모델 학습 파이프라인
모델 학습 파이프라인

Boosting Tree Model
부스팅은 예측력이 약한 모형(Weak Learner)을 결합하여 강한 예측 모형(Strong Learner)을 만드는 앙상블 기법입니다. 주요 알고리즘으로는 AdaBoost와 Gradient Boosting이 있습니다.
AdaBoost (Adaptive Boosting)
- 모든 데이터 샘플에 동일한 가중치를 부여하여 첫 번째 모델을 학습합니다.
- 잘못 예측된 샘플에 큰 가중치를 부여하여 새로운 데이터셋을 생성합니다.
- 이 과정을 반복하여 여러 개의 모델을 만듭니다.
- 최종 예측 시 각 모델의 예측값을 모두 사용하여 결과를 도출합니다.
Gradient Boosting
- 첫 번째 모델을 학습시킨 후, 그 모델의 잔여 오차(residual errors)를 계산합니다.
- 두 번째 모델은 첫 번째 모델의 오차를 줄이기 위해 학습합니다.
- 이 과정을 반복하여 최종 모델은 모든 모델의 예측을 더한 값으로 구성됩니다.
Light GBM
Light Gradient Boosting Machine
- 대용량 데이터에 대해 빠르고 메모리 효율적인 학습을 제공하는 알고리즘

모델 성능 평가
모델 평가의 목표
- 성능 측정: 정확성, 일관성, 신뢰도 평가
- 과소적합, 과대적합 예방
- 최적의 모델 선택
- 일반화 성능 평가
- 비즈니스 목표 달성 평가
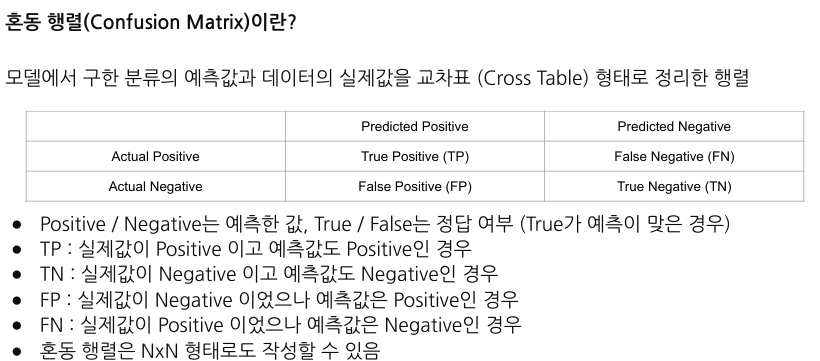
- 정확도(Accuracy): 전체 예측에서 올바르게 예측된 비율
- 정밀도(Precision): 각 클래스에 대해 올바르게 예측된 비율
- 재현율(Recall): 실제 값이 해당 클래스인 경우 중 올바르게 예측된 비율
- F1 스코어 (F1 Score): 정밀도와 재현율의 조화 평균
- 오탐율(False Positive Rate): 실제로는 Negative 클래스인데 모델이 Positive로 잘못 예측한 경우의 비율
