비트,책
비트코인
Introduction
- 우리 팀은 암호화폐 시장에서의 비트코인 가격 변동성 예측이라는 도전적인 과제에 직면했습니다
- 일반 주식시장보다 변동성이 큰 암호화폐 시장에서, 정확한 예측을 위해 온체인 데이터와 시장 데이터를 복합적으로 활용하는 접근법이 필요했습니다
- 4개의 클래스(크게 하락/소폭 하락/소폭 상승/크게 상승)를 예측하는 다중 분류 문제로 정의했습니다
Method
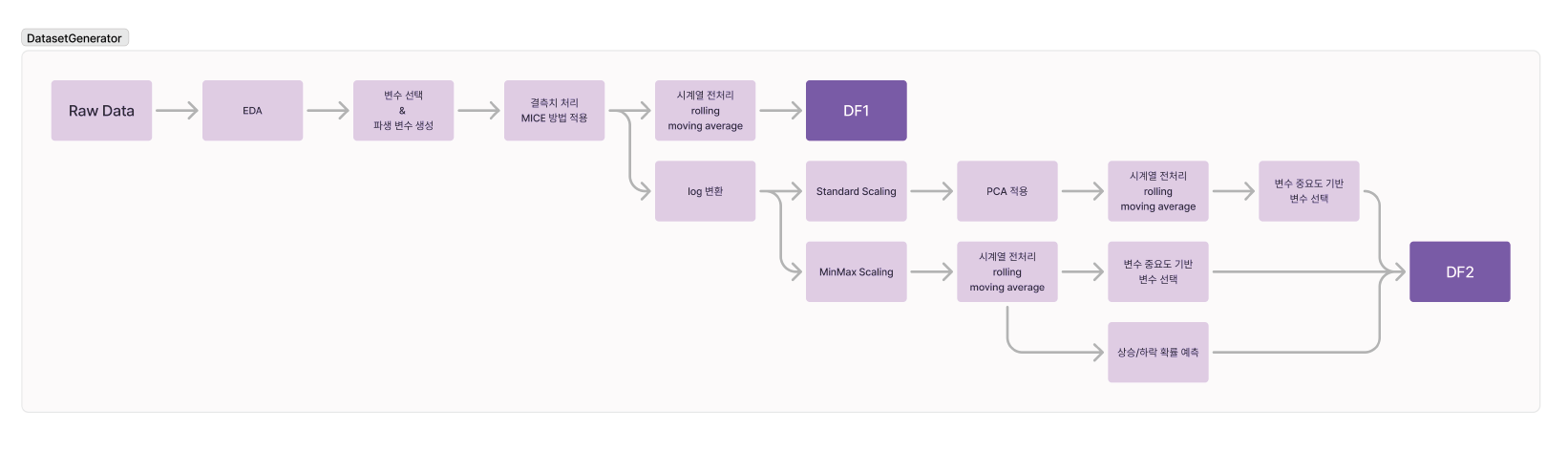
- 체계적인 데이터 분석 및 전처리
- EDA를 통한 107개 데이터 셋의 특성 파악
- 결측치에 대한 MICE 방법론 적용
- MinMax Scaling을 통한 데이터 정규화
- PCA를 통한 차원 축소로 200개 이상의 주요 변수 추출
- 협업 프로세스 구축
- GitHub을 통한 체계적인 코드 버전 관리
- Notion을 활용한 실험 결과 및 문서화 관리
- 정기적인 화상 회의를 통한 아이디어 공유
- 모델링 접근 방식
- Tree 기반 모델들(LightGBM, XGBoost, CatBoost)의 앙상블
- 상승/하락 예측을 위한 이진 분류 모델 활용
- Cross-validation을 통한 모델 검증
- Bayesian Search를 통한 하이퍼파라미터 최적화
Experiment
- Public Score 3위(0.4233), Private Score 7위(0.4046) 달성
- 각 데이터셋에서 Cross-validation 정확도 약 45% 달성
- 0/3 클래스(큰 폭의 상승/하락)에 대한 예측력 향상을 위해 다양한 접근 시도
Further Study
- 개선 가능한 부분
- 데이터 증강을 통한 불균형 클래스 문제 해결
- GitHub를 통한 더욱 체계적인 실험 관리 필요
- Validation set 고정을 통한 일관된 성능 평가
- 향후 연구 방향
- Prophet 등 새로운 시계열 모델 적용 검토
- 데이터 가치 평가를 위한 Influence function 도입 고려
- 거래량 기반의 Feature embedding 연구
우리 팀의 문제해결 경험
- 데이터 복잡성 극복
- 107개의 데이터가 합쳐진 형태로, 가상 화폐 거래소 데이터와 블록체인 정보가 시간별로 제공된 복잡한 시계열 데이터를 체계적으로 분석했습니다
- 수많은 가상 화폐 거래소 변수 중 모든 exchange를 대푯값을 사용하고 일부 거래소와 화폐종류는 대푯값과 다른 양상을 보일 수 있으므로 따로 개별 변수를 추가해 주었다.
