Transformer
선요약
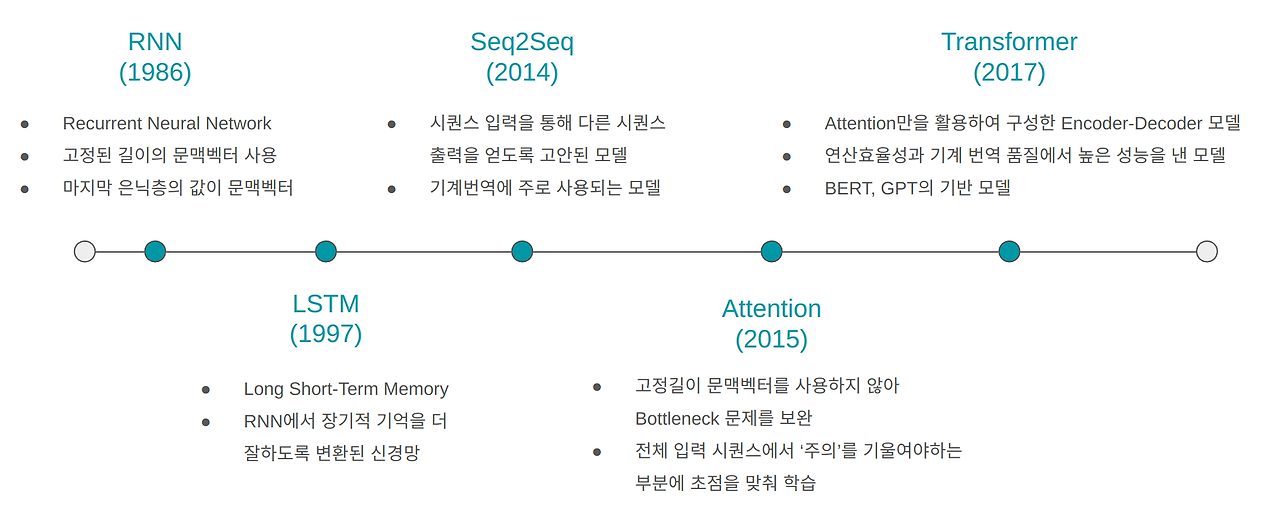
시퀀스 데이터 처리를 위한 딥러닝 모델의 발전 과정
RNN의 기본 개념과 한계점부터 시작하여, LSTM과 GRU를 통한 개선, Seq2Seq 모델의 도입, Attention 메커니즘의 혁신, 그리고 최종적으로 Transformer 모델의 등장
Transformer는 자연어 처리 분야에 큰 혁신을 가져왔으며, BERT와 같은 사전 학습 모델의 기반
Vision Transformer(ViT)를 통해 컴퓨터 비전 분야로도 확장
딥러닝 모델의 발전 과정
모델 비교 표
| 모델 | 장점 | 단점 |
|---|---|---|
| RNN | - 가변 길이 시퀀스 처리 - 파라미터 공유 |
- 장거리 의존성 처리 어려움 - 기울기 소실 문제 |
| LSTM/GRU | - 장거리 의존성 처리 개선 - 기울기 소실 문제 완화 |
- 계산 복잡도 증가 - 학습 시간 증가 |
| Seq2Seq | - 입출력 길이 불일치 해결 - 다양한 태스크 적용 가능 |
- 긴 시퀀스에서 성능 저하 - 병목 현상 |
| Transformer | - 병렬 처리 가능 - 장거리 의존성 처리 우수 - 확장성 높음 |
- 대규모 데이터셋 필요 - 높은 계산 비용 |
| BERT | - 양방향 문맥 이해 우수 - 다양한 NLP 태스크에 적용 가능 |
- 큰 모델 크기 - Fine-tuning 필요 |
| ViT | - 이미지에 Transformer 적용 - CNN 대비 우수한 성능 (대규모 데이터) |
- 대규모 데이터셋 필요 - 작은 데이터셋에서 성능 저하 |
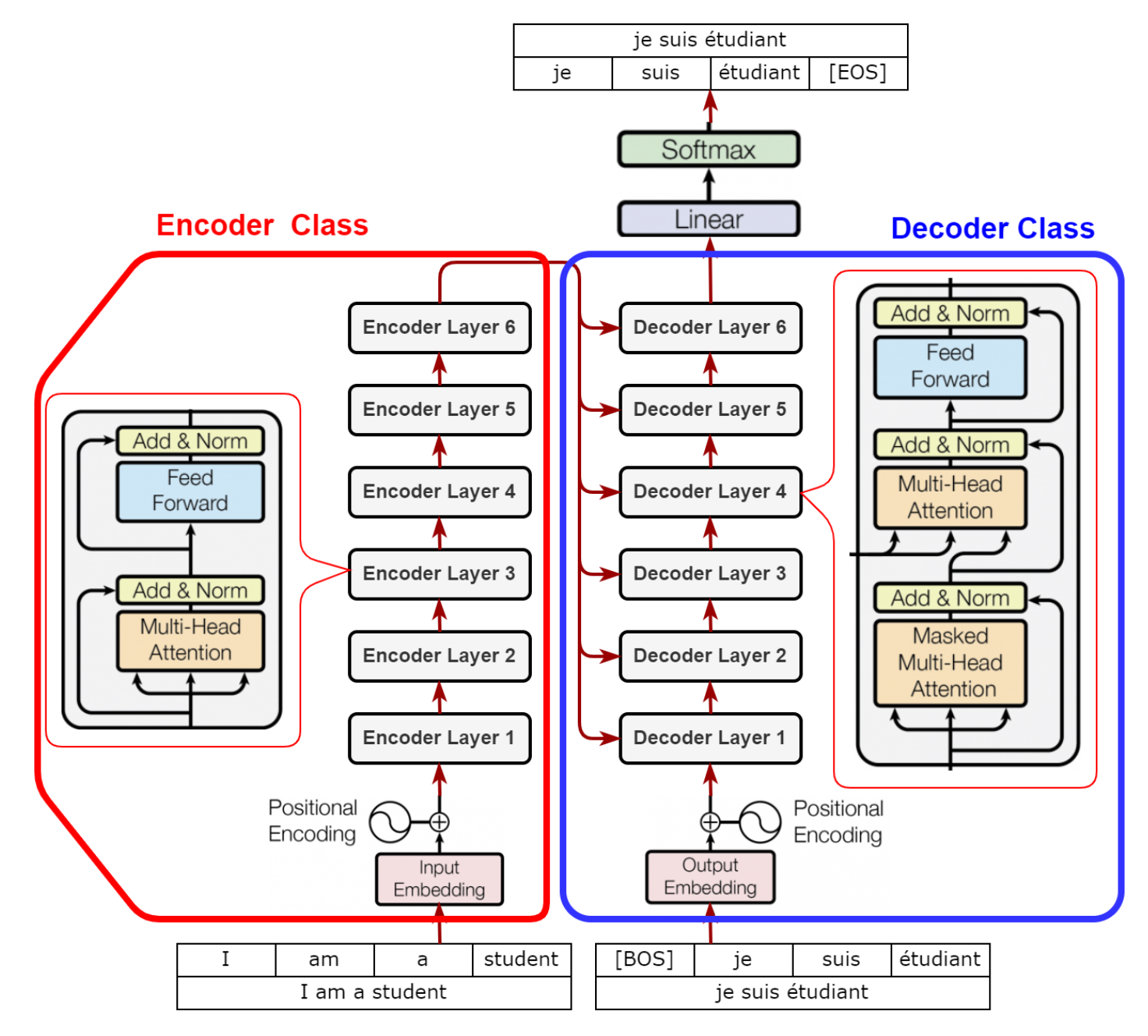
Transformer의 Encoder와 Decoder 구조
RNN이란
input과 output이 가변적인, 시퀀스된 데이터 처리
RNN의장점:
- 가변적인 길이의 Input Sequence 처리 가능
- 입력이 많아져도 모델의 크기는 증가하지 않음
- (이론적으로) t시점에서 수행된 계산은 여러 단계 이전의 정보를 사용 가능
- 모든 단계에서 동일한 가중치가 적용됨
RNN의단점:
- Recurrent computation이 느림
- Sequence output inference는 병렬화(parallelization)가 어려움
- 바닐라RNN은 훈련 중 기울기 소실(vanishinggradient)문제를 겪음