모델 과적합 (Overfitting)
과적합은 모델이 훈련 데이터에 대해서는 매우 잘 작동하지만, 새로운 데이터에 대해서는 성능이 떨어지는 현상
-
훈련 손실은 계속 감소하지만 검증 손실이 증가하는 경우
-
훈련 데이터에 대한 성능과 검증 데이터에 대한 성능 차이가 큰 경우
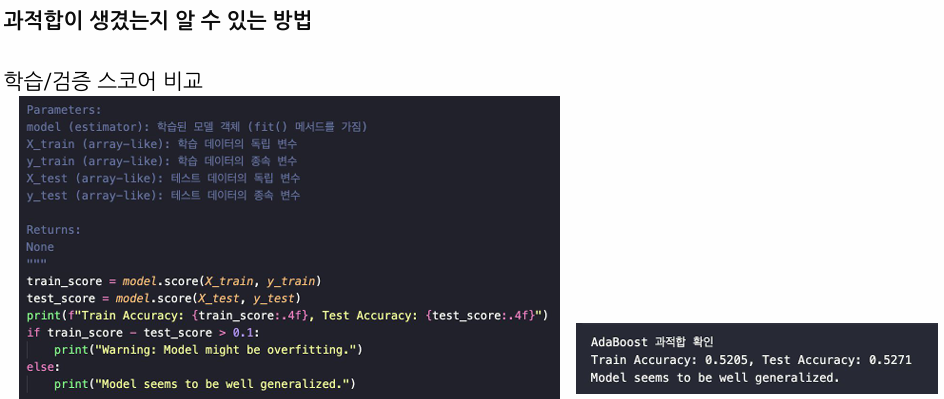
과적합을 방지하는 방법 • 교차 검증: 데이터를 여러 부분으로 나누어 모델을 반복 학습 및 평가하는 방법. • 정규화(Regularization): 모델의 복잡성을 제어하여 과적합을 방지하는 기법 (예: L1, L2 정규화). • 드롭아웃(Dropout): 딥러닝에서 일부 노드를 무작위로 비활성화하여 과적합을 방지하는 방법. • 조기 종료(Early Stopping): 검증 오류가 증가하기 시작할 때 학습을 멈추는 방법.
정규화 (Regularization)
정규화는 모델의 복잡성을 제어하여 과적합을 방지하는 기법
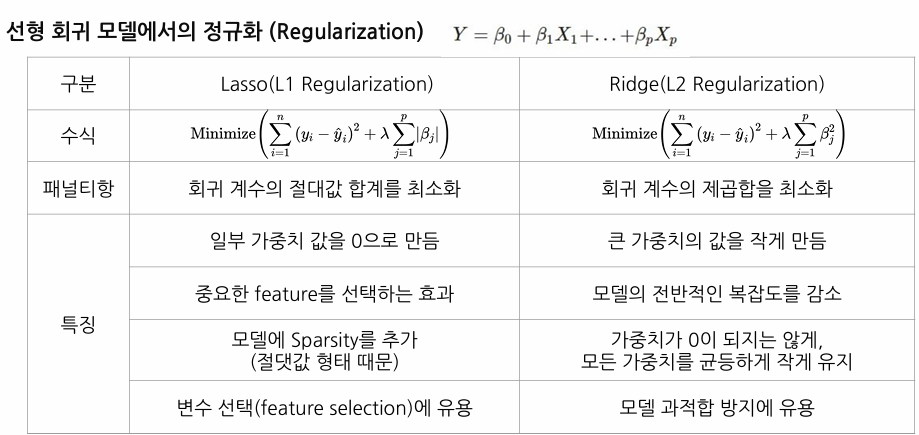
Lasso는 일부 가중치를 0으로 만들어 특성 선택 효과가 있고, Ridge는 모든 가중치를 작게 유지하여 전반적인 모델 복잡도를 감소시킵니다.


교차검증
교차검증은 데이터셋을 여러 부분으로 나누어 모델의 성능을 평가하는 방법입니다. 주요 목적은 다음과 같습니다:
- 모델 일반화 능력 평가 교차 검증을 통해 모델이 새로운 데이터에 대해 얼마나 잘 일반화되는지 평가할 수 있습니다. 단일 훈련/테스트 분할만 사용하는 경우 특정 데이터 분할에 과적합(overfitting)할 위험이 있습니다.
- 평가의 신뢰성 증가 데이터셋의 여러 부분을 테스트하여 모델 평가의 신뢰성을 높이고, 다양한 데이터 분할에서 모델의 성능을 확인할 수 있습니다.
- 데이터 효율적 사용 교차 검증은 데이터를 최대한 활용하여 모델을 평가할 수 있도록 합니다. 특히 데이터셋이 작을 때 유용합니다.
