NLP 마스터클래스
나도 다른 강의들은 슥슥 흝어봄
6강 제외한 대충 연관되있는 기억나는 내용
COMMON CRAWL 웹 크롤링을 통해 데이터를 오픈소스로 공개하는 사이트 크롤링하지말라고 걸어둔 robot.txt를 지키기 때문에 네이버나 구글, 블로그 같은 한글 데이터들은 많이 부족하고 다른 데이터들도 질이 낮다.
LLM을 이용한 평가의 단점
-
비용이 많이 듭니다
-
같은 모델이 만든 결과물을 평가할 때 편향되게 좋은 점수를 줍니다
-
같은 내용을 평가하더라도 매번 다른 결과가 나올 수 있습니다 (재현성 부족)
-
A와 B를 비교할 때 먼저 제시된 A에 대해 더 좋은 평가를 하는 경향이 있습니다
-
그래서 LLM을 한번 거치고 인간의 평가를 하는 것도 새로 나옴.
다른 강의는 연관크게없는거 같은데 6강 Evaluation for LLM만 봐도 댈듯
[24.11.29] Level2 마스터클래스
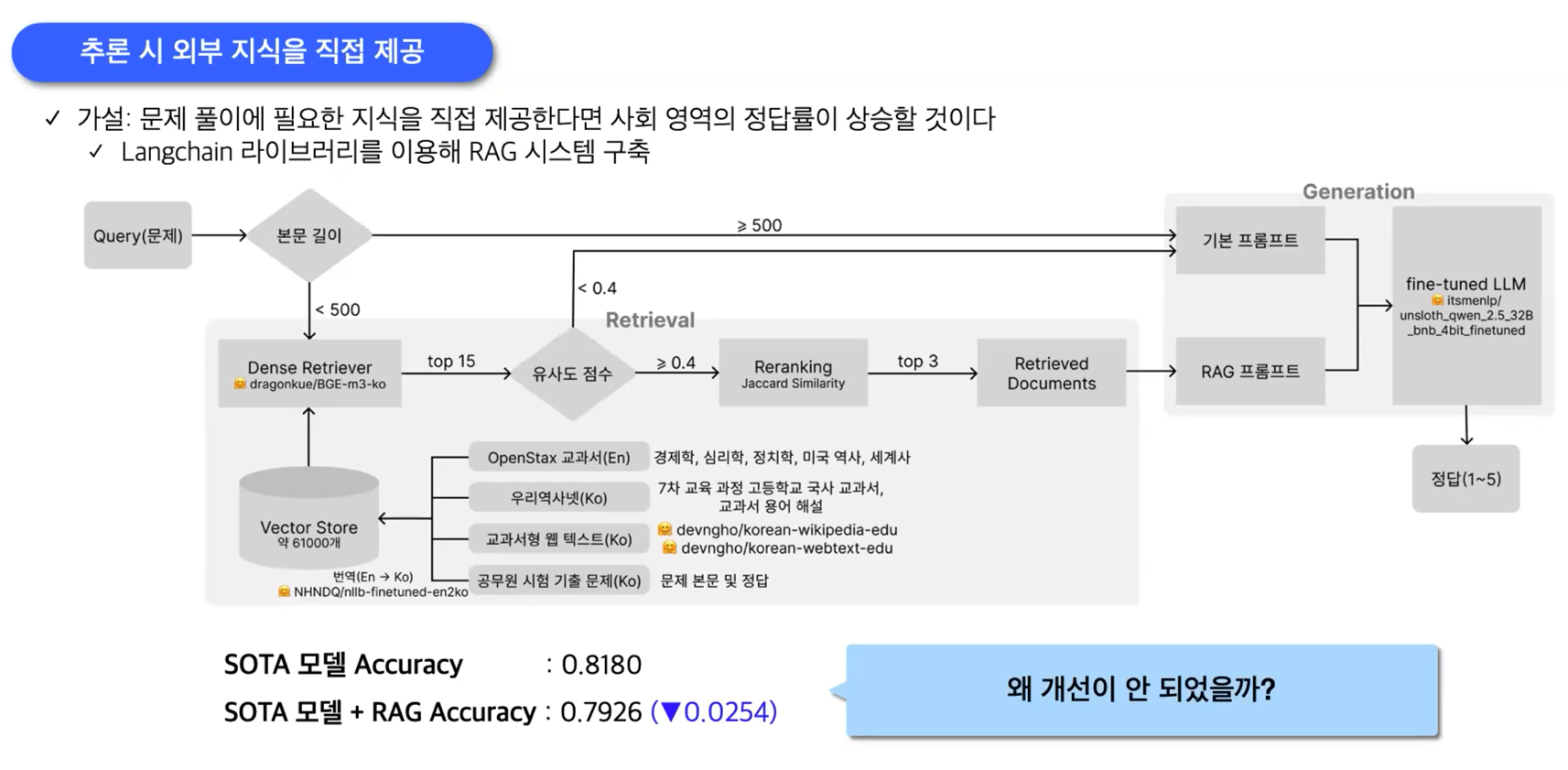
얘네는 수능문제를 맞히는 거라 우리랑 좀 다르긴 함.
