Google Colab 유료 체험기
데이콘 2024 제4회 K-water AI 경진대회에 하며 문제점들이 생겼다.
원래는 GPU서버를 대여하여 사용하고 있었는데 그게 없어지다 보니까 여러 방면으로 문제가 생겼고 그걸 해결해보았다.
코랩 메모리가 터짐
EDA하기전에 일단 베이스라인 코드부터 돌려보려고 했다. 근데 메모리가 부족해서 터졌다.
GPU서버가 없어서 여간 귀찮은 게 아니다.
뭐 한번 경험해보고도 싶었으니까 Colab Pro를 한번 구독해봤다. 차피 10달러밖에 안하니까.
GPU성능이 A100 GPU > L4 GPU > T4 GPU라고 한다.
| 특성 | A100 GPU | L4 GPU | T4 GPU | CPU | TPU v2-8 |
|---|---|---|---|---|---|
| 상대적 연산 성능 | 최상 (100%) | 높음 (70%) | 중간 (40%) | 낮음 (10%) | 높음 (65%) |
| VRAM/메모리 | 40GB | 24GB | 16GB | 12.7GB | 8GB/코어 |
| 주요 용도 | 대규모 딥러닝 배치 트레이닝 |
중규모 ML 추론 작업 |
기본 ML 작업 프로토타이핑 |
데이터 전처리 간단한 분석 |
TPU 최적화 모델 TensorFlow |
| 사용 가능 버전 | Pro/Pro+ | Pro/Pro+ | 무료/Pro/Pro+ | 무료/Pro/Pro+ | 무료/Pro/Pro+ |
| 시간당 컴퓨팅 단위 소비 |
12.0 | 8.0 | 4.0 | 1.0 | 10.0 |
| 가용성 | 낮음 | 중간 | 높음 | 매우 높음 | 중간 |
| 제약사항 | 과다사용시 일시적 제한 |
리소스 제한 있음 |
12시간 연속 사용 |
제한 거의 없음 | TensorFlow 필수 |
| 최대 세션 시간 | 24시간 | 24시간 | 12시간 | 12시간 | 24시간 |
| 적합한 작업 | • 대규모 모델 학습 • 복잡한 배치 처리 • 고성능 요구 작업 |
• 중간 규모 학습 • 일반적 ML 작업 • 추론 작업 |
• 작은 모델 학습 • 프로토타입 • 기본 ML 작업 |
• 데이터 전처리 • EDA • 가벼운 작업 |
• TPU 최적화 모델 • TensorFlow 작업 • 분산 학습 |
뭐, 대충 위의 표대로 라는데 약간의 다른게 있긴하다. 지금 A100 시간당 컴퓨팅 단위 소비 8.5정도 던데 뭐 바꼈나? 어쨌든 대충 위와 비슷하다.
무료버전에서는 T4 만 사용 가능하고 그마저도 리소스를 많이 사용하면 cpu로 사용해야 한다.
우선 L4로 바꿔서 돌렸다. 음 이것도 터졌다.
마지막 A100 GPU다. 이것도 터지면 난 베이스라인조차 돌릴 수도 없다. BATCH_SIZE를 줄이면 돌아가긴 하겠지만 아무래도 성능이 떨어질테니까.
마지막 A100 GPU로 돌린 결과는
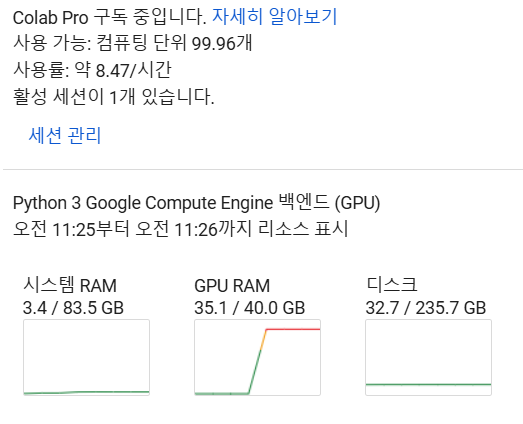
겨우겨우 산 것 같다. 와 근데 A100으로 돌리면 시간당 컴퓨팅 단위 8.5개를 쓰는꼴이니까 12시간돌리면 한달 리소스를 다 쓴다. 최대한 고려하며 써야겠다. GPU서버를 쓰다가 없어지니까 비로소 소중함을 느낀다. 300만원짜리 헤드셋으로 음악을 듣다가 만오천원짜리 이어폰으로 음악을 듣는 느낌. 갑자기 그래픽카드를 막 사고싶고 그러네.