- 상관관계 분석, 차원 축소 등 다양한 통계적 기법을 적용하여 의미있는 변수를 추출했습니다
- Shift 변수는 각 변수마다 24개의 새로운 변수를 생성하기 때문에, 비트 코인 종가와 상관 관계가 높은 변수에 대해서만 생성한 다. 이를 위해 CCF(Cross-Correlation Function) 플롯을 사용하여 비트 코인 종가( close )와 각 변수 간의 상관성을 분석 통해 주요 변수 선정
- 논리적 문제해결 방식
- EDA를 통해 비트코인 데이터는 가격 급등락으로 인해 다수의 이상치를 포함하고 있다는 사실을 확인하였다. 그러나 아무 생각없이 전처리하지 않고, 이러한 이상치는 데이터의 중요한 특징을 담고 있을 가능성이 있기 때문에, 삭제하거나 변환하지 않고 사용하였다.
- 이상치를 처리하고자 seasonal_decompose를 활용한 잔차 기반 이상치 판별 방법과 IsolationForest 알고리즘을 적용해보았지만 처리 기준과 방법을 명확히 정의하는 데에는 한계가 있었다.
-
처음에는 트리 기반 모델을 사용할 계획이었기 때문에 일반적으로 스케일링이 필요 없다고 판단하였으나 다음 세 가지 이유로 MinMax-Scaling을 적용하였다. (1) 결측치 대체: 결측치를 -999로 대체하기 위해서는 각 변수의 범위가 999를 초과하지 않아야 한다. (2) 데이터 일관성 유지: 훈련 데이터와 테스트 데이터 간에 변수의 분포 범위가 다를 경우 모델의 성능이 저하될 수 있다. (3) 데이터 분포 유지: Standardization를 사용하면 훈련 데이터와 테스트 데이터의 범위 차이로 인해 값의 분포가 크게 달라질 수 있다. 따라서 MinMax Scaling을 사용해 일관된 스케일링을 제공하고자 하였다.
- 따라서 이상치를 변환하거나 삭제하는 대신, 로그 변환을 통해 이상치의 영향을 감소시키고, 데이터 범위를 균등화 하기로 하였다. 최소값이 0을 초과하며 훈련 데이터와 테스트 데이터 간 분포의 일관성을 높일 필요가 있는 변수들을 선정해 로그 변환을 적용하였다.
- 모델 학습을 시킨 결과 성능이 매우 낮아, 단순 예측이 아닌 상승/하락 확률 예측으로 전환
-
기존에 생성한 데이터프레임과 PCA에서 만들어진 데이터프레임을 동시에 활용하고자 하였으나 변수의 개수가 너무 많았다. 따라서 두 데이터프레임을 효과적으로 결합하기 위해 0과 3을 잘 예측하는 모델(XGBoost)과 비교적 높은 Accuracy를 보이는 모델(CatBoost, LGBM)을 각 데이터 프레임에 적용하였다. 각 모델에서 변수 중요도 상위 20개를 선정하여 변수명을 가져왔고, 이를 통해 두 데이터프레임에서 각각 60개 정도의 변수를 선택하였다. 선택된 변수만을 가지고 있는 두 데이터프레임과 기존에 예측된 상승/하락 확률을 결합하여 데이터의 차원을 줄이면서도 중요한 정보를 유지할 수 있었다.
-
PCA와 raw 데이터의 장점을 결합한 하이브리드 데이터셋 구축
- 다양한 거래소 데이터의 특성을 고려한 가중치 부여 방식 도입
- 시행착오를 통한 학습
- 0,3 클래스 예측 성능 향상을 위해 다양한 접근을 시도했습니다:
- 데이터 증강 실험과 그 한계 인식
- 모델 앙상블을 통한 예측 성능 개선
- Cross-validation 도입으로 모델 안정성 확보
- 지속적인 개선과 혁신
- Public/Private 점수 간 차이 발생 원인을 분석하고 대응 방안을 마련했습니다
- 팀원들의 다양한 아이디어를 실험하고 검증하는 과정을 통해 최적의 해결책을 도출했습니다
- 프로젝트 진행 중 발견된 문제점들을 다음 프로젝트에 반영할 수 있도록 정리했습니다
이러한 경험을 통해 우리 팀은:
- 복잡한 문제를 체계적으로 분해하고 해결하는 능력
- 효율적인 협업과 소통 능력
- 실패를 두려워하지 않는 도전 정신
- 지속적인 개선을 추구하는 자세
책