블로그 추천시스템 성능 개선 프로젝트3
블로그 추천시스템 성능 개선 프로젝트
프로젝트 개요
기존 블로그 추천시스템을 분석하고, TF-IDF 기반 ML 모델을 만들어 기존 방식과 성능 비교까지 했음.
이번엔 Gemini API 기반 LLM 모델을 구현하여 성능을 객관적으로 측정예정.
🔧 시스템 아키텍처
비교 대상 모델들
- Baseline: 태그/카테고리 기반 단순 매칭
- TF-IDF + 코사인 유사도: 최적화된 전통적 ML 접근법
- Gemini API: LLM 기반 의미적 이해 추천
- Hybrid: TF-IDF + LLM 앙상블 (향후 계획)
기술 스택
- ML/NLP: scikit-learn, TF-IDF, 코사인 유사도
- LLM: Google Gemini API, OpenAI GPT-4o-mini
- 데이터: Jekyll 블로그 144개 게시물
- 평가: Leave-One-Out, 통일 기준 평가, LLM-as-Judge
우선 Gemini기반 추천시스템을 통해 gemini_related_posts.json를 만들었다.
def create_recommendation_prompt(self, target_post: Dict, candidate_posts: List[Dict]) -> str:
"""추천을 위한 프롬프트 생성"""
# 타겟 포스트 요약
target_content = target_post['content'][:1500] # 토큰 제한을 위해 1500자로 제한
target_summary = f"""
제목: {target_post['title']}
카테고리: {target_post['collection']}
내용 (요약): {target_content}
"""
# 후보 포스트들 요약
candidates_summary = ""
for i, post in enumerate(candidate_posts):
content_preview = post['content'][:800] # 더 짧게 제한
candidates_summary += f"""
[{i+1}] 제목: {post['title']}
카테고리: {post['collection']}
