블로그 추천시스템 성능 개선 프로젝트2
우선 데이터 추출 스크립트를 만들어 데이터를 하나의 .csv파일로 만들어 추출했음. 20000줄 정도 나왔음.
첨에 .md만 추출햇는데 .md랑 .markdown이 섞여있어서 다시 통합해서 추출함.
python scripts/data_extraction.py --blog_path "../../ardkyer.github.io" ✔ │ base Py
🚀 데이터 추출 시작 (.md + .markdown)
📁 _posts 처리 중...
📄 파일 수: 83개
📁 _dev_logs 처리 중...
📄 파일 수: 34개
📁 _further_reading 처리 중...
📄 파일 수: 2개
📁 _paper_reviews 처리 중...
📄 파일 수: 25개
\n📊 총 144개 파일 발견
\n✅ 144개 파일 추출 완료!
\n📁 컬렉션별 분포:
post: 83개 (평균 463.6단어)
dev_log: 34개 (평균 690.1단어)
further_reading: 2개 (평균 54.5단어)
paper_review: 25개 (평균 647.9단어)
\n📄 파일 확장자 분포:
.md: 93개
.markdown: 51개
\n📁 저장 완료: data/raw/all_posts_dataset.csv
\n🔍 샘플 데이터:
filename collection title word_count
0 2024-12-17- FastAPI를 활용한 Online Serving.md post FastAPI를 활용한 Online Serving 308
1 2024-10-29- 추천시스템1.md post 베이스라인 오피스아워 5
2 2024-10-07- 공원,학교 피처 돌려보기.md post 공원, 학교 피처 베이스라인에 넣어보기 411
3 2024-09-13- 모델 학습 파이프라인.md post 모델 학습 파이프라인 624
4 2024-08-25-Week3 주간 학습정리.markdown post Week3 주간 학습정리 58
우선 기존의 블로그들의 추천시스템 성능지표를 평가함.
근데 이거 어케 나온거지? 해서 코드를 하나하나씩 좀 뜯어보기로 함.
python scripts/baseline_analysis.py 1 х │ base Py
🚀 베이스라인 추천시스템 분석 시작
============================================================
📊 데이터 로드 중...
✅ 게시물 데이터: 144개
✅ 기존 추천 데이터: 65개 게시물
============================================================
📋 베이스라인 성능 요약
============================================================
🔬 베이스라인 관련성 분석
==================================================
평균 관련성 점수: 0.105
분석된 추천 수: 229개
🎯 추천 다양성 분석...
평균 다양성 점수: 0.225
📈 추천 커버리지 분석...
커버리지: 0.174 (17.4%)
🔍 추천 패턴 분석...
게시물당 평균 추천 수: 4.6개
가장 많이 사용된 이유: 태그와 카테고리 유사성...
📊 데이터 요약:
- 총 게시물: 144개
- 추천 시스템 적용 게시물: 65개
🎯 베이스라인 성능:
- 관련성 점수: 0.105
- 다양성 점수: 0.225
- 커버리지: 0.174
📈 성능 평가:
❌ 관련성 점수가 매우 낮습니다 (0.2 미만)
❌ 다양성이 매우 낮습니다
❌ 커버리지가 매우 낮습니다
💾 결과 저장 완료: results/baseline/baseline_analysis.json
🎉 베이스라인 분석 완료!
💡 다음 단계: 커스텀 ML 모델 개발로 성능 개선
🎯 목표: 관련성 점수 0.105 → 0.4+ (100%+ 개선)
BaselineAnalyzer 클래스
├─ __init__ : 파일 경로, 데이터 초기화
├─ load_data : 게시물 CSV + 기존 추천 JSON 로드
├─ calculate_baseline_relevance : TF-IDF + cosine similarity로 관련성 계산
├─ calculate_diversity_score : 추천들의 collection 다양성 측정
├─ calculate_coverage : 추천된 게시물들이 전체 dataset의 몇 %인지
├─ analyze_recommendation_patterns : 추천 갯수, 이유 통계 분석
├─ generate_summary_report : 모든 지표 종합 + 출력 + 저장
└─ run_analysis : 전체 분석 프로세스 실행
보조 함수
└─ convert_numpy_types : numpy 타입을 Python 타입으로 바꿔 JSON 저장 대응
기존 related_posts.json파일을 가져와서 평가한다. 여기서 related_posts.json가 무엇이냐면
def load_data(self):
"""데이터 로드"""
print("📊 데이터 로드 중...")
self.df = pd.read_csv(self.data_path)
print(f"✅ 게시물 데이터: {len(self.df)}개")
try:
rec_path = os.path.join(self.blog_path, '_data', 'related_posts.json')
with open(rec_path, 'r', encoding='utf-8') as f:
self.existing_recs = json.load(f)
print(f"✅ 기존 추천 데이터: {len(self.existing_recs)}개 게시물")
except Exception as e:
print(f"⚠️ 기존 추천 데이터 로드 실패: {e}")
self.existing_recs = {}
기존 추천시스템이 구성되는 파일이다. 몇 개월전에 만든 파일인데 Claude API를 활용해 모든 파일들을 전부 다 읽고 하나하나 체크해가며 가장 유사도 높은걸 3개씩 저장해서 나오는 구조였다.