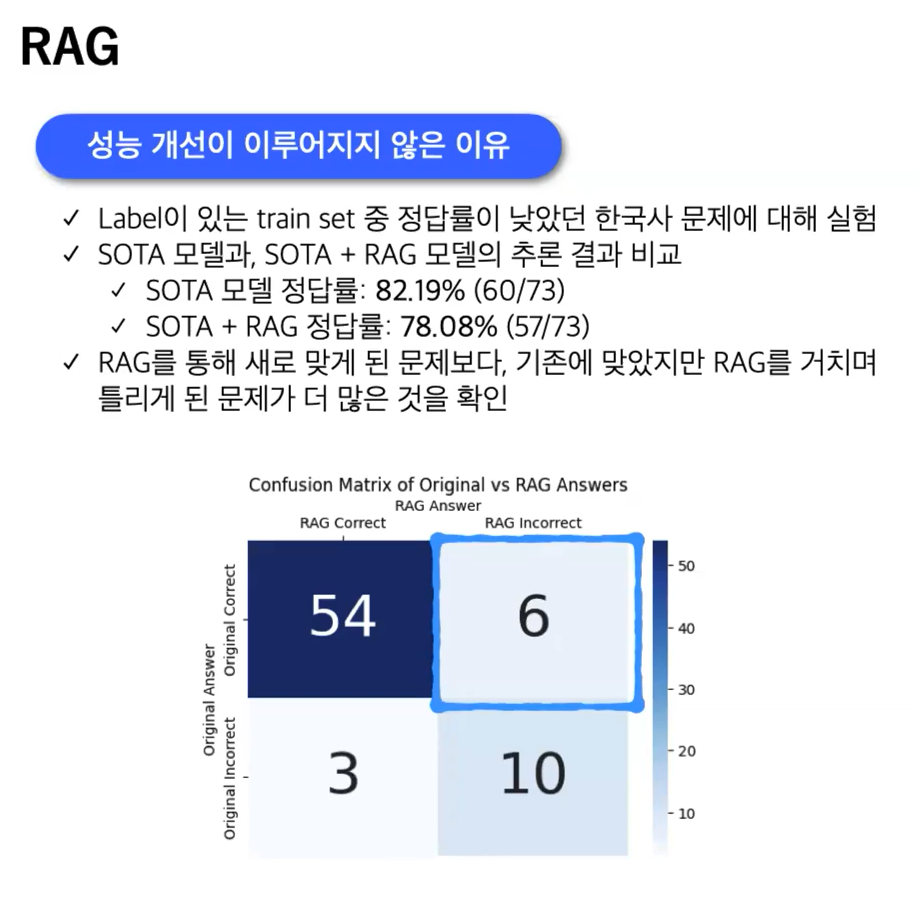
1등조는 최종적인 모델에서 RAG는 제외했다고 함.
2조는 RAG에 성능향상이 되어 RAG 사용함.
train에 안쓰고 inference만 사용 1~2문제만 향상.
train & inference 둘다 사용하니까 성능많이향상.
마스터: RAG하기에 시퀀스가 부족하지 않앗냐? (GPU 메모리나 계산 능력의 한계 에 대한 질문)
Elastic search를 사용. (그게 머지)
Elastic Search는 대량의 데이터를 저장하고 실시간으로 검색할 수 있게 해주는 검색 엔진입니다
텍스트 검색에 특화되어 있어 RAG 시스템 구축에 자주 사용됩니다

마스터: 여기서 단어기반 필터링을 어케함?
논리적으로 룰기반으로 필터링함.
이외 사전질문도 한번 들어볼만한듯.