내용: {content_preview}
"""
prompt = f"""당신은 블로그 추천 시스템 전문가입니다. 주어진 타겟 게시물과 가장 관련성이 높은 게시물들을 {self.num_recommendations}개 추천해주세요.
타겟 게시물:
{target_summary}
후보 게시물들:
{candidates_summary}
추천 기준:
1. 내용의 의미적 연관성 (주제, 개념, 기술 스택 등)
2. 독자에게 유용한 연속성 (심화 학습, 관련 기술 등)
3. 카테고리 다양성 (같은 카테고리만 추천하지 말 것)
다음 JSON 형식으로 정확히 {self.num_recommendations}개 추천해주세요:
recommendations,
...
],
"analysis": "전체적인 추천 근거 (100자 이내)"
}}
아래와 같이 출력된다.
"/2024/09/13/모델-학습-파이프라인.html": [
{
"title": "FastAPI를 활용한 Online Serving",
"url": "/2024/12/17/FastAPI를-활용한-Online-Serving.html",
"reason": "FastAPI를 이용한 모델 배포 경험은 모델 학습 파이프라인 구축에 필수적이며, 실제 서",
"similarity": 0.9,
"method": "gemini-api"
},
{
"title": "Airflow를 활용한 Batch Serving",
"url": "/2024/12/16/Airflow를-활용한-Batch-Serving.html",
"reason": "Airflow를 활용한 배치 학습 및 서빙은 모델 학습 파이프라인 자동화 및 관리에 직접적",
"similarity": 0.85,
"method": "gemini-api"
},
{
"title": "개발 청사진 짜기",
"url": "/2025/01/11/개발-청사진-짜기.html",
"reason": "모델 개발 프로젝트의 청사진은 타겟 게시물의 내용을 실제 프로젝트에 적용하는 방법을 제시하",
"similarity": 0.8,
"method": "gemini-api"
},
{