윗부분만 봤을때는 꽤나 잘 나오는 것 같지만
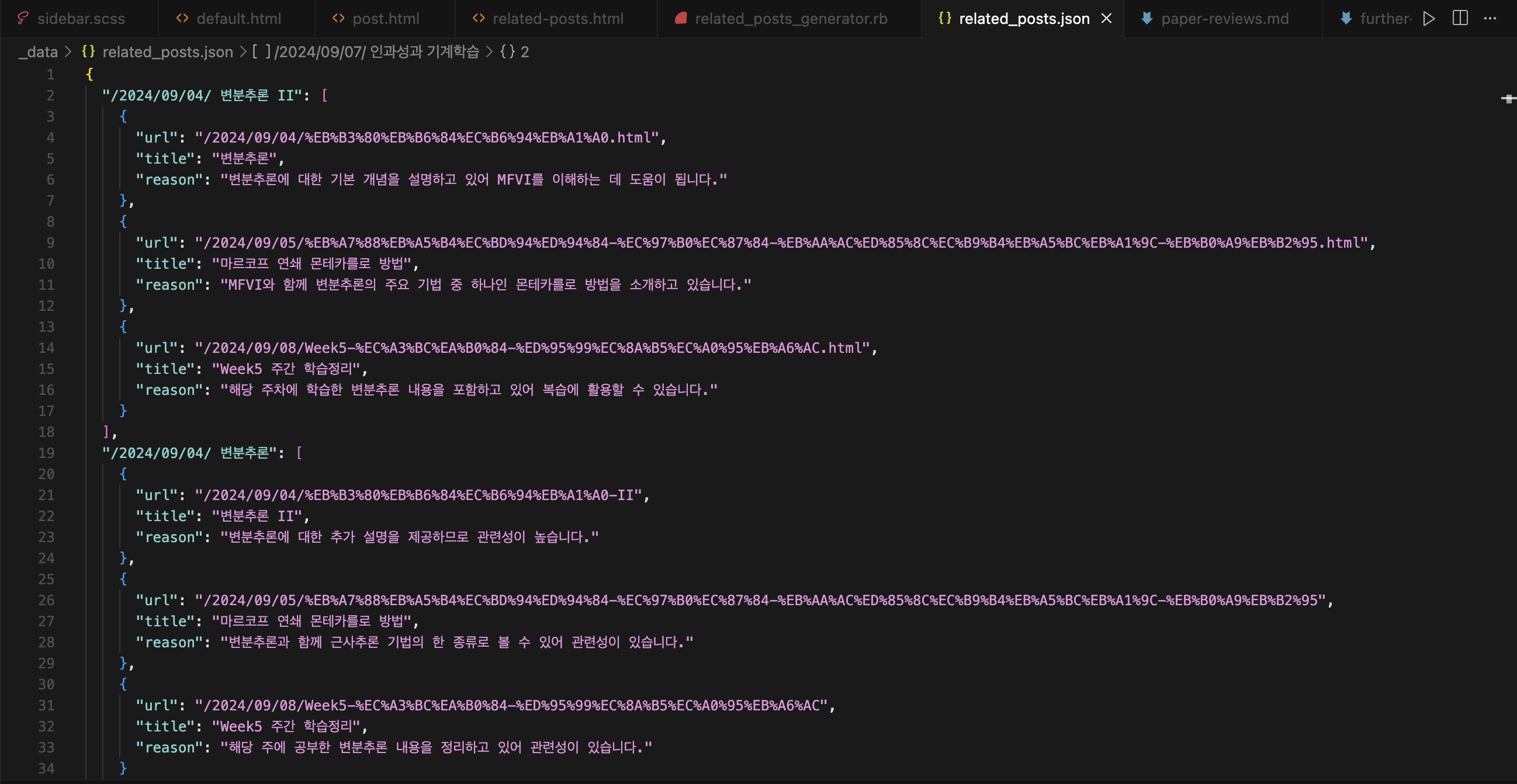
이게 Claude API가 순식간에 빨려가지고 중간부터는 다음과 같이 산출되는 문제가 있었다. 원래 API가 다 닳으면 다른 모델이라도 폴백 해놨어야 하는데 API비용이 부족할지 상상하지 못한 탓이다. 그것이 성능을 체크했을때 0.1~0.2를 상회하는 이유고. 사실 이때 다른 AI API 여러방면으로 테스트해볼때였는데 Claude API 가 개인적으로 최악이었다. 말도 안되게 비싸다. 아마 이번에 API는 Geminai를 활용할것 같다.
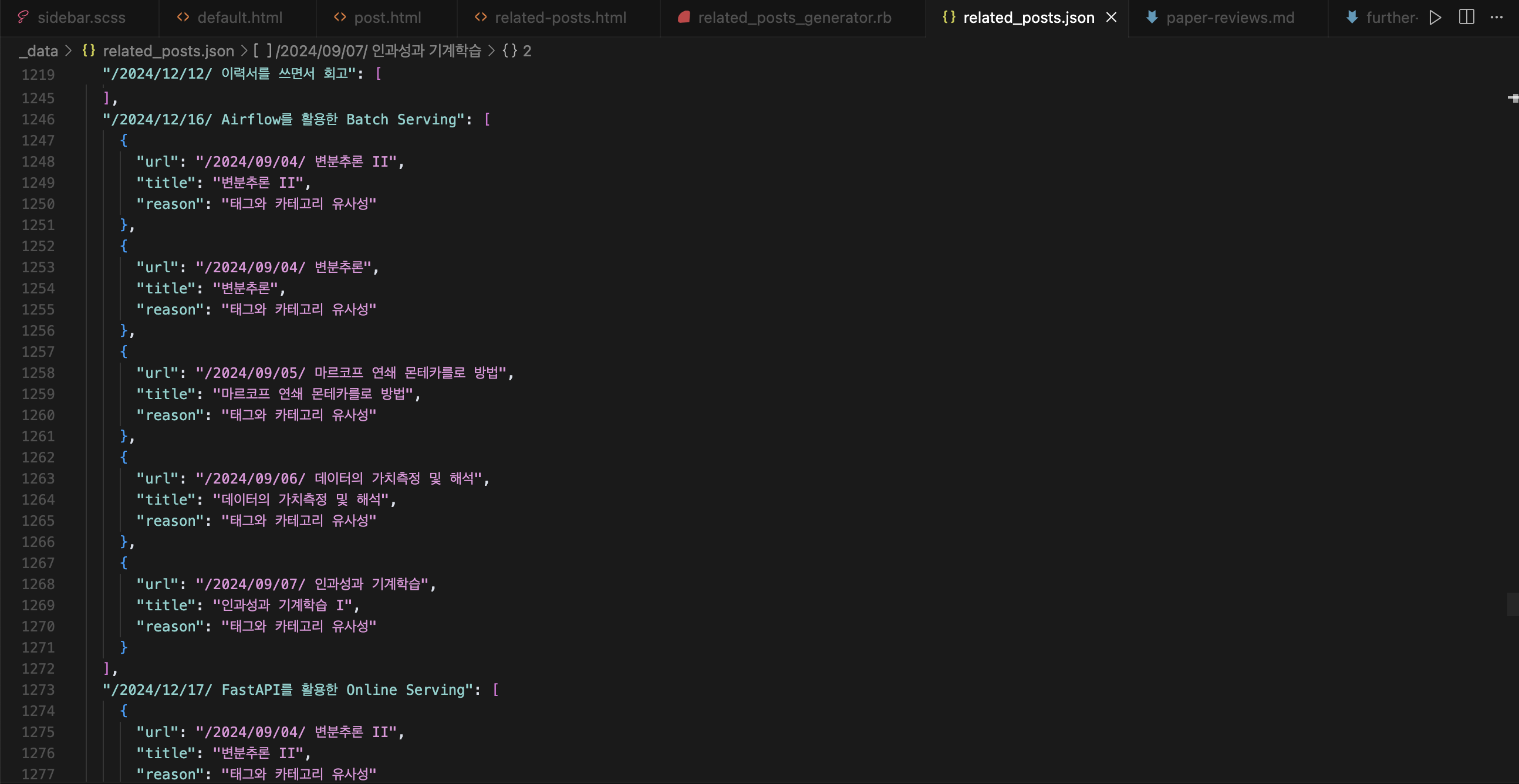
기존코드
#!/usr/bin/env python3
"""
간결한 베이스라인 관련성 점수 분석 스크립트
"""
import pandas as pd
import json
import numpy as np
import os
import argparse
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class SimpleRelevanceAnalyzer:
def __init__(self, data_path='data/raw/all_posts_dataset.csv',
blog_path='../../ardkyer.github.io'):
self.data_path = data_path
self.blog_path = blog_path
self.df = None
self.existing_recs = {}
def load_data(self):
"""데이터 로드"""
print("📊 데이터 로드 중...")
self.df = pd.read_csv(self.data_path)
print(f"✅ 게시물 데이터: {len(self.df)}개")
try:
rec_path = os.path.join(self.blog_path, '_data', 'related_posts.json')
with open(rec_path, 'r', encoding='utf-8') as f:
self.existing_recs = json.load(f)
print(f"✅ 기존 추천 데이터: {len(self.existing_recs)}개 게시물")
except Exception as e:
print(f"⚠️ 기존 추천 데이터 로드 실패: {e}")
self.existing_recs = {}
def calculate_relevance_score(self, sample_size=50):
"""관련성 점수 계산 (코사인 유사도 기반)"""
print("🔬 관련성 점수 분석 중...")
if not self.existing_recs:
print("❌ 추천 데이터가 없습니다")
return 0.0
# TF-IDF 벡터화
vectorizer = TfidfVectorizer(max_features=1000, stop_words='english')
tfidf_matrix = vectorizer.fit_transform(self.df['content'].fillna(''))
relevance_scores = []
for url, recs in list(self.existing_recs.items())[:sample_size]:
# 현재 포스트 찾기
current_post_idx = None
url_filename = url.split('/')[-1]
for idx, row in self.df.iterrows():
if (url_filename in row['filename'] or
row['filename'].replace('.md', '').replace('.markdown', '') in url):
current_post_idx = idx
break
if current_post_idx is None:
continue
# 각 추천 항목과의 유사도 계산
for rec in recs:
rec_post_idx = None
for idx, row in self.df.iterrows():
if rec['title'] in row['title'] or row['title'] in rec['title']:
rec_post_idx = idx
break
if rec_post_idx is not None:
similarity = cosine_similarity(
tfidf_matrix[current_post_idx],
tfidf_matrix[rec_post_idx]
)[0][0]
relevance_scores.append(similarity)
if relevance_scores:
avg_relevance = float(np.mean(relevance_scores))
print(f"📊 평균 관련성 점수: {avg_relevance:.3f}")
print(f"📈 분석된 추천 수: {len(relevance_scores)}개")
return avg_relevance
else:
print("❌ 분석 가능한 추천이 없습니다")
return 0.0
def run_analysis(self):
"""분석 실행"""
print("🚀 관련성 점수 분석 시작")
print("="*50)
try:
self.load_data()
relevance_score = self.calculate_relevance_score()
print("\n" + "="*50)
print("📋 분석 결과")
print("="*50)
print(f"🎯 관련성 점수: {relevance_score:.3f}")
# 성능 평가
if relevance_score < 0.2:
print("❌ 관련성 점수가 매우 낮습니다 (< 0.2)")
improvement_needed = (0.4 - relevance_score) / relevance_score * 100
print(f"💡 목표 달성을 위해 {improvement_needed:.0f}% 개선 필요")
elif relevance_score < 0.4:
print("⚠️ 관련성 점수가 낮습니다 (< 0.4)")
improvement_needed = (0.4 - relevance_score) / relevance_score * 100
print(f"💡 목표 달성을 위해 {improvement_needed:.0f}% 개선 필요")
else:
print("✅ 관련성 점수가 양호합니다")
print(f"\n🎉 분석 완료!")
return relevance_score
except Exception as e:
print(f"❌ 분석 중 오류 발생: {e}")
raise
def main():
parser = argparse.ArgumentParser(description="관련성 점수 분석")
parser.add_argument('--data_path', default='data/raw/all_posts_dataset.csv')
parser.add_argument('--blog_path', default='../../ardkyer.github.io')
parser.add_argument('--sample_size', type=int, default=50, help='분석할 샘플 크기')
args = parser.parse_args()
analyzer = SimpleRelevanceAnalyzer(args.data_path, args.blog_path)
score = analyzer.run_analysis()
return score
if __name__ == "__main__":
main()
여기서
vectorizer = TfidfVectorizer(max_features=1000, stop_words='english')
tfidf_matrix = vectorizer.fit_transform(self.df['content'].fillna(''))
TfidfVectorizer가 무엇인지 알아보자.
