포스트 유사도 추천 시스템 만들기2
포스트 유사도 추천 시스템 만들기2
우선 GPT에게 한번 큰 틀을 그리게 해보았다.
관련 게시물 추천:빌드 과정에서 AI 서비스를 사용하여 게시물 간 유사성을 분석하고, 각 게시물에 관련 게시물 목록을 생성합니다. 이를 HTML에 하드코딩하여 로드 속도를 높일 수 있습니다.
구현 방법: 빌드 스크립트를 작성하여 AI API를 호출하고, 각 게시물의 콘텐츠를 기반으로 유사한 게시물을 찾습니다. 결과를 JSON 파일로 저장하고, Jekyll 템플릿에 포함하여 정적 사이트에 통합합니다
Ruby 스크립트(related_posts_generator.rb)는 Jekyll 블로그의 게시물들을 분석하여 각 게시물마다 관련 게시물을 찾아 JSON 파일로 저장하는 프로그램입니다. 전체 흐름을 자세히 살펴보겠습니다.
전체 프로세스 요약
- 모든 블로그 게시물 파일(
.md)을 읽고 정보 추출 - 각 게시물마다 다른 모든 게시물과의 관련성 분석
- Claude AI API를 사용해 관련 게시물 추천 받기
- 결과를 JSON 파일로 저장
- Jekyll이 빌드 시 이 JSON 데이터를 사용해 관련 게시물 섹션 렌더링
초기화 및 환경설정
class RelatedPostsGenerator
API_KEY = ENV['AI_API_KEY'] # 환경 변수에서 API 키 가져오기
API_ENDPOINT = "https://api.anthropic.com/v1/messages" # Claude API 엔드포인트
def initialize(posts_dir = "_posts", output_dir = "_data")
@posts_dir = posts_dir
@output_dir = output_dir
@all_posts = []
@related_posts = {}
# 출력 디렉토리가 없으면 생성
FileUtils.mkdir_p(@output_dir) unless Dir.exist?(@output_dir)
end
환경 변수에서 Claude API 키를 가져옵니다
게시물 디렉토리(_posts)와 출력 디렉토리(_data)를 설정합니다
빈 배열(@all_posts)과 해시(@related_posts)를 초기화합니다
원래 DeepSeek api를 써보려다가 사이트가 터져서 Claude api 발급받았던거 있길래 그걸로 써봤다. DeepSeek써볼려고 했는데 얜 왜 맨날 사이트가 터져있냐.
모든 게시물 읽기
def read_all_posts
puts "모든 게시물 읽는 중..."
Dir.glob(File.join(@posts_dir, "**/*.md")).each do |file|
content = File.read(file)
# YAML Front Matter 파싱
if content =~ /\A---\s*\n(.*?)\n---\s*\n/m
front_matter = YAML.safe_load($1, permitted_classes: [Date, Time])
# 게시물 메타데이터와 내용 추출
title = front_matter["title"] || "Untitled"
categories = front_matter["categories"] || []
tags = front_matter["tags"] || []
# 실제 콘텐츠 (YAML Front Matter 이후)
body = content.sub(/\A---\s*\n.*?\n---\s*\n/m, '')
summary = body.strip.split(/\n+/).first(3).join(" ").gsub(/\s+/, ' ').strip
# 파일 이름에서 날짜와 슬러그 추출
filename = File.basename(file, ".*")
date = filename[0..9] if filename =~ /^\d{4}-\d{2}-\d{2}/
slug = filename[11..-1] if date
# 게시물 URL 생성
url = date ? "/#{date.gsub('-', '/')}/#{slug}" : "/#{filename}"
@all_posts << {
title: title,
url: url,
categories: categories,
tags: tags,
summary: summary,
content: body[0..5000], # 처리를 위해 내용 제한
file: file
}
end
end
puts "총 #{@all_posts.size}개의 게시물을 찾았습니다."
end
_posts 디렉토리 내의 모든 마크다운(.md) 파일을 찾습니다
각 파일마다:
- 파일 내용을 읽습니다
- 정규표현식을 사용해 YAML Front Matter를 추출하고 파싱합니다
- 제목, 카테고리, 태그 등의 메타데이터를 추출합니다
- 본문 내용을 추출하고 앞부분을 요약합니다
- 파일 이름에서 날짜와 슬러그를 추출해 URL을 구성합니다
- 추출한 모든 정보를 해시로 만들어
@all_posts배열에 추가합니다
.json 으로 만들기 용이하도록 해시로 만들어서 넣어줌. 근데 이거 다 읽고 다 넣는거 너무 cost 많이 들거같은데 임베딩도 안하고 바로 넣어버리네.
관련 게시물 찾기
def find_related_posts
puts "게시물 간 관련성 분석 중..."
total = @all_posts.size
@all_posts.each_with_index do |post, index|
puts "[#{index + 1}/#{total}] '#{post[:title]}' 관련 게시물 찾는 중..."