"title": "On the difficulty of training Recurrent Neural Networks",
"url": "/paper_reviews/On-the-difficulty-of-training-Recurrent-Neural-Networks/",
"reason": "RNN 학습의 어려움에 대한 논문 리뷰는 모델 학습 과정에서 발생할 수 있는 문제점과 해결",
"similarity": 0.75,
"method": "gemini-api"
}
],
"/2024/08/25/Week3-주간-학습정리.html": [
{
"title": "Week8 주간 학습정리",
"url": "/2024/10/13/Week8-주간-학습정리.html",
"reason": "주간 학습 정리라는 동일한 포맷과 데이터 분석 관련 내용을 다루고 있어 연관성이 높습니다.",
"similarity": 0.9,
"method": "gemini-api"
},
{
"title": "knn 진짜 끝",
"url": "/2024/10/18/knn-진짜-끝.html",
"reason": "데이터 분석 관련 내용으로, 특히 KNN 모델은 데이터 시각화 및 분석에 활용될 수 있는 ",
"similarity": 0.8,
"method": "gemini-api"
},
{
"title": "콘텐츠 메타데이터 자동 생성 도구 만들기 모델작업",
"url": "/dev_logs/콘텐츠-메타데이터-자동-생성-도구-모델/",
"reason": "자연어 처리를 이용한 메타데이터 자동 생성은 데이터 분석과 관련된 내용을 처리하는 데 활용",
"similarity": 0.75,
"method": "gemini-api"
},
이제 TF-IDF기반 ML .json과 gemini기반 .json을 성능을 비교를 해야 되었는데 둘이 동일한 방식으로 만들어진게 아니다 보니까 성능지표를 비교하기가 애매했다.
그래서 두가지 방식으로 평가하기로 했다.
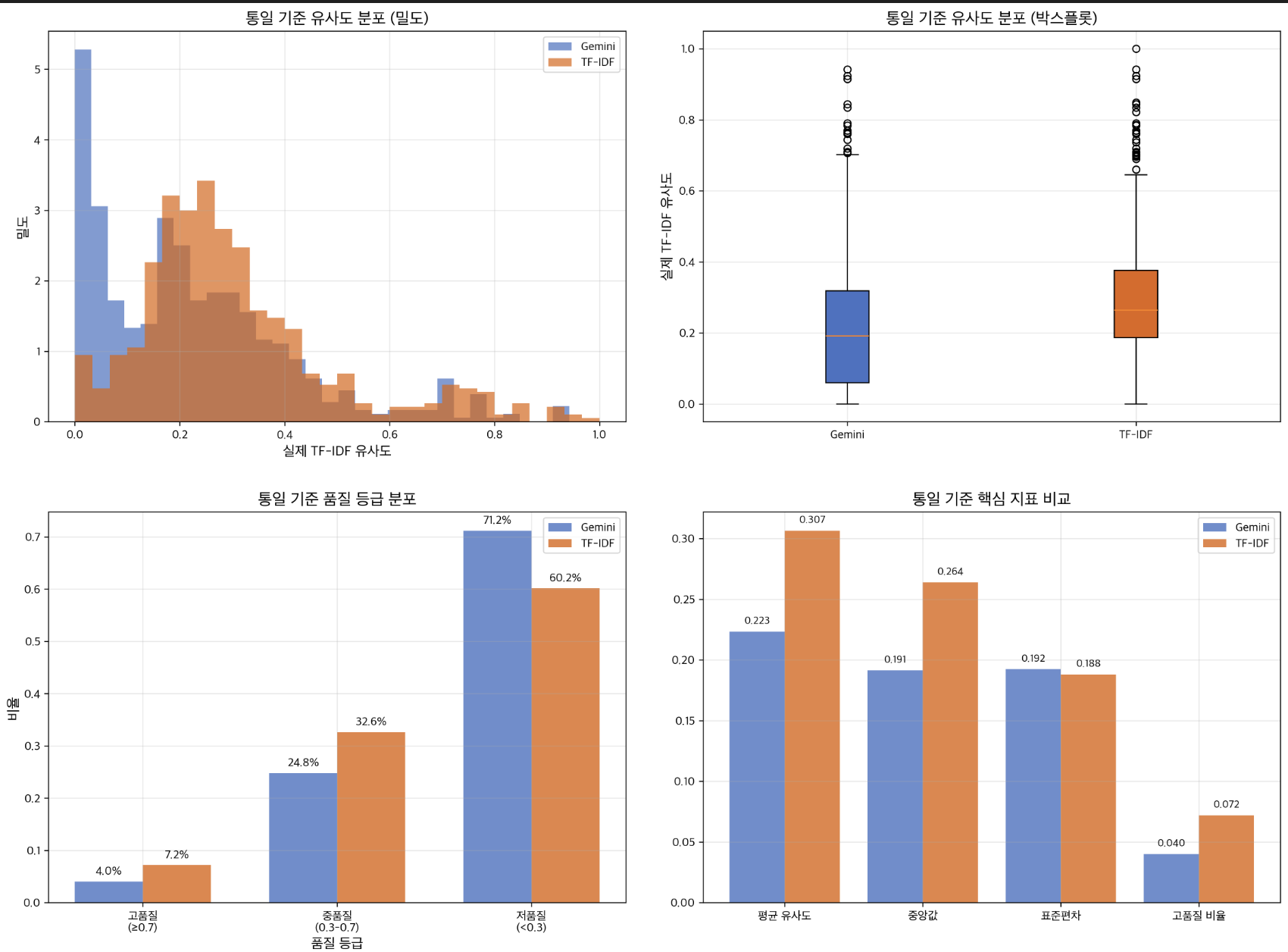
평가 방식 1: 통일된 TF-IDF 기준 (정량적)
Gemini: 0.223 vs TF-IDF: 0.307