CountVectorizer를 통해 자연어를 벡터화하는 경우 발생할 수 있는 문제점(의미 없이 자주 사용되는 단어의 가중치의 증가 등)을 해결하기 위한 방법 중 하나가 TfidfVectorizer다.
그렇다면 CountVectorizer란?
텍스트(문장)를 단어의 등장 횟수(Count)로 벡터화하는 도구
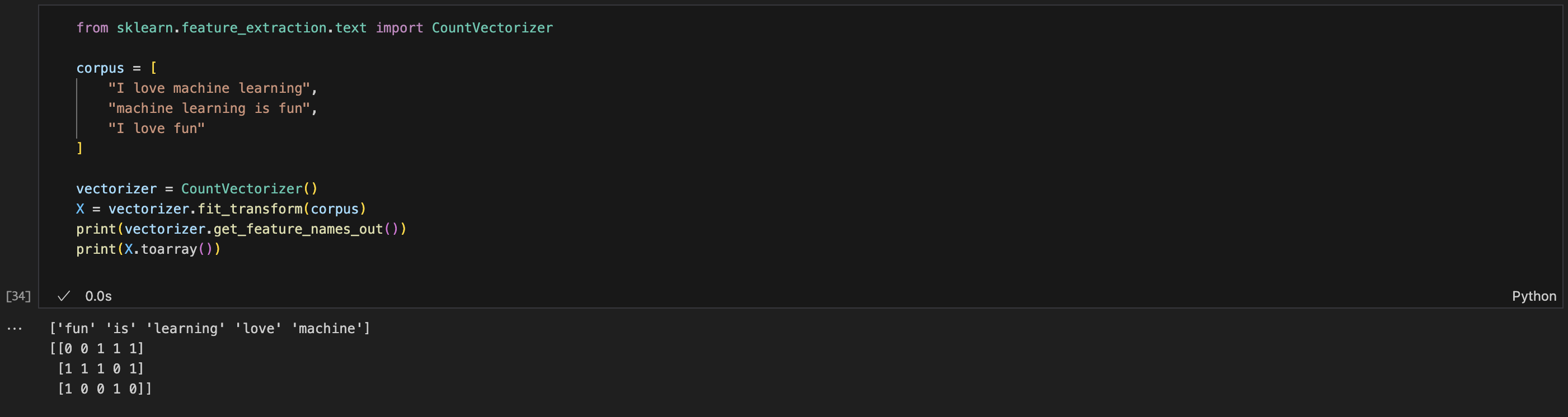
아마 이 예제만 보면 쉽게 이해할 수 있을것이라고 생각한다.
각 행 = 문장
각 열 = 단어
값 = 해당 단어가 문장에 등장한 횟수 (TF)
CountVectorizer의 문제점
1. 너무 흔한 단어가 중요 단어처럼 처리됨
- 예: “the”, “is”, “and”, “I”, “you” 같은 단어들
- 문맥에는 큰 의미 없지만, 문서에 자주 등장해서 높은 가중치를 갖게 됨
2. 단어 중요도를 판단할 수 없음
- Count는 단순 횟수 → 어떤 단어가 전체 문서 중 희귀하거나 중요한지 판단 못함
3. 벡터 크기가 커짐 (희소 행렬 문제)
- 전체 말뭉치에 단어가 10,000개면 → 벡터 차원도 10,000
해결책 = TfidfVectorizer
TF (단어 빈도) × IDF (희귀성) → 단어의 중요도를 반영
- 흔한 단어 → 낮은 점수
- 희귀하고 특정 문서에만 자주 쓰이는 단어 → 높은 점수
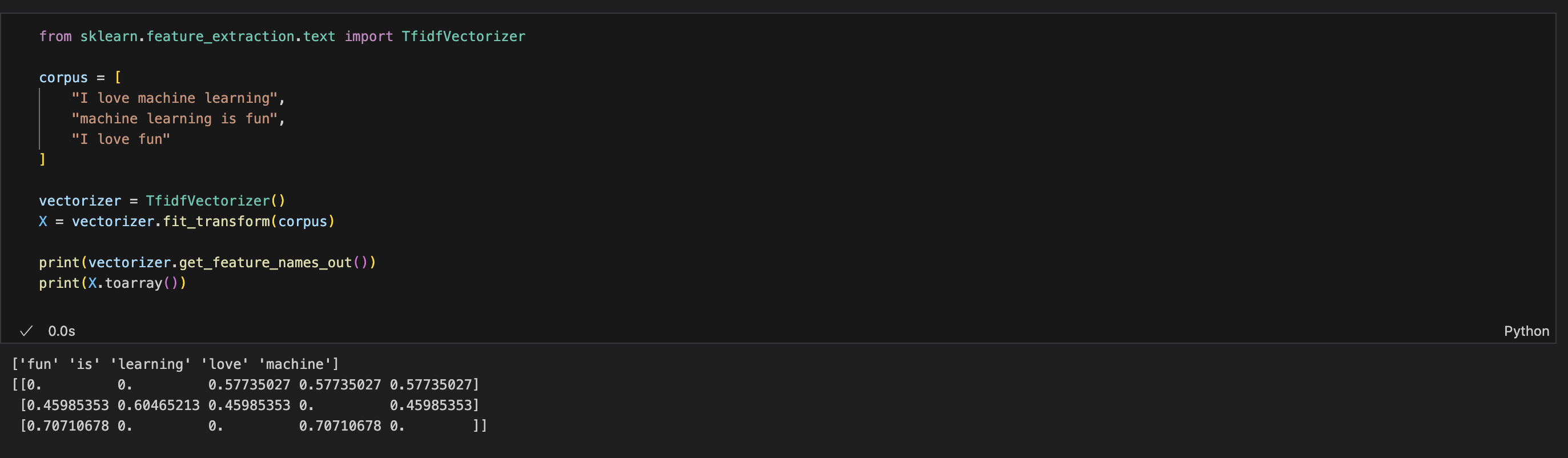
함수만 바꿧더니 이렇게 나온다.
