앙상블
앙상블이란?
앙상블은 여러 개의 모델을 결합하여 더 나은 예측 성능을 얻는 기법
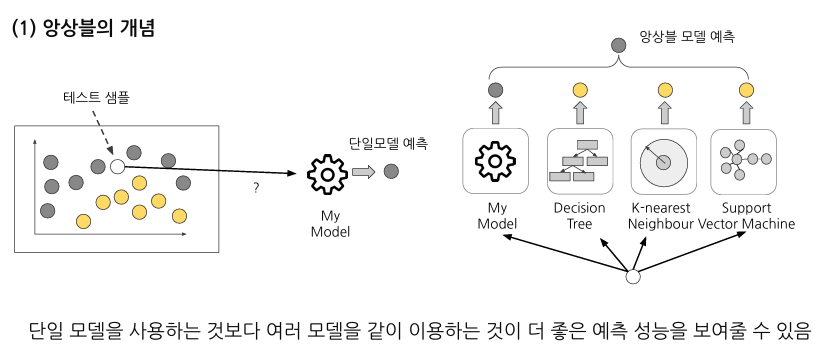
앙상블의 종류
Bagging (Bootstrap Aggregating)
- 데이터를 여러 번 샘플링하여 여러 모델을 학습시키고, 그 결과를 집계하는 방식
- 대표적인 예: Random Forest
Boosting
- 이전 모델의 오류를 보완하는 방식으로 순차적으로 모델을 학습
- 대표적인 예: AdaBoost, Gradient Boosting
모델의 분산과 편향
앙상블의 효과를 이해하기 위해서는 모델의 분산(Variance)과 편향(Bias)을 이해해야 합니다.
- 편향: 예측값이 실제값과 얼마나 다른지를 나타냅니다.
- 분산: 같은 입력에 대해 모델의 예측이 얼마나 일관적인지를 나타냅니다.
앙상블은 이 분산과 편향을 모두 줄이는 효과가 있습니다.

교차검증을 응용한 앙상블 기법
교차검증 앙상블은 데이터를 여러 폴드로 나누어 학습하고, 각 모델의 예측을 종합하여 최종 예측을 만드는 방법
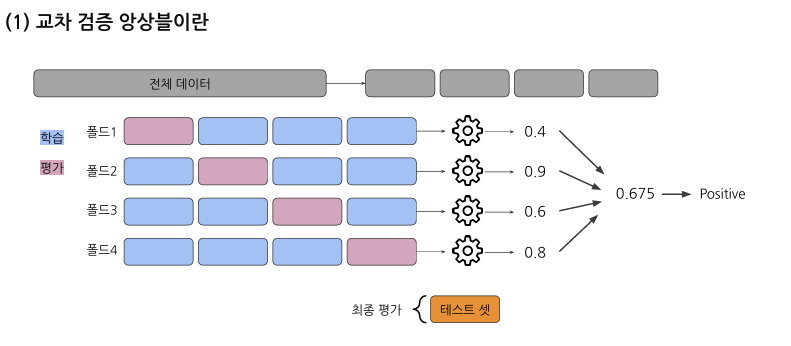
장점:
- 모델의 일반화 성능 평가 향상
- 과적합 방지
- 안정된 성능 평가
단점:
- 시간과 계산 비용 증가
- 구현의 복잡성
- 충분한 데이터 필요
스태킹 앙상블 기법
스태킹 앙상블은 여러 모델의 예측 결과를 입력으로 받아 최종 예측을 만드는 메타 모델을 학습하는 방법

-
기본 모델들을 학습시켜 예측 결과를 얻습니다.
-
이 예측 결과들을 새로운 특성으로 사용하여 메타 모델을 학습시킵니다.
-
메타 모델의 예측을 최종 예측으로 사용합니다.
장점:
- 일반화 성능 향상
- 복잡한 패턴 학습 가능
- 다양한 모델 결합의 유연성
단점:
- 시간과 계산 비용 증가
- 구현의 복잡성
- 적절한 모델 선택의 어려움