→ TF-IDF 승리!
방법: 모든 추천을 동일한 TF-IDF 척도로 재평가
- 통계적 유의성: p < 0.0001
- 결론: 수학적으로 TF-IDF가 더 정확
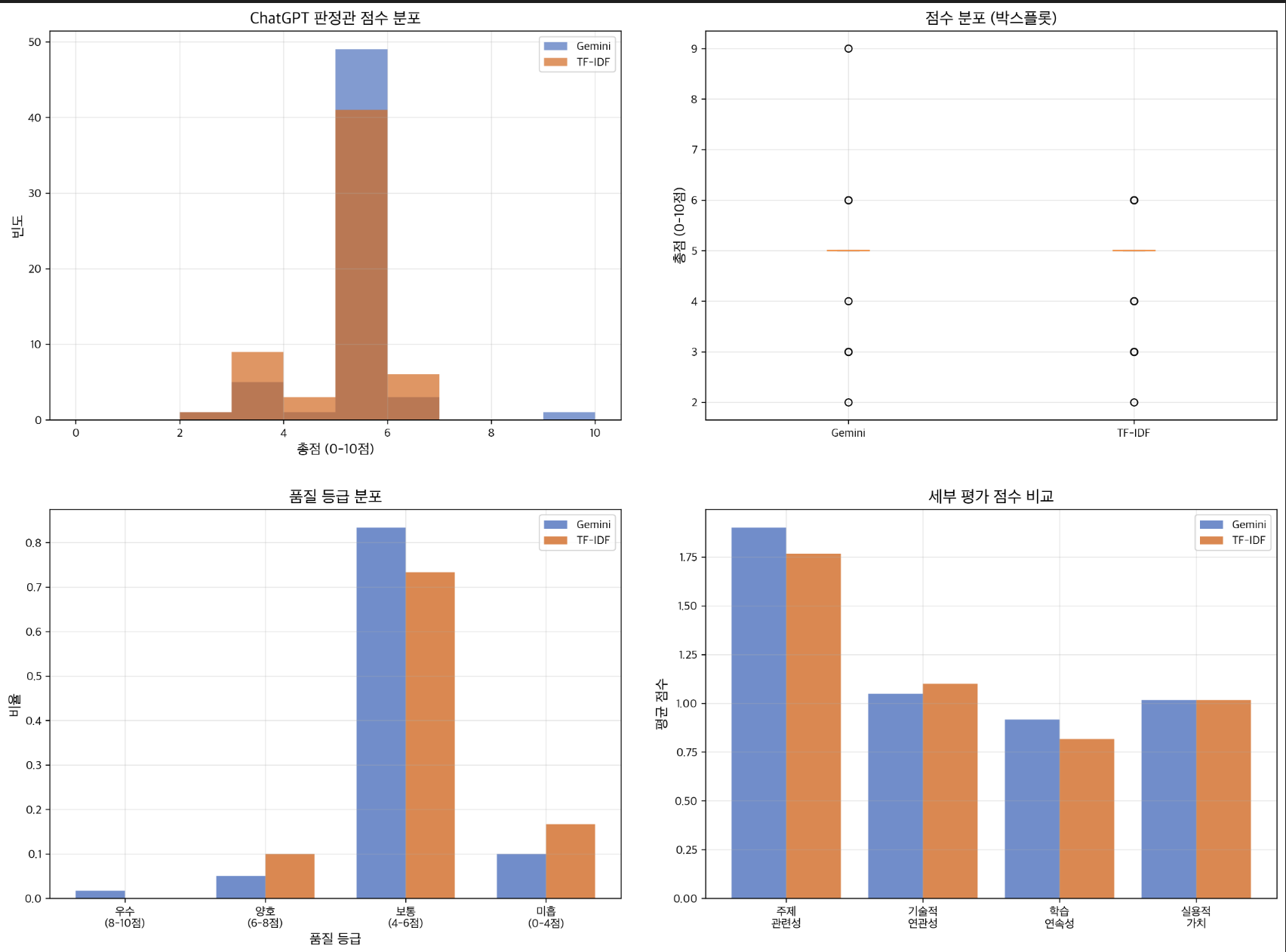
평가 방식 2: ChatGPT 판정관 (정성적)
데이터를 A라는 LLM으로 만들고 같은 LLM으로 채점하면 해당 LLM이 만든 데이터의 값에 더 좋은 평가를 내린다.
LLM Evaluators Recognize and Favor Their Own Generations
난 첨에 농담인줄 알았는데 진짜라서 놀란 기억이 있다. 찾아보면 자료 많으니 한번 찾아보길. 그래서 채점자 페르소나를 Chatgpt api를 활용하였다.
def create_evaluation_prompt(self, source_post: Dict, recommended_post: Dict, system_name: str) -> str:
"""평가용 프롬프트 생성"""
source_content = source_post['content'][:1000] # 토큰 절약
rec_content = recommended_post['content'][:1000]
prompt = f"""당신은 블로그 추천 시스템의 공정한 평가자입니다.
다음 추천의 품질을 객관적으로 평가해주세요.
**원본 게시물:**
제목: {source_post['title']}
카테고리: {source_post['collection']}
내용 (요약): {source_content}
**추천된 게시물:**
제목: {recommended_post['title']}
카테고리: {recommended_post['collection']}
내용 (요약): {rec_content}
**평가 기준:**
1. **주제 관련성** (0-3점): 주제가 얼마나 관련있는가?
2. **기술적 연관성** (0-3점): 기술 스택, 개념 등이 연관있는가?
3. **학습 연속성** (0-2점): 원본을 읽은 사람이 다음에 읽기 좋은가?
4. **실용적 가치** (0-2점): 실제로 도움이 될까?