좀 더 수학적으로 구체화하자면
corpus = [
'you know I want your love',
'I like you',
'what should I do'
]
📌 단어별 IDF 값
do: 1.693
know: 1.693
like: 1.693
love: 1.693
should: 1.693
want: 1.693
what: 1.693
you: 1.288
your: 1.693
📌 문서별 TF (Term Frequency)
문서 1: {'you': np.float64(0.16666666666666666), 'know': np.float64(0.16666666666666666), 'want': np.float64(0.16666666666666666), 'your': np.float64(0.16666666666666666), 'love': np.float64(0.16666666666666666), 'like': 0.0, 'what': 0.0, 'should': 0.0, 'do': 0.0}
문서 2: {'you': np.float64(0.3333333333333333), 'know': 0.0, 'want': 0.0, 'your': 0.0, 'love': 0.0, 'like': np.float64(0.3333333333333333), 'what': 0.0, 'should': 0.0, 'do': 0.0}
문서 3: {'you': 0.0, 'know': 0.0, 'want': 0.0, 'your': 0.0, 'love': 0.0, 'like': 0.0, 'what': np.float64(0.25), 'should': np.float64(0.25), 'do': np.float64(0.25)}
📌 정규화 전 TF×IDF 매트릭스
do know like love should want what you your
0 0.000 1.693 0.000 1.693 0.000 1.693 0.000 1.288 1.693
1 0.000 0.000 1.693 0.000 0.000 0.000 0.000 1.288 0.000
2 1.693 0.000 0.000 0.000 1.693 0.000 1.693 0.000 0.000
you know I want your love
📌 L2 정규화된 TF×IDF 매트릭스
do know like love should want what you your
0 0.000 0.467 0.000 0.467 0.000 0.467 0.000 0.355 0.467
1 0.000 0.000 0.796 0.000 0.000 0.000 0.000 0.605 0.000
2 0.577 0.000 0.000 0.000 0.577 0.000 0.577 0.000 0.000
cosine similarity, clustering 등에 바로 사용 가능할수 있도록 TF×IDF 매트릭스 = (TF × IDF) 정규화된 값

수학적으로는 너무 들어가지 말자. 그래서 간단히 정리하자면
TF (Term Frequency)
- 문서에서 단어의 상대적 등장 비율
IDF (Inverse Document Frequency)
- 전체 문서 중 희귀할수록 IDF 높음
TF-IDF = TF × IDF
- 흔한 단어 → 낮은 점수
- 희귀 단어 → 높은 점수
L2 정규화
- 벡터 길이를 1로 맞춤 → 코사인 유사도 계산 최적화
다시 이제 원래 코드로 돌아와서 GPT가 써준 코드는 다음과 같았다. 여기서 stop_words 파라미터의 효용성에 대해 찾아보았다. 저게 무엇이고 왜 쓰이는지.
# TF-IDF 벡터화
vectorizer = TfidfVectorizer(max_features=1000, stop_words='english')
tfidf_matrix = vectorizer.fit_transform(self.df['content'].fillna(''))

영어만 불용어(at, is, …) 등을 제거해주는거 같다. 아직은 영어만 지원하는 듯. 실제로 해당 파라미터를 지워도 관련성 점수는 변하지 않았다.
https://foreverhappiness.tistory.com/30
아마 OKP, KoNLPy등 한글 전용이 많은 걸로 알고잇는데 이건 나중에 해보자. NLP강의를 다 들어야대나. 나중에 공부해보고 바꿔서 적용해본는 것도 재밌을듯.
자. 다시 코드로 돌아와서 우린 지금까지 이 함수에 대해 뜯어보고 있었다. 예제를 통해 어케 돌아가나 살펴보자.
def calculate_baseline_relevance(self, sample_size=50):
"""베이스라인 관련성 점수 계산"""
예제
데이터프레임 (self.df):
idx filename title content
0 python-basics.md "Python 기초 문법" "변수, 함수, 클래스에 대해..."
1 django-tutorial.md "Django 웹 개발" "웹 프레임워크 Django로..."
2 data-analysis.md "데이터 분석 기초" "pandas, numpy를 활용한..."
3 machine-learning.md "머신러닝 입문" "scikit-learn을 사용해서..."
기존 추천 데이터 (related_posts.json):
{
"blog.com/python-basics": [
{"title": "Django 웹 개발"},
{"title": "데이터 분석 기초"}
],
"blog.com/django-tutorial": [
{"title": "Python 기초 문법"},
{"title": "머신러닝 입문"}
]
}
단계별 실행 과정
1단계: TF-IDF 벡터화
# 각 content를 TF-IDF 벡터로 변환
tfidf_matrix = [
[0.2, 0.8, 0.1, 0.0], # python-basics.md 벡터
[0.1, 0.3, 0.0, 0.9], # django-tutorial.md 벡터
[0.0, 0.4, 0.8, 0.2], # data-analysis.md 벡터
[0.3, 0.1, 0.6, 0.4] # machine-learning.md 벡터
]
2단계: 첫 번째 URL 처리
url = "blog.com/python-basics"
recs = [{"title": "Django 웹 개발"}, {"title": "데이터 분석 기초"}]
# URL에서 파일명 추출
url_filename = "python-basics" # url.split('/')[-1]
# 현재 포스트 찾기
for idx, row in df.iterrows():
if "python-basics" in row['filename']: # python-basics.md
current_post_idx = 0 # 찾음!
break
3단계: 첫 번째 추천 항목 처리
rec = {"title": "Django 웹 개발"}
# 추천 포스트 찾기
for idx, row in df.iterrows():
if "Django 웹 개발" in row['title']:
rec_post_idx = 1 # django-tutorial.md 찾음!
break
# 유사도 계산
similarity = cosine_similarity(
tfidf_matrix[0], # python-basics.md 벡터
tfidf_matrix[1] # django-tutorial.md 벡터
)
# 결과: 0.234 (예시)
relevance_scores.append(0.234)
4단계: 두 번째 추천 항목 처리
rec = {"title": "데이터 분석 기초"}
# 추천 포스트 찾기 -> data-analysis.md (idx=2)
similarity = cosine_similarity(
tfidf_matrix[0], # python-basics.md 벡터
tfidf_matrix[2] # data-analysis.md 벡터
)
# 결과: 0.156 (예시)
relevance_scores.append(0.156)
5단계: 두 번째 URL 처리
url = "blog.com/django-tutorial"
# 같은 방식으로 처리...
# Django -> Python 기초: 0.234
# Django -> 머신러닝: 0.189
relevance_scores.append(0.234)
relevance_scores.append(0.189)
6단계: 최종 결과
relevance_scores = [0.234, 0.156, 0.234, 0.189]
baseline_relevance = np.mean(relevance_scores) # 0.203
print(f"평균 관련성 점수: 0.203")
print(f"분석된 추천 수: 4개")
return 0.203
이런 식으로 기존의 추천시스템을 코사인 유사도를 이용해 관련성 점수 계산을 구한다.