# AI에 보낼 프롬프트 생성
prompt = create_prompt(post)
# API 호출하여 관련 게시물 찾기
related = call_ai_api(prompt, post)
# 결과 저장
@related_posts[post[:url]] = related
# API 요청 간 간격 두기
sleep(1) unless index == total - 1
end
end
AI 프롬프트 생성
def create_prompt(current_post)
# 다른 모든 게시물의 제목과 요약 정보 수집
other_posts = @all_posts.reject { |p| p[:url] == current_post[:url] }.map do |p|
"제목: #{p[:title]}\nURL: #{p[:url]}\n요약: #{p[:summary]}\n카테고리: #{p[:categories].join(', ')}\n태그: #{p[:tags].join(', ')}"
end
# 프롬프트 생성
<<~PROMPT
현재 게시물:
제목: #{current_post[:title]}
요약: #{current_post[:summary]}
카테고리: #{current_post[:categories].join(', ')}
태그: #{current_post[:tags].join(', ')}
다음은 블로그의 다른 게시물 목록입니다:
#{other_posts.join("\n\n")}
위 게시물 목록에서 현재 게시물과 가장 관련성이 높은 게시물 3-5개를 찾아주세요.
콘텐츠, 카테고리, 태그의 유사성을 기반으로 판단해주세요. 결과는 다음 JSON 형식으로 반환해주세요:
[
{"url": "/게시물URL", "title": "게시물 제목", "reason": "관련성에 대한 간단한 설명"},
...
]
JSON 형식만 반환하고 다른 설명은 포함하지 마세요.
PROMPT
end
현재 게시물을 제외한 모든 게시물의 정보(제목, URL, 요약, 카테고리, 태그)를 문자열로 포맷팅합니다
현재 게시물과 다른 모든 게시물 정보를 포함한 프롬프트를 생성합니다
Claude AI에게 현재 게시물과 관련성이 높은 게시물 3-5개를 찾고 JSON 형식으로 반환하도록 지시합니다
AI API 없을때 대체 계산
def mock_api_call(current_post)
puts "API 키 없음 - 태그와 카테고리 기반으로 관련 게시물 찾는 중..."
# 간단한 관련성 점수 계산
scored_posts = @all_posts.reject { |p| p[:url] == current_post[:url] }.map do |post|
# 태그 유사성
common_tags = (current_post[:tags] & post[:tags]).size
tag_score = current_post[:tags].empty? ? 0 : common_tags.to_f / current_post[:tags].size
# 카테고리 유사성
common_cats = (current_post[:categories] & post[:categories]).size
cat_score = current_post[:categories].empty? ? 0 : common_cats.to_f / current_post[:categories].size
# 종합 점수
score = (tag_score * 0.6) + (cat_score * 0.4)
{
post: post,
score: score
}
end
# 점수에 따라 정렬하고 상위 5개 추출
top_related = scored_posts.sort_by { |item| -item[:score] }.first(5)
# 결과 변환
top_related.map do |item|
{
"url" => item[:post][:url],
"title" => item[:post][:title],
"reason" => "태그와 카테고리 유사성"
}
end
end
현재 게시물을 제외한 모든 게시물에 대해 관련성 점수를 계산합니다
- 태그 유사성: 공통 태그 수 / 현재 게시물 태그 수 (가중치 0.6)
- 카테고리 유사성: 공통 카테고리 수 / 현재 게시물 카테고리 수 (가중치 0.4)
- 종합 점수 계산
점수가 높은 순서로 정렬하고 상위 5개를 선택합니다
선택된 게시물의 URL, 제목과 함께 “태그와 카테고리 유사성”이라는 설명을 포함하여 결과를 반환합니다
결과 저장
def save_results
puts "관련 게시물 데이터 저장 중..."
output_file = File.join(@output_dir, "related_posts.json")
File.write(output_file, JSON.pretty_generate(@related_posts))
puts "저장 완료: #{output_file}"
end
@related_posts 해시(게시물 URL을 키로, 관련 게시물 배열을 값으로 가짐)를 예쁘게 포맷팅된 JSON으로 변환합니다
결과를 _data/related_posts.json 파일에 저장
뭐 나름 생각보다 잘 매칭되는 거 같긴 한데.