**총점: 0-10점**
다음 JSON 형식으로만 응답해주세요:
topic_relevance
방법: ChatGPT를 중립적 평가자로 활용
- 평가 기준: 주제 관련성, 기술적 연관성, 학습 연속성, 실용적 가치
- 결론: 사용자 체감상 큰 차이 없음
ChatGPT 판정관이 평가한 실제 사례:
높은 점수 (6/10점):
{
"source_title": "콘텐츠 메타데이터 자동 생성 도구 backend작업",
"recommended_title": "콘텐츠 메타데이터 자동 생성 도구 모델작업",
"reasoning": "주제와 기술적 연관성이 있지만, 실용성은 낮음"
}
일반적인 점수 (5/10점):
{
"source_title": "Google Colab 유료 체험기",
"recommended_title": "FastAPI를 활용한 Online Serving",
"original_similarity": 0.9, // Gemini가 매긴 점수
"total_score": 5, // ChatGPT 실제 평가
"reasoning": "주제는 다르지만 기술적 요소가 일부 연결됨"
}
Gemini: 4.88/10 vs TF-IDF: 4.70/10
→ 거의 동등 (+0.18점)
최종 성능 비교
| 시스템 | 정량적 성능(TF-IDF기반) | 평균 점수(Chatgpt 페르소나 기반) |
|---|---|---|
| TF-IDF | 0.307 | 4.88/10 |
| Gemini | 0.223 | 4.70/10 |
결론
최종 선택: TF-IDF 시스템
이유:
- 객관적으로 더 정확함 (통계적 유의성 있음)
- 완전 무료 (운영비 절약)
- 안정적 성능 (API 제한 없음)
- 사용자 체감상 큰 차이 없음
향후 개선 방안
- TF-IDF 파라미터 추가 최적화
- 하이브리드 접근: TF-IDF 주력 + LLM 보조 역할
블로그 추천시스템 성능 개선 및 자동화 파이프라인 구축 프로젝트
📋 프로젝트 개요
Jekyll 블로그의 관련 게시물 추천 시스템을 개발하고, 성능을 객관적으로 평가하며, Airflow를 활용한 자동화 파이프라인까지 구축한 end-to-end ML 프로젝트입니다.
🎯 주요 성과
- 3가지 추천 알고리즘 구현 및 성능 비교
- 정량적/정성적 이중 평가 시스템 구축
- Airflow 기반 자동화 파이프라인 완성
- 146개 게시물 대상 실시간 추천 시스템 운영
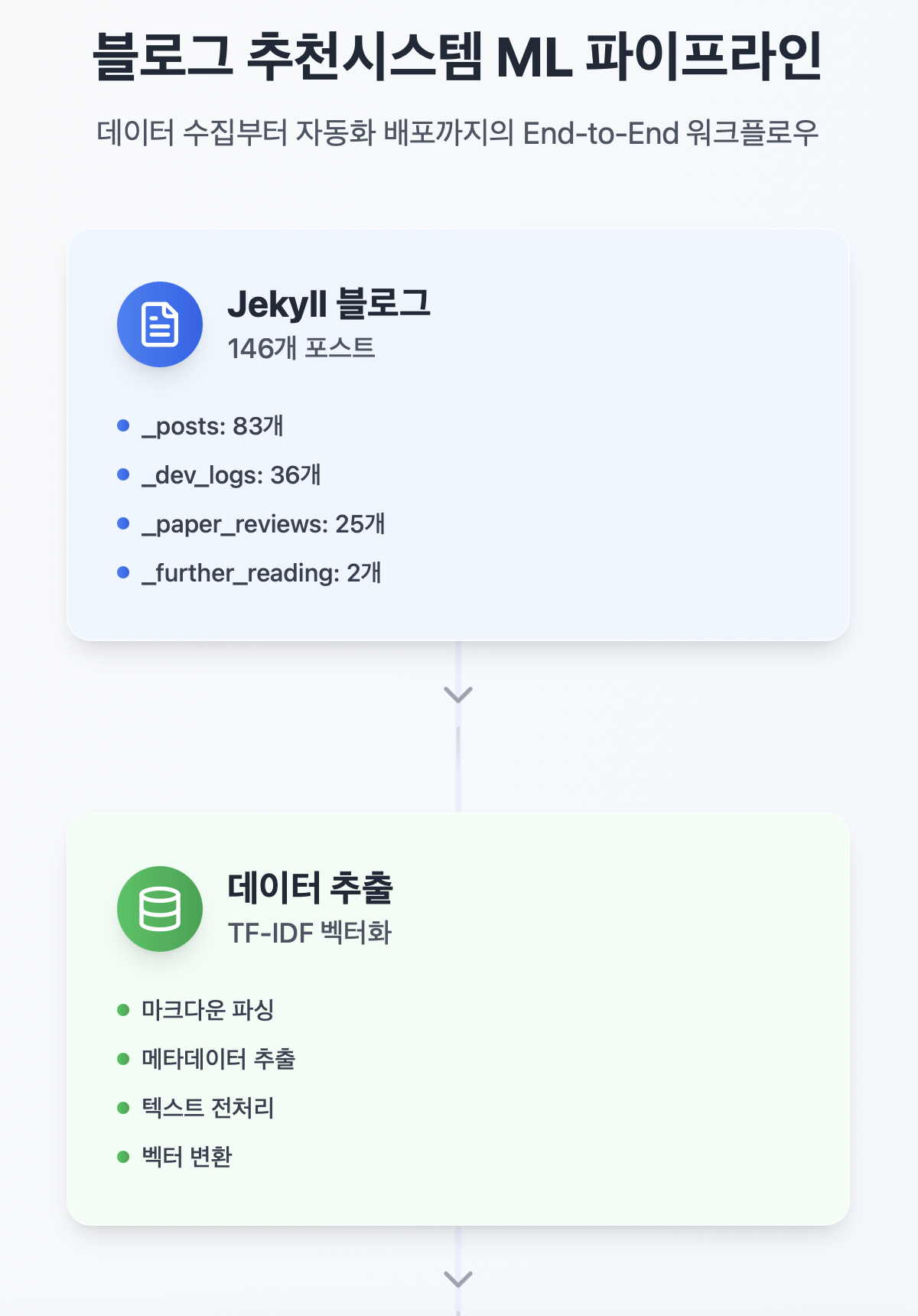
🏗️ 시스템 아키텍처
전체 워크플로우
기술 스택
- ML/NLP: scikit-learn, TF-IDF, 코사인 유사도
- LLM: Google Gemini API, OpenAI GPT-4o-mini
- 자동화: Apache Airflow
- 데이터: Jekyll 마크다운, YAML 메타데이터
- 평가: Leave-One-Out Cross Validation, LLM-as-Judge
🔬 구현된 추천 알고리즘
1. Baseline: 태그/카테고리 기반 매칭
- 단순한 규칙 기반 접근법
- 빠른 처리 속도, 해석 가능성 높음
2. TF-IDF + 코사인 유사도 (최종 선택)
# 최적화된 하이퍼파라미터
TfidfVectorizer(
max_features=2000,