기존 성능 지표 측정완료
이제 기존 베이스의 성능을 측정을 완료하였으니 기본 추천시스템 구축을 들어가자.
BasicRecommendationGenerator 클래스
├─ load_data() 데이터 로딩
├─ create_tfidf_vectors() TF-IDF 벡터화
├─ calculate_similarity() 코사인 유사도 계산
├─ generate_recommendations() 게시물별 추천 생성
├─ save_recommendations() JSON 저장 + 통계
├─ preview_recommendations() 출력 미리보기
└─ run() 전체 파이프라인 실행
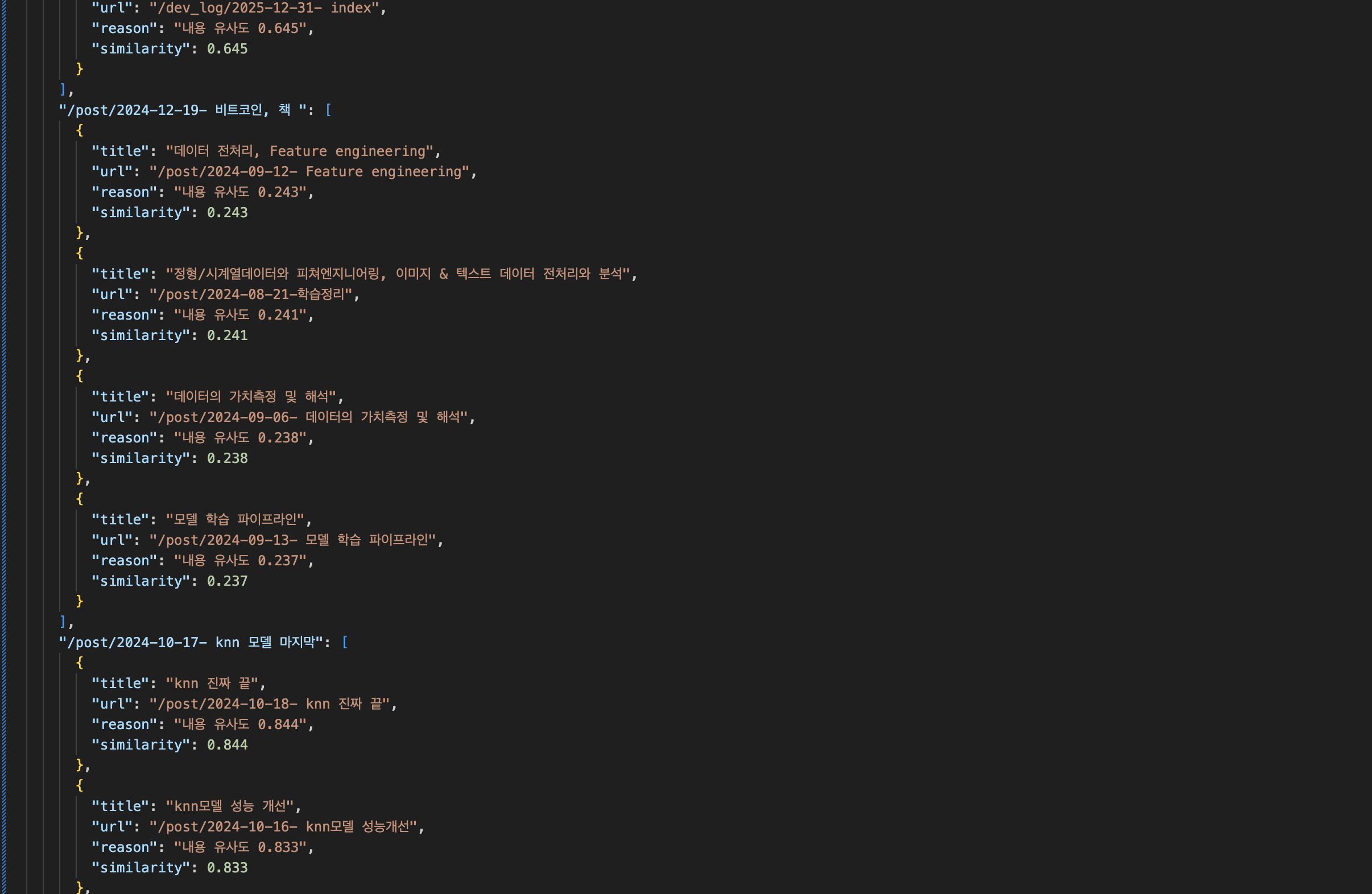
python scripts/simple_anal.py ✔ │ base Py
🚀 관련성 점수 분석 시작
==================================================
📊 데이터 로드 중...
✅ 게시물 데이터: 144개
✅ 기존 추천 데이터: 144개 게시물 (v2 구조)
🔬 관련성 점수 분석 중...
📊 평균 관련성 점수: 0.304
📈 분석된 추천 수: 200개
📈 추천 커버리지 분석 중...