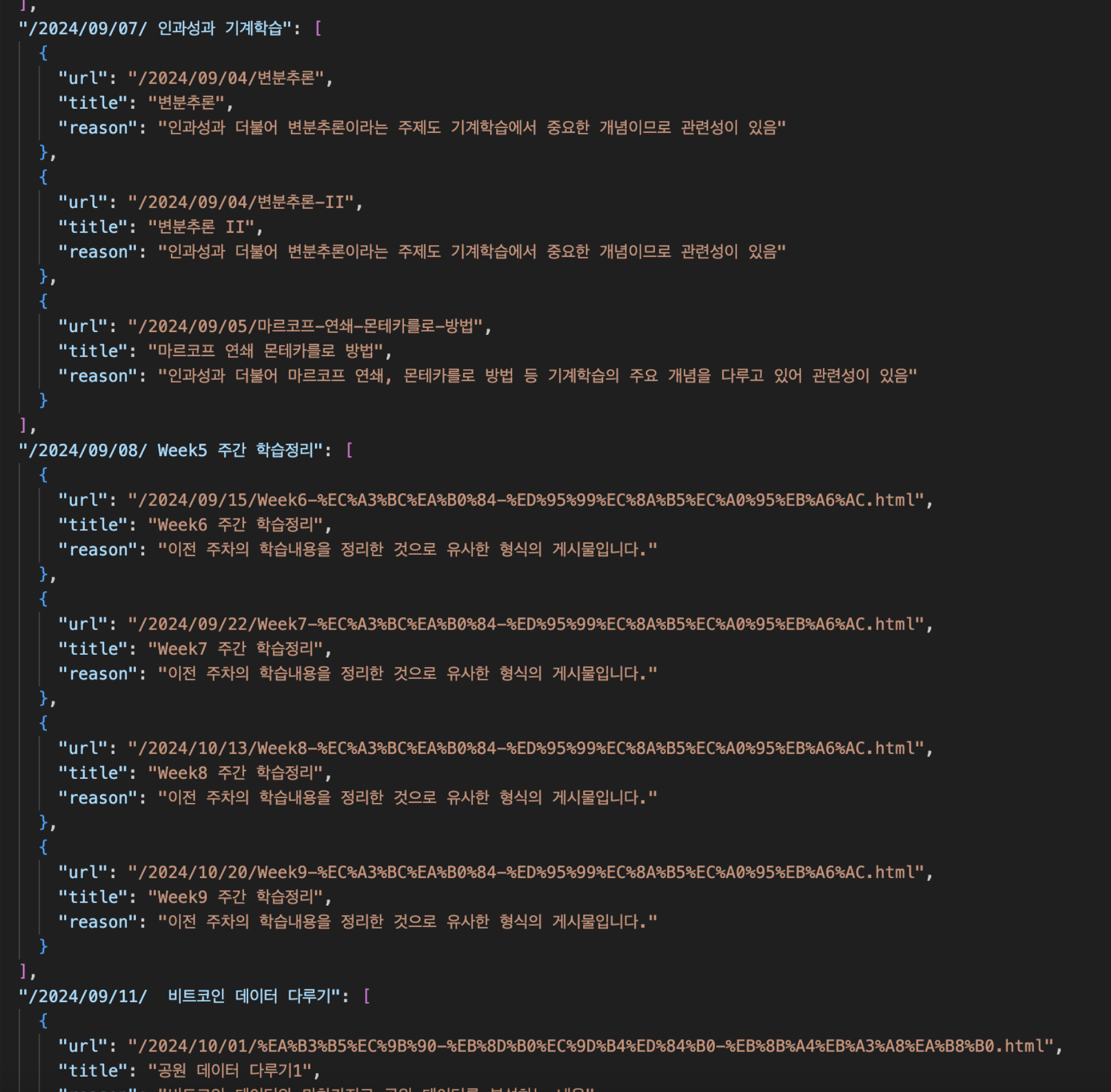
이렇게 해서 나온 .json을 사용해

웹사이트에 띄우는 거 까지 하긴 했다. 확실히 요즘 gpt 일 잘한다니까.
근데 사실 이렇게만 보면 잘 된거같지만 문제가 생각보다 많았다.
-
우선, 굳이 Ruby 스크립트로 JSON을 생성할 필요가 있었을까?
.rb파일로 작업하니까 코드 분석이 너무 까다로웠다. 결국, Python으로 JSON을 생성하는 프로그램을 다시 작성하기로 했다. -
또한, API 요청을 여러 번 반복하다 보니 Claude API가 끊겨서 대체 계산 방식으로 이어지는 문제가 발생했다. 대기 시간을 1초로 설정했음에도 불구하고 요청 속도가 너무 빨랐던 듯하다.
-
게다가 Claude API 비용이 너무 비싸다. 가장 선호하는 LLM이긴 하지만, 겨우 10번 정도 호출했는데 2달러나 나왔다. 앞으로는 Claude 대신 다른 모델을 사용하거나, 아예 API 호출을 최소화하는 방향을 고려해야 할 것 같다.
-
매칭 로직도 너무 대충 이루어지고 있다. JSON 파일에 최종 결과는 저장되지만, 각 내용이 어떻게 매칭되었는지 기록이 없어서 논리적으로 빈약하다.
-
게다가, 모든 내용을 한꺼번에 배열에 넣어 처리하는 방식이 이해가 안 된다. 아마도 순간적으로 많은 비용이 발생한 것도, 모든 데이터를 한꺼번에 불러와 비교하는 과정에서 API 호출이 과도하게 이루어졌기 때문일 것이다. 임베딩하여 저장하고 RAG 방식을 활용하면 비용을 훨씬 줄일 수 있을 것으로 보인다.
-
그리고 정말 AI API를 사용할 필요가 있을까? 단순 문자열 처리를 알고리즘화해서 추천 시스템을 구현하는 게 더 효율적일 수도 있다. 불필요하게 복잡한 방법을 선택한 것은 아닌지 다시 고민해볼 필요가 있다.