ngram_range=(1, 3),
min_df=2,
max_df=0.8,
sublinear_tf=True
)
- 성능: 평균 유사도 0.307
- 특징: 안정적, 완전 무료, 높은 재현성
3. Gemini API 기반 LLM 추천
def create_recommendation_prompt(target_post, candidates):
prompt = f"""블로그 추천 전문가로서 다음 기준으로 추천:
1. 내용의 의미적 연관성
2. 독자에게 유용한 연속성
3. 카테고리 다양성
타겟: {target_post}
후보: {candidates}
"""
return prompt
- 성능: 평균 유사도 0.223
- 특징: 의미적 이해 우수, 높은 운영 비용
4. 하이브리드 최적화 시도
- 다중 TF-IDF + 카테고리 보너스 + 날짜 근접성
- 결과: 0.261로 기존 대비 성능 저하
- 교훈: 복잡한 알고리즘이 항상 좋은 것은 아님
📊 성능 평가 시스템
이중 평가 방법론
1. 정량적 평가: 통일된 TF-IDF 기준
def unified_evaluation(recommendations):
# 모든 추천을 동일한 TF-IDF 척도로 재평가
real_similarity = cosine_similarity(
unified_tfidf_matrix[source_idx],
unified_tfidf_matrix[target_idx]
)
return real_similarity
결과:
- TF-IDF: 0.307 (승리)
- Gemini: 0.223
- 통계적 유의성: p < 0.0001
2. 정성적 평가: ChatGPT 판정관
def create_evaluation_prompt(source_post, recommended_post):
return f"""추천 품질을 다음 기준으로 평가 (0-10점):
1. 주제 관련성 (0-3점)
2. 기술적 연관성 (0-3점)
3. 학습 연속성 (0-2점)
4. 실용적 가치 (0-2점)
"""
결과:
- Gemini: 4.88/10점
- TF-IDF: 4.70/10점
- 차이: +0.18점 (미미한 우위)
평가 결과 종합
| 방식 | 정량적 성능 | 정성적 점수 | 운영비용 | 최종 선택 |
|---|---|---|---|---|
| TF-IDF | 0.307 | 4.70/10 | 무료 | ✅ 채택 |
| Gemini | 0.223 | 4.88/10 | 유료 | 미채택 |
선택 이유: 객관적으로 더 정확하고, 완전 무료이며, 사용자 체감상 큰 차이 없음
🚀 Airflow 자동화 파이프라인
DAG 구조
dag = DAG(
'blog_recommendation_pipeline',
schedule=None, # 수동 실행 또는 '0 2 * * *' (매일 새벽 2시)
start_date=datetime(2025, 6, 26),
tags=['blog', 'recommendation', 'ml']
)
7단계 워크플로우
- 시스템 상태 확인 (
check_system_status)- 필수 경로 및 스크립트 존재 확인
- 블로그 저장소 접근 가능성 검증
- 새 게시물 감지 (
check_new_posts)- 마지막 업데이트 이후 변경된 파일 탐지