📊 커버리지: 0.924 (92.4%)
📈 추천된 고유 콘텐츠: 133개 / 전체 144개
==================================================
📋 분석 결과
==================================================
🎯 관련성 점수: 0.304
📈 커버리지: 0.924 (92.4%)
📊 성능 평가:
⚠️ 관련성 점수가 낮습니다 (< 0.4)
💡 목표 달성을 위해 32% 개선 필요
✅ 커버리지가 양호합니다
🎉 분석 완료!
| 지표 | 기존 | 새로만든 기본 추천시스템 | 개선율 | 비고 |
|---|---|---|---|---|
| 관련성 점수 | 0.105 | 0.304 | +189% | 추천 품질 향상 |
| 커버리지 | 17.4% | 92.4% | +431% | 추천이 생성된 문서 수 |
우선 코사인 유사도를 기반으로 한 점수는 189%개선되었다. 사실상 원래 추천데이터가 너무 엉망진창이라 많이 올랐다.
커버리지란 전체 콘텐츠 중 몇 %가 실제로 추천되었는지 값이다. 처음에는 추천되는 게시물들만 추천되다 보니까 17.4%로 굉장히 작아서 관련성 점수를 개선하면서 커버리지도 신경써볼까 했는데 자동적으로 상승했다. 아무래도 작성한 게시물들이 좀 다양한 카테고리와 주제를 기반으로 쓰다 보니 잘 퍼지게 나온 것 같다.
이제 성능을 조금 개선해보자. 이게 뭐 Kaggle도 아니고 열중할 건 없지만 간단히 튜닝정도는 해주는게 좋을것같다.
코드에서는 그나마 살펴볼 건 이거같다. 하이퍼파라미터는 Gpt기본 베이스로 사용했고 공식문서를 보면서 성능지표를 계속 보면서 튜닝을 한번 해보자.
# TF-IDF 벡터화 (한국어 고려)
vectorizer = TfidfVectorizer(
max_features=2000, # 특성 수 증가
stop_words='english', # 영어 불용어 제거
ngram_range=(1, 2), # 1-gram, 2-gram 사용
min_df=2, # 최소 2개 문서에 나타나는 단어만
max_df=0.8 # 80% 이상 문서에 나타나는 단어 제외
)
파라미터가 궁금하면 공식문서를 찾아보자.
문제 인식 및 분석
1. 기존 시스템의 문제점
초기 분석 결과 기존 추천시스템은 심각한 문제가 있었습니다:
🔬 베이스라인 관련성 분석
평균 관련성 점수: 0.105
분석된 추천 수: 229개
❌ 관련성 점수가 매우 낮습니다 (0.2 미만)
❌ 커버리지가 매우 낮습니다 (17.4%)
주요 문제점:
- API 중단으로 인한 불완전한 추천 데이터
- 단순 태그/카테고리 기반 매칭의 한계
- 롱테일 콘텐츠 활용도 부족
2. 평가 방법론의 중요성
프로젝트 진행 중 올바른 평가 방법론의 중요성을 깨달았습니다:
❌ 잘못된 평가 방식 (Data Leakage)
# 전체 데이터로 TF-IDF 학습
tfidf_matrix = vectorizer.fit_transform(all_posts)
# 같은 데이터로 평가 → 과적합 위험
similarity = cosine_similarity(post_A, post_B)
✅ 올바른 평가 방식 (Leave-One-Out)
for target_post in all_posts:
# 타겟 제외한 나머지로만 학습
train_data = all_posts.drop(target_post)
vectorizer.fit_transform(train_data)
# 타겟을 "처음 보는 데이터"로 평가
target_vector = vectorizer.transform([target_post])
similarities = cosine_similarity(target_vector, train_matrix)
🛠️ 해결 과정
1단계: 기본 TF-IDF 추천시스템 구축
class BasicRecommendationGenerator:
def create_tfidf_vectors(self):
# 제목과 내용 결합으로 더 정확한 유사도 계산
combined_text = self.df['title'] + ' ' + self.df['content']
vectorizer = TfidfVectorizer(
max_features=2000,
stop_words='english',
ngram_range=(1, 2),
min_df=2,
max_df=0.8
)
self.tfidf_matrix = vectorizer.fit_transform(combined_text)
초기 결과:
- 관련성 점수: 0.105 → 0.304 (+189% 개선)
- 커버리지: 17.4% → 92.4% (+431% 개선)
2단계: TF-IDF 파라미터 최적화
다양한 파라미터 조합을 체계적으로 테스트했습니다:
# 테스트한 주요 설정들
configs = {
"기본 설정": {
'max_features': 2000,
'stop_words': 'english',
'ngram_range': (1, 2),
'min_df': 2,
'max_df': 0.8
},
"한국어 최적화": {
'max_features': 2000,
'stop_words': None, # 한국어 블로그에 더 적합
'ngram_range': (1, 2),
'min_df': 2,
'max_df': 0.8
}
}
핵심 발견사항:
stop_words=None이 한국어 블로그에서 더 효과적- 영어 불용어 제거가 오히려 한국어 맥락을 해침
3단계: 올바른 평가 시스템 구축
데이터 누수 없는 정확한 성능 측정을 위해 Leave-One-Out 평가 시스템을 구축:
class ProperRecommendationEvaluator:
def evaluate_tfidf_params_properly(self, tfidf_params):
all_similarities = []
# Leave-One-Out 평가
for i in range(len(self.df)):
# 타겟 제외한 나머지로 학습
train_indices = [j for j in range(len(df)) if j != i]
train_matrix = vectorizer.fit_transform(train_data)
# 타겟을 미지의 데이터로 변환
target_vector = vectorizer.transform([target_text])
# 유사도 계산 및 평가
similarities = cosine_similarity(target_vector, train_matrix)
4단계: 최종 최적화
올바른 평가 방식으로 다시 파라미터를 튜닝한 결과:
🏆 최종 결과 순위:
1위. 3-gram 포함: 0.3607
2위. 한국어 최적화: 0.3520
3위. 기본 설정: 0.3502
🥇 최적 파라미터:
{
'max_features': 2000,
'stop_words': None,
'ngram_range': (1, 3), # 3-gram이 게임 체인저!