K-Fold 교차검증
K-Fold 교차검증은 데이터를 K개의 부분집합으로 나누고, 각 부분집합을 한 번씩 테스트 세트로 사용하는 방법
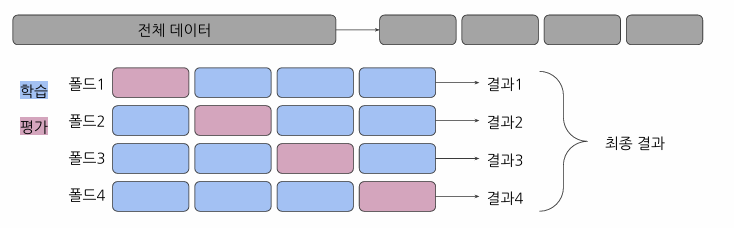
장점:
- 모든 데이터 포인트를 훈련과 테스트에 사용
- 데이터셋이 작을 때 유용
단점:
- 계산량이 많음
- 클래스 불균형 문제에 취약할 수 있음
Stratified K-Fold 교차검증
클래스분포를 균등하게 유지하면서 폴드를 나누는 방법
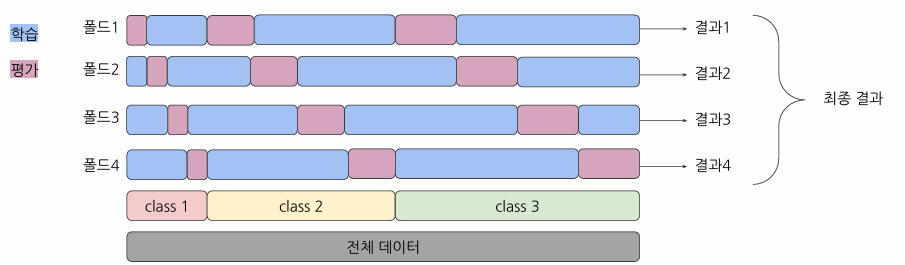
장점:
- 클래스 불균형 문제 해결
- 각 폴드가 전체 데이터셋의 분포를 잘 나타냄
단점:
- K-Fold보다 느릴 수 있음
- 매우 작은 데이터셋에서는 모든 클래스를 포함시키기 어려울 수 있음
Time Series Split 교차검증
시계열 데이터의 특성을 고려한 교차검증 방법으로, 과거 데이터로 미래 데이터를 예측하는 방식을 모방
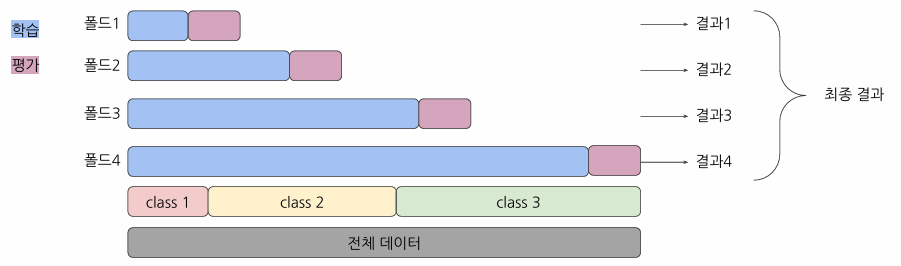
장점:
- 시계열 데이터의 시간 순서를 유지
- 실제 상황과 유사한 평가 가능
단점:
- 초기 분할에서는 훈련 데이터가 적어 성능이 낮을 수 있음
교차검증 적용 시 고려사항
-
시간 복잡성 증가 K번의 학습과 검증을 한 후에 결과를 내므로 K가 증가함에 따라 한번의 결과를 보는데까지의 시간 또한 증가함 따라서 컴퓨팅 자원과 시간에 따라 적절한 K값을 선택해야 함
-
데이터 전처리 데이터 전처리는 교차 검증의 각 반복에서 훈련 데이터와 테스트 데이터를 분할한 후에 각각 별도로 수행해야 함 ex) 스케일링, 인코딩 등의 작업은 각 폴드 내에서 개별적으로 수행 Scikit-learn의 Pipeline, cross_val_score을 사용하여 데이터 전처리와 모델 학습을 연결할 수 있음 이를 통해 전처리 과정이 각 교차 검증 반복에서 독립적으로 수행되게 함