- 146개 포스트 중 신규/수정 항목 식별
- 데이터 추출 (
extract_data)
# 4개 컬렉션에서 마크다운 파일 추출
collections = {
'_posts': 'post', # 83개 포스트
'_dev_logs': 'dev_log', # 36개 포스트
'_paper_reviews': 'paper_review', # 25개 포스트
'_further_reading': 'further_reading' # 2개 포스트
}
- 추천 생성 (
generate_recommendations)- TF-IDF 벡터화 및 코사인 유사도 계산
- 각 포스트별 상위 4개 관련 게시물 추천
- 검증 및 메타데이터 저장 (
validate_and_save_metadata)- 추천 품질 검증 (빈 추천, 중복 URL 확인)
- 실행 메타데이터 생성 및 저장
- Git 자동 배포 (
deploy_to_git)
git add _data/related_posts.json _data/last_recommendation_update.json
git commit -m "자동 추천 업데이트 - $(date)"
git push origin main
-
완료 알림
(
send_notification)
- Slack 웹훅을 통한 실행 결과 알림
- 성공/실패 상태 및 처리된 게시물 수 리포트
모니터링 및 로깅
- 실시간 로그: 각 태스크별 상세 실행 로그
- 시각적 모니터링: Airflow UI를 통한 DAG 상태 확인
- 오류 처리: 실패 시 자동 재시도 및 알림
📈 주요 성과 및 인사이트
1. 알고리즘 성능 분석
- TF-IDF의 우수성: 전통적 ML 방법론의 안정성 입증
- LLM의 한계: 높은 비용 대비 미미한 성능 향상
- 단순함의 가치: 복잡한 하이브리드 모델의 성능 저하
2. 평가 방법론 혁신
- 이중 평가 체계: 정량적/정성적 관점의 균형잡힌 평가
- LLM-as-Judge: ChatGPT를 중립적 평가자로 활용
- 통계적 엄밀성: p-value를 통한 유의성 검정
3. 엔지니어링 우수성
- 완전 자동화: 수동 개입 없는 end-to-end 파이프라인
- 확장 가능성: 새로운 알고리즘 추가 용이한 구조
- 운영 안정성: 오류 처리 및 백업 시스템 구축
🛠️ 기술적 도전과 해결
1. Airflow 호환성 문제
문제: 버전별 import 경로 차이로 DAG 실행 실패
# 해결: 호환성을 위한 다중 import 처리
try:
from airflow.operators.python import PythonOperator
except ImportError:
from airflow.operators.python_operator import PythonOperator
2. 경로 관리 복잡성
문제: 상대/절대 경로 혼재로 스크립트 실행 실패 해결: Variables를 통한 중앙집중식 경로 관리
3. LLM 평가 편향성
문제: 동일 LLM으로 생성과 평가 시 편향 발생 해결: 서로 다른 LLM 사용 (Gemini 생성 → ChatGPT 평가)
##
이 프로젝트는 단순한 추천 시스템을 넘어서, ML 모델의 객관적 평가, 자동화된 배포 파이프라인, 그리고 실제 운영 환경에서의 안정성까지 고려한 종합적인 엔지니어링 프로젝트입니다.