구글 드라이브에 데이터셋이 안 들어감
문제가 생겼다. 구글 드라이브에 전체 데이터셋이 안 들어간다.
너무 파일의 양이 많아 500개이상 넣으면 렉걸려서 안들어간다. 이걸 하나하나 수동으로 넣을 수도 없고..
어케할까 하다가 캠퍼분이 압축된 파일을 구글드라이브에 넣고 압축해제.ipynb를 이용하라고 했다. 그렇게해서 겨우겨우 베이스라인을 한번 돌리긴 했다.
근데 이제 또 다시 코드를 수정해야 하는데 또 기나긴 데이터 로드 시간을 버틸 수가 없을 것 같았다. 게다가 구글 드라이브가 렉이 심하게 걸리고 너어어무 느리다. 아니 Google의 기술력이 이것밖에 안된다고?
그래서 또 고민에 빠졌다. 이 문제를 해결하고 싶은데 당장 나에게 좋은 로컬환경이 주어진 것도 아니고. 근데 어차피 항상 좋은 장비만 가지고 할 순 없으니까.
기존에 과제나 프로젝트에서 데이터셋을 다운로드받을때 wget을 통해 s3서버에서 가져온 기억이 났다. 그래서 나도 aws s3에 데이터셋을 넣고 불러오는 형식으로 쓸까.. 하다가 Claude가 Kaggle에 비슷한 기능이 있다고 추천해줘서 시도중이다.
Kaggle을 이용해 데이터셋 다운로드 하는 법
- 상단 메뉴 Dara -> New Dataset
- dataset을 .zip 파일로 압축해서 업로드고 Create 버튼 클릭. (압축안되어있으면 업로드 안댐)
- 상단 프로필 -> Settings -> Account -> Create New Token 클릭하여 .json 파일 발급
그 다음 코드로 돌아와서 아래 수정해서 코드입력하고 .json파일 첨부하면 구글드라이브보다 빠르게 데이터셋을 로드할 수 있다.
# 1. API 설치 및 설정
!pip install --upgrade --force-reinstall --no-deps kaggle
from google.colab import files
uploaded = files.upload() # kaggle.json 파일 업로드
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
# 2. 데이터셋 다운로드 및 압축 해제
!kaggle datasets download -d irondragon/kwater-data
# 예: !kaggle datasets download -d yourusername/kwater-anomaly-detection
# 압축 해제
!unzip kwater-data.zip -d /content/data
# 3. 데이터 로드
import pandas as pd
df_A = pd.read_csv("/content/data/train/TRAIN_A.csv")
df_B = pd.read_csv("/content/data/train/TRAIN_B.csv")
print("데이터 로드 완료!")
print(f"TRAIN_A shape: {df_A.shape}")
print(f"TRAIN_B shape: {df_B.shape}")
마무리하며
파일형식도 다양하게 가능하니 나중에 AI 프로젝트할때 유용하게 사용 가능할 것 같다.
- Kaggle의 데이터셋 크기 제한
- 전체 저장 공간: 계정당 100GB 제한
- 개별 파일 크기: 최대 10GB
- 용도 제한
- 개인/연구/교육 목적은 괜찮음
- 상업적 사용은 약관 확인 필요
- 웹 서비스의 메인 스토리지로 사용하는 것은 권장되지 않음
장점:
- 빠른 설정 가능 (AWS RDS 설정보다 훨씬 간단)
- 비용 없음
- 높은 다운로드 속도
- 팀원들과 쉽게 공유 가능
지원되는 파일 형식:
- 이미지 (jpg, png, gif 등)
- 비디오 (mp4, avi 등)
- 텍스트 파일
- CSV, Excel 파일
- 압축 파일 (zip)
- 음성 파일 (mp3, wav)