- 바닐라RNN은 종종 시퀀스내 장거리의존성(long-rangedependence)을 모델링하는데 실패
- 실제로는 여러단계 이전의 정보에 접근하기 어려움
RNN은 완벽하지 않습니다
• Issue1) RNN은 기울기소실/폭발 문제가 있으며,따라서 long-rangedependence을 모델링하기 어려움 → LSTM/GRU
• Issue2) Many-to-many RNN은 입력/출력 시퀀스의 길이가 다를때 유연하게 대응하기 어려움 → Seq2seqmodel
• Issue3) LSTM/GRU 마저도 매우 긴 시퀀스를 처리할때 문제가 발생 → Attentionmodel
LSTM(Long Short-Term Memory)
LSTM은 RNN의 한계를 극복하기 위해 고안된 모델
셀 상태(cell state)와 여러 게이트(forget gate, input gate, output gate)를 도입하여 장기 의존성 문제를 해결
LSTM은 기울기 소실/폭발 문제를 완전히 해결하지는 않지만, 장거리 의존성을 학습하기 더 쉽게 만듦
GRU(Gated Recurrent Unit)
LSTM과 유사하지만 더 단순한 구조를 가진 모델
LSTM보다 적은 파라미터를 사용하면서도 비슷한 성능을 낼 수 있음
Sequence-to-Sequence(seq2seq) 모델
기계 번역과 같은 작업을 위해 설계된 모델 구조
인코더: 입력 시퀀스를 고정 길이 벡터로 인코딩
디코더: 인코딩된 벡터를 기반으로 출력 시퀀스 생성
Teacher Forcing: 학습 시 디코더의 입력으로 이전 시점의 실제 정답을 사용하는 기법
Attention idea
RNN 기반 모델의 한계점: 긴 시퀀스에서 정보 손실이 발생하며, 초기 입력 정보가 잊혀지는 경향이 존재
Attention의 기본 아이디어: 디코더가 모든 input step의 hidden state를 고려하며, 관련성 높은 input token에 더 집중
Attention 함수: Query(Q), Key(K), Value(V)를 입력으로 받아 Attention 값을 출력
- Q(Query): decoder의 time t에 대한 hidden state
- K(Keys): encoder의 hidden states (at all times)
- V(Values): encoder의 hidden states (at all times)
