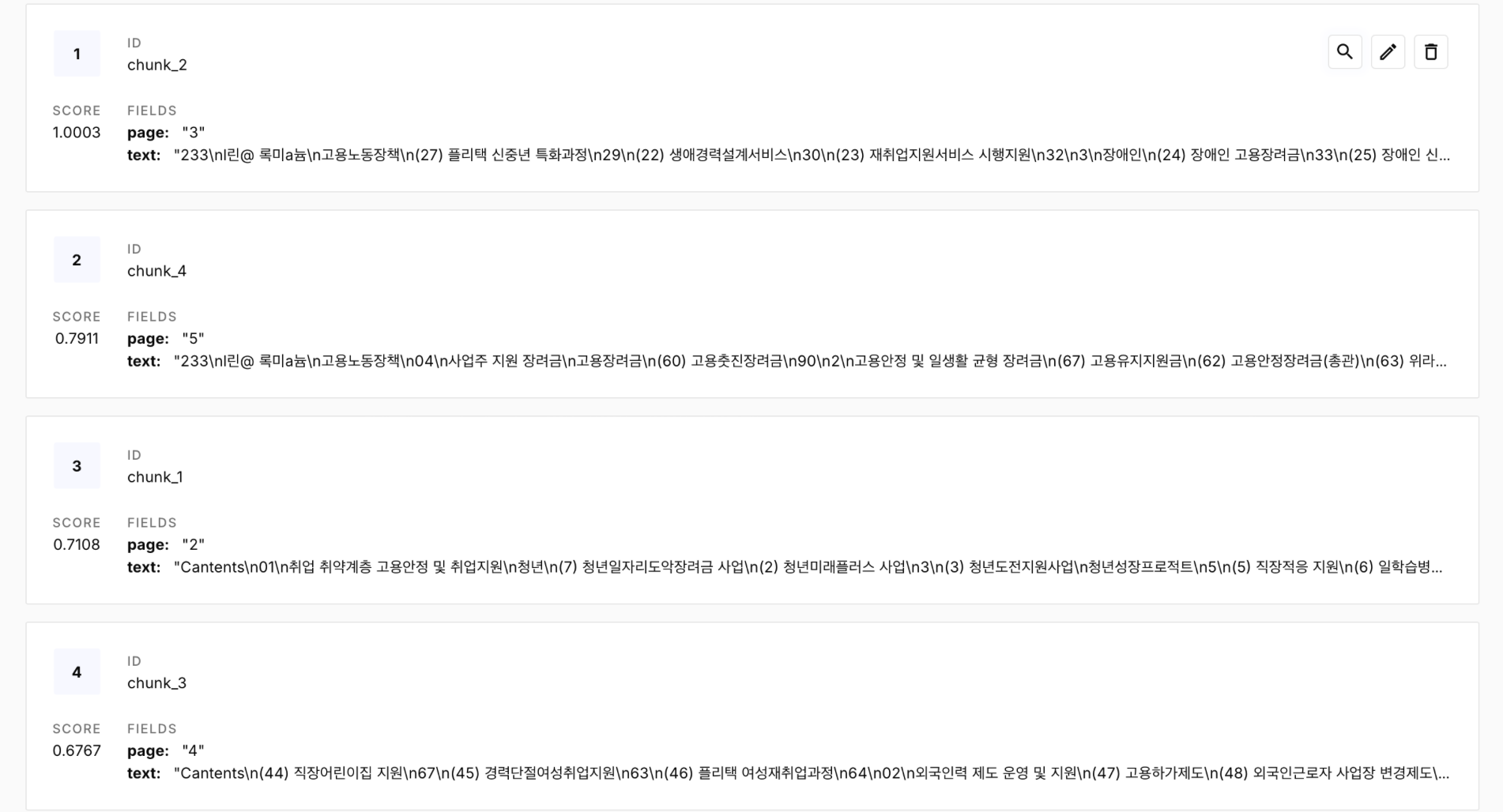
원래는 page는 저장이 안되었는데 코드를 수정하여
위처럼 각 페이지도 메타데이터로 잡히게 같이 저장해두었다.
그 이유는 나중에 LLM이나 추천시스템에 사용할때 이 정보는 몇 페이지에 있습니다. 이렇게 사용자에게 원내용이 어디있는지 위치를 알려주는게 효과적이었던 기억이 있다.
이제 다음 문제
easyocr 을 사용하면 95% 이상 잘 텍스트가 추출되지만 5%가 아쉽긴하다.
이 5%를 어케 처리해야할까?
- 다른 OCR기법들을 테스트해서 더 좋은 OCR 사용
- 텍스트 후처리
아마 둘 다 해봐야할듯..? 아마 다음 포스팅은 1번으로 여러개 해보고 어느게 성능이 좋은지 시각화도 해서 비교할 듯.