생성모델
test
생성모델
지도 학습 (Supervised Learning)
-
data: x=input, y=output
-
목표: x를 y로 매핑하는 함수를 학습
비지도 학습 (Unsupervised Learning)
-
data: x=input
-
목표: 데이터의 숨겨진 구조나 패턴 학습
생성 모델 (Generative Models)
-
data: x=input, y=output OR x=input
- 목표: 관찰된 샘플로부터 데이터의 분포를 표현하는 모델을 학습
- 예시: 밀도 추정, 샘플 생성

생성모델의 개요
- 생성 모델은 관찰된 샘플들을 바탕으로 데이터의 분포를 표현하는 모델을 학습, 데이터의 숨겨진 구조나 기저에 있는 패턴을 포착
Advantages
-
Generation (새로운 데이터 샘플 생성)
-
Debias (데이터의 편향을 감지하고 수정)
-
Outlier detection (정상적인 패턴에서 벗어난 데이터 찾기)
-
Classification (데이터를 여러 범주로 나눌 수 있음)
-
Segmentation (데이터를 의미 있는 부분으로 나눌 수 있음)
Gaussian Mixture Models (GMM)의 개요
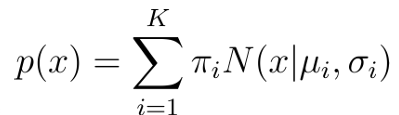
p(x): 전체 확률 분포 K: 가우시안 분포(클러스터)의 수 πi: i번째 가우시안의 가중치 (모든 πi의 합은 1) N(x|μi, σi): i번째 가우시안 분포 (평균 μi, 표준편차 σi)
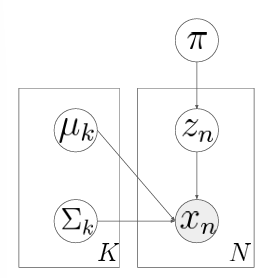
ㅠ (파이): 각 클러스터의 가중치(확률)를 나타냅니다. uk (뮤): k번째 클러스터의 평균을 나타냅니다. Ek (시그마): k번째 클러스터의 공분산 행렬을 나타냅니다. zn: n번째 데이터 포인트가 속한 클러스터를 나타내는 잠재 변수입니다. xn: n번째 관측 데이터 포인트입니다. K: 클러스터의 총 개수입니다. N: 데이터 포인트의 총 개수입니다.