Dot-Product Attention: 가장 기본적인 형태의 Attention으로, Query와 Key의 내적을 통해 유사도를 계산
Attention을 활용한 기계 번역
인코딩 과정: 입력 문장의 각 단어에 대한 hidden state를 생성
디코딩 과정: 각 단계에서 Attention을 사용하여 관련성 높은 입력 단어에 집중
Attention Map: 입력 단어와 출력 단어 간의 관계를 시각화
Transformer
기본 가정: 입력은 서로 유기적으로 관련된 여러 요소로 분할될 수 있음
Self-Attention: 각 요소가 자신의 표현을 개선하기 위해 다른 요소들과의 관계를 학습
Transformer Main Idea
입력 토큰을 Query, Key, Value 벡터로 변환
Self-Attention을 수행하여 각 토큰의 표현을 컨텍스트화
이 과정을 여러 번 반복하여 더 깊은 컨텍스트화를 달성
Transformer의 구조
Multi-Head Attention: 여러 개의 Attention을 병렬로 수행 Feed-Forward Neural Network: Attention 결과를 추가로 처리 Layer Normalization과 Residual Connection: 학습 안정성을 높임
Transformer의 상세 구조
Input Embeddings: 토큰 시퀀스를 벡터로 변환
Positional Encoding: 순서 정보를 모델에 제공
Multi-head Self-attention: 여러 관점에서 토큰 간 관계를 학습
Feed-forward Layer: 각 토큰에 대해 추가적인 처리 수행
Layer Normalization과 Residual Connection: 학습 안정성 향상
BERT (Bidirectional Encoder Representations from Transformers)
Transformer의 Encoder만을 사용한 대규모 언어 모델
Masked Language Modeling (MLM)과 Next Sentence Prediction (NSP) 태스크로 사전 학습
다양한 NLP 작업에 fine-tuning하여 사용 가능
Vision Transformer (ViT)
Transformer를 이미지 분류에 적용한 모델
이미지를 패치로 분할하여 시퀀스로 처리
대규모 데이터셋에서 CNN을 능가하는 성능 달성
위치 임베딩을 통해 공간 정보 학습