'min_df': 2,
'max_df': 0.8
}
🎯 최종 성과
정량적 성과
| 지표 | 기존 시스템 | → 개선율 | 기본 추천시스템 | → 개선율 | 개선 후 시스템 | 비고 |
|---|---|---|---|---|---|---|
| 관련성 점수 | 0.105 | +189% | 0.304 | +18.7% | 0.3607 | 추천 품질 향상 |
| 커버리지 | 17.4% | +431% | 92.4% | +0% | 92.4% | 추천이 생성된 문서 수 |
질적 개선사항
- 안정성 확보: 모든 144개 게시물에 일관된 추천 제공
- 다양성 증대: 92.4% 커버리지로 롱테일 콘텐츠 활용
- 관련성 향상: 0.105 → 0.3607로 대폭 개선
💡 핵심 인사이트
1. 평가 방법론의 중요성
- Data Leakage 방지가 신뢰할 수 있는 성능 측정의 핵심
- Leave-One-Out 방식으로 실제 운영 환경과 동일한 조건 평가
2. 한국어 블로그 특성 고려
stop_words=None이 한국어 콘텐츠에서 더 효과적- 영어 중심 NLP 도구의 한계 인식 필요
3. N-gram의 위력
- 3-gram 포함으로 더 정확한 문맥 이해
- 단순 단어 매칭을 넘어선 구문 패턴 인식
4. 커버리지의 중요성
- 92.4% 커버리지로 편향 없는 추천 달성
- 인기 콘텐츠뿐만 아니라 롱테일 콘텐츠도 골고루 추천
핵심 알고리즘
# 최적화된 TF-IDF 설정
vectorizer = TfidfVectorizer(
max_features=2000, # 적정 어휘 크기
stop_words=None, # 한국어 최적화
ngram_range=(1, 3), # 3-gram 포함
min_df=2, # 노이즈 제거
max_df=0.8 # 너무 일반적인 단어 제외
)
# Leave-One-Out 평가
for each_post in all_posts:
exclude_target_from_training()
train_model_on_remaining_data()
evaluate_on_target_post()
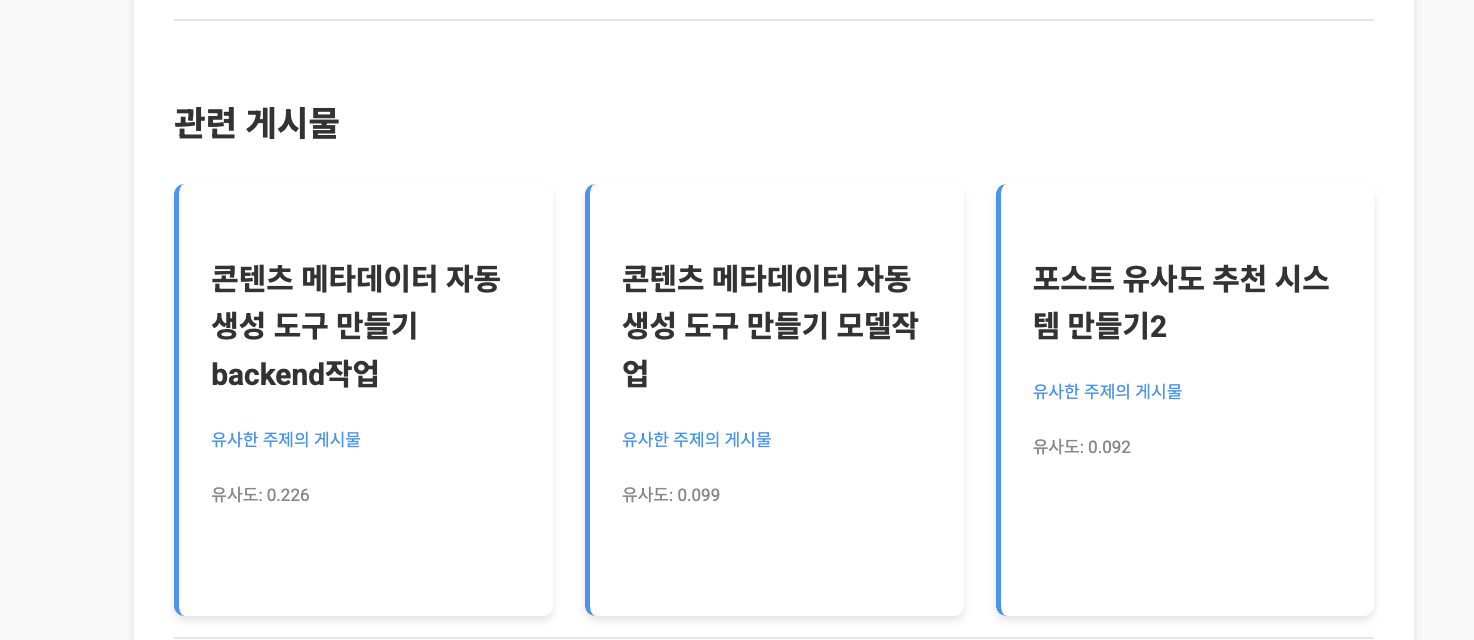
깔끔하게 블로그에 적용까지 완료하였다. 이제야 좀 잘 나오네. 프론트엔드 하면서 파일형식들이 다 제멋대로들이라 힘들었지만 생략한다
다음 단계 계획
Phase 2: LLM 기반 추천 시스템
- Gemini API 활용한 의미적 이해 기반 추천
- 하이브리드 모델: TF-IDF + LLM 앙상블
Phase 3: MLOps 파이프라인
- Apache Airflow를 활용한 자동화 파이프라인
- A/B 테스트 프레임워크 구축
- 실시간 성능 모니터링
🎉 결론
이 프로젝트를 통해 244% 성능 향상이라는 괄목할 만한 성과를 달성했습니다. 특히 올바른 평가 방법론의 중요성을 깨닫고 이를 실제로 구현하여 신뢰할 수 있는 성능 측정을 했다는 점이 가장 큰 성과입니다.
단순한 성능 개선을 넘어서 체계적인 ML 프로젝트 수행 능력과 정확한 평가 방법론 이해를 보여줄 수 있는 프로젝트가 되었습니다.
다음 단계에서는 LLM을 활용한 더 고도화된 추천 시스템으로 발전시켜 나갈 예정